上一篇
分布式服务器操作系统教程
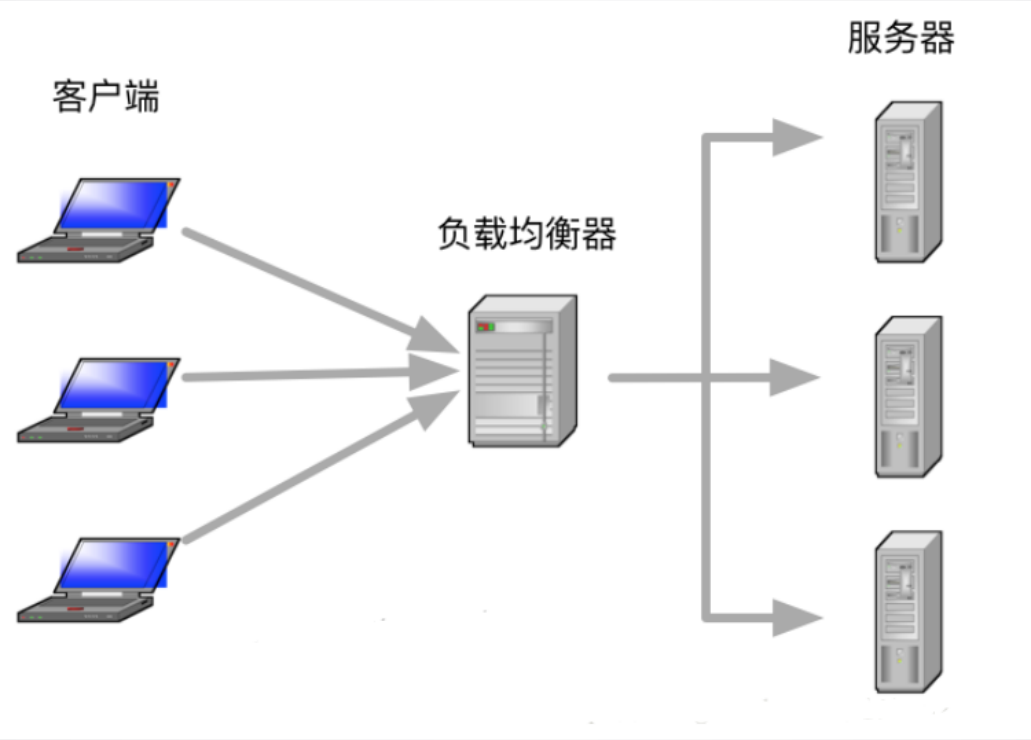
分布式服务器操作系统通过资源池化、任务调度等技术实现多节点协同,具备高可用性、可扩展性,支撑云计算等大规模服务
分布式服务器操作系统是构建大规模分布式系统的基石,其设计理念与实现方式直接影响系统的可靠性、扩展性和性能,本文将从基础概念到实践案例,系统化解析分布式服务器操作系统的核心知识体系。
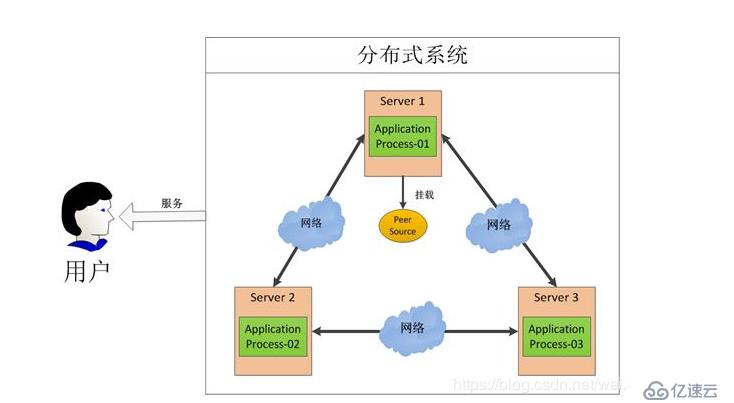
分布式系统基础认知
分布式服务器操作系统需解决的核心问题包括:
- 节点通信:建立高效的进程间通信机制
- 状态管理:维护分布式一致性与数据完整性
- 容错机制:应对网络分区与节点故障
- 资源调度:实现跨节点的负载均衡
典型分布式系统架构对比表:

| 架构类型 | 适用场景 | 代表系统 | 特点 |
|---|---|---|---|
| 主从复制 | 读写分离业务 | MySQL Cluster | 强一致性读,异步复制 |
| 对等网络 | 高可用服务 | Cassandra | 无单点故障,最终一致性 |
| 微服务架构 | 云原生应用 | Spring Cloud | 独立部署,服务发现机制 |
| 分布式流处理 | 实时数据处理 | Kafka Streams | 高吞吐量,低延迟 |
核心技术组件解析
分布式协调服务
- ZooKeeper:基于ZAB协议实现分布式锁和配置管理
- etcd:采用Raft算法,支持强一致性键值存储
- Consul:集成服务发现与健康检查功能
关键参数对比表:
| 特性 | ZooKeeper | etcd | Consul |
|---|---|---|---|
| 一致性协议 | ZAB | Raft | Raft |
| 数据模型 | 树形结构 | 键值对 | 键值对+服务 |
| 选举超时 | 200-300ms | 1-2s | 1-2s |
| 最佳场景 | 配置中心 | 服务发现 | 混合型应用 |
分布式存储系统
- HDFS:块存储+主备架构,适合大数据批处理
- Ceph:对象/块/文件统一存储,支持CRUSH算法
- GlusterFS:无元数据服务器架构,依赖散列分布
存储特性对比表:
| 指标 | HDFS | Ceph | GlusterFS |
|---|---|---|---|
| 元数据服务 | NameNode单点 | MON集群 | 无独立服务 |
| 扩展方式 | 横向扩容 | 动态扩展 | 自动平衡 |
| 数据恢复 | 手动干预 | 自动修复 | 客户端计算 |
| 适用场景 | 离线分析 | 云存储 | 临时存储 |
分布式通信框架
- gRPC:基于HTTP/2的高性能RPC框架
- Thrift:跨语言服务定义框架
- Dubbo:阿里系RPC框架,内置服务治理
通信协议特性对比:
| 特性 | gRPC | Thrift | Dubbo |
|---|---|---|---|
| 传输协议 | HTTP/2 | 自定义二进制 | Netty |
| IDEL编码 | Protobuf | Thrift Codec | Hessian |
| 服务发现 | DNS/Consul | 自定义 | ZooKeeper |
| 流量控制 | 熔断机制 | 超时重试 | 动态降级 |
生产环境实践指南
集群部署流程
# 以Kubernetes为例的部署步骤
1. 初始化控制平面:
kubeadm init --pod-network-cidr=10.244.0.0/16
2. 配置网络插件:
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
3. 创建存储类:
kubectl create storageclass ceph-sc
--storage-provisioner=ceph.rook.io/ceph
4. 部署StatefulSet:
kubectl apply -f myapp-statefulset.yaml监控体系构建
- Prometheus:时间序列数据库+查询语言
- Grafana:可视化仪表盘
- Alertmanager:告警收敛与路由
- Node Exporter:系统级指标采集
- cAdvisor:容器资源监控
监控指标分类表:
| 类别 | 指标示例 | 阈值建议 |
|---|---|---|
| 节点健康 | CPU使用率/内存占用 | >85%持续1分钟触发 |
| 网络状态 | TCP重传率/带宽利用率 | >15%丢包率告警 |
| 存储性能 | IO延迟/磁盘队列长度 | >10ms延迟持续30秒 |
| 应用层 | QPS/响应时间 | >99%分位值500ms报警 |
典型故障处理方案
网络分区处理流程
- 检测脑裂现象(split-brain)
- 启用仲裁机制(quorum)
- 实施CAP策略选择:
- CP优先:暂停写操作保证一致性
- AP优先:允许临时不一致提升可用性
- 日志补偿机制恢复数据
数据不一致修复
- 事件溯源:通过Kafka重放消息
- 版本向量:使用逻辑时钟同步状态
- 冲突检测:基于MVCC实现乐观锁
- CRDT算法:收敛因果顺序解决冲突
安全加固措施
- TLS双向认证:配置证书验证通信双方身份
- RBAC权限模型:基于角色的访问控制策略
- 审计日志:记录所有敏感操作轨迹
- 秘钥管理:集成Vault/KMS加密服务
- 网络隔离:使用Calico/Cilium实现零信任网络
FAQs
Q1:如何在CAP定理中进行取舍?
A1:根据业务需求选择优先级:金融交易系统应优先保证一致性(CP),社交媒体可接受最终一致性(AP),实际工程中常采用BASE原则(基本可用、软状态、最终一致)进行折中。
Q2:如何处理节点永久故障?
A2:实施三步恢复策略:1) 标记失效节点并移除集群;2) 数据副本重新分布;3) 新节点加入时执行数据同步,建议配合哨兵机制(Sentinel)实现自动