上一篇
光学文字识别软件ocr
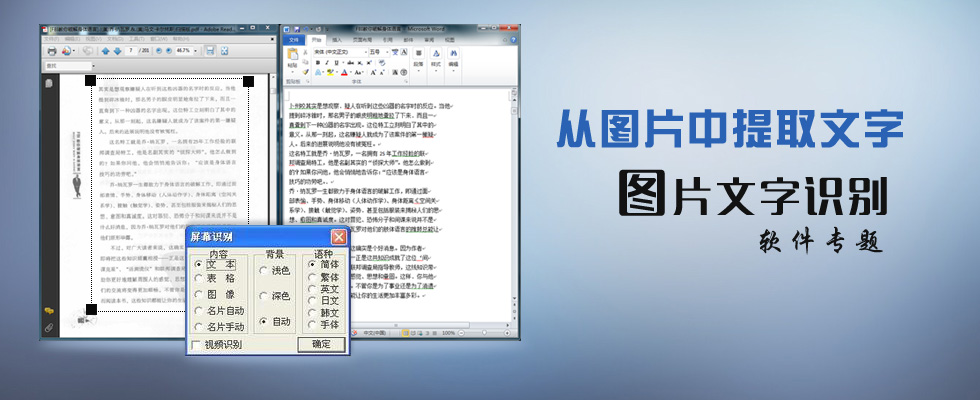
光学字符识别(OCR)技术通过图像处理与特征分析,将纸质文档、图片中的文字转化为可编辑电子文本,支持多语言识别,广泛应用于文档数字化、车牌识别、证件信息提取等领域,显著提升文字处理效率
光学文字识别软件(OCR)
光学文字识别软件(Optical Character Recognition,简称 OCR)是一种利用光学技术对文字进行识别并转化为可编辑文本格式的软件,它通过扫描文档或图像中的文字,分析其形状、结构等特征,将其转换为计算机能够理解和处理的字符编码,从而实现文字的数字化录入与编辑。

OCR 的主要功能
| 功能分类 | 具体功能描述 |
|---|---|
| 文字识别 | 能够精准识别各种印刷体文字,包括书籍、报纸、杂志、票据等上的文字内容,将其转化为可编辑的文本,如常见的 TXT、DOC、RTF 等格式,方便用户进行复制、粘贴、修改等操作。 |
| 多语言支持 | 具备对多种语言文字的识别能力,除了简体中文、繁体中文外,还涵盖英语、日语、韩语、法语、德语等众多国际常用语言,满足不同用户在处理多语言文档时的需求。 |
| 图像处理 | 在识别之前,可对输入的图像进行预处理,如自动校正倾斜角度、去除噪点、调整对比度与亮度等,以提高文字识别的准确性,还能对彩色图像进行色彩空间转换,适应不同的识别场景。 |
| 格式转换 | 不仅可以将图像中的文字提取出来,还能在一定程度上保留原始文档的格式信息,如段落排版、字体样式、表格结构等,将其转换为对应的电子文档格式,减少用户重新排版的工作量。 |
| 批量处理 | 支持对大量文档或图像进行批量文字识别处理,用户只需将多个文件添加到处理列表中,软件即可按照设定依次进行识别转换,大大提高了工作效率,尤其适用于处理大量文档资料的情况。 |
OCR 的应用场景
- 文档数字化:对于图书馆、档案馆、企业档案室等拥有大量纸质文档的机构,OCR 软件可将纸质书籍、档案、合同等快速转化为电子文本,方便存储、检索与共享,有助于构建数字资源库,提升信息管理效率。
- 办公自动化:在日常办公中,遇到纸质文件需要录入成电子文档时,如处理邮件中的纸质附件、扫描版合同条款等,OCR 软件能迅速将文字提取出来,避免人工逐字录入的繁琐,提高办公效率,结合文档管理系统,可实现文档的自动化分类与存储。
- 移动应用:在移动设备上,OCR 应用也极为广泛,通过手机拍照扫描名片,可瞬间将名片上的信息转化为电子联系人资料并存入通讯录;拍摄纸质笔记或图片中的文字,能快速转为可编辑文本,方便整理与分享,随时随地满足用户的信息数字化需求。
- 无障碍服务:对于视力障碍人士,OCR 技术结合屏幕朗读软件,可将扫描的书籍、文件等转化为语音输出,帮助他们获取文字信息,提升信息无障碍程度,促进社会包容性发展。
OCR 的技术原理
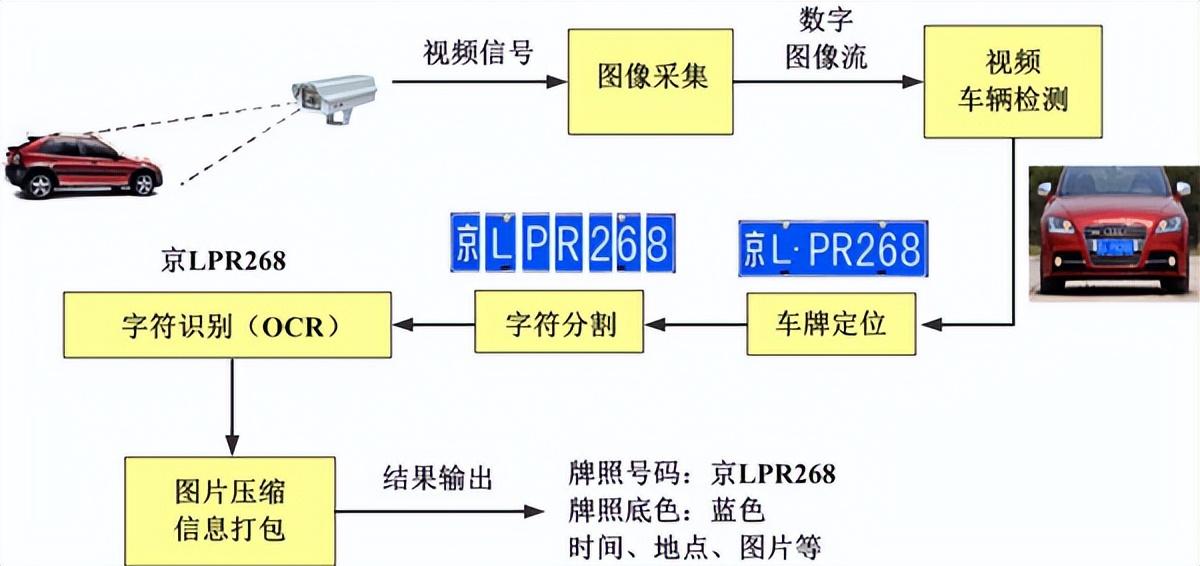
- 图像预处理:首先对输入的图像进行灰度化处理,将彩色图像转化为灰度图像,减少数据量并简化后续计算,然后进行二值化操作,将图像中的像素分为黑(文字)和白(背景)两类,使文字轮廓更加清晰,接着进行去噪处理,去除图像中的干扰点,如污迹、折痕等,还会进行倾斜校正,通过检测图像中文字的倾斜角度,对图像进行旋转调整,确保文字处于水平或垂直方向,便于后续识别。
- 文字检测:运用各种算法来定位图像中的文字区域,基于连通域的方法通过检测像素之间的连通性,将属于同一文字字符的像素聚类为一个连通域,从而确定文字的位置和范围,而基于深度学习的文字检测算法,如卷积神经网络(CNN),能够学习到文字的特征模式,更准确地检测出复杂背景下的文字区域,即使文字存在变形、遮挡等情况也能较好应对。
- 字符识别:对于检测到的文字区域,将其分割为单个字符后,使用模式匹配或深度学习模型进行识别,传统的模式匹配方法基于字符的形状特征,将待识别字符与预定义的字符模板进行比对,找到最相似的模板作为识别结果,而深度学习模型,如循环神经网络(RNN)及其变体长短时记忆网络(LSTM)或Transformer架构,通过对大量字符样本的学习,能够自动提取字符的特征,实现高精度的字符识别,尤其对一些生僻字、异体字等具有更好的适应性。
- 后处理:识别结果可能会存在一些错误或不完整的地方,后处理阶段会进行校正,根据语言模型对识别出的文本进行语法和词法检查,纠正一些明显的拼写错误或不符合语言习惯的词汇组合,还会对文本的格式进行调整,如恢复段落分隔、调整字体大小等,使最终输出的文本更符合阅读和使用习惯。
主流 OCR 软件介绍
| 软件名称 | 特点 |
|---|---|
| ABBYY FineReader | 识别准确率高,尤其在处理复杂格式文档、多语言文档方面表现出色,支持多种输出格式,对表格、图片的还原效果好,并且具备强大的文档编辑与校对功能,适合专业文档处理与大规模文档数字化项目。 |
| Adobe Acrobat DC | 与 Adobe 系列软件生态融合良好,可直接在 PDF 文件中进行文字识别,识别后能保持原文档的排版与样式,方便对 PDF 文档进行编辑修改,广泛应用于出版、印刷、商务等领域的文档处理。 |
| Google Docs OCR | 依托 Google 的强大云计算能力,识别速度较快,支持多种语言,能很好地处理网页截图、照片中的文字等,并且与 Google 文档无缝衔接,方便用户在线协作编辑识别后的文档,适合个人和小团队日常文档处理与分享。 |
| Tesseract | 开源免费的 OCR 引擎,具有较高的灵活性,可在不同的操作系统和开发环境中使用,虽然在默认设置下识别准确率相对商业软件可能稍低,但通过训练和优化模型,能够适应特定领域或特殊字体的文字识别需求,受到开发者社区和一些对成本敏感用户的欢迎。 |
| Microsoft OneNote | 在微软的笔记应用 OneNote 中内置 OCR 功能,方便用户在记录笔记时对插入的图片、扫描件等进行文字识别,识别结果直接融入笔记内容,可进行标注、整理等操作,与其他 Office 应用协同工作,适合学生、教师等在日常学习与教学过程中使用。 |
相关问题与解答
问题 1:OCR 软件在处理手写体文字时效果如何?
答:目前大多数 OCR 软件对手写体文字的识别效果相对印刷体文字要差一些,这是因为手写体文字在笔画形态、书写风格、字间间距等方面存在较大的随意性和差异性,一些先进的 OCR 技术正在不断改进对手写体的识别能力,通过深度学习算法训练专门的手写体识别模型,能够在一定程度上对手写数字、字母以及较为规范的手写汉字进行识别,但对于潦草、连笔严重的手写体,仍然可能出现较多识别错误,如果需要准确识别手写体文字,通常需要对 OCR 软件进行针对性的训练,或者采用人工辅助校对的方式来提高准确性。
问题 2:如何提高 OCR 软件的识别准确率?
答:有以下几种方法可以提高 OCR 软件的识别准确率,确保输入图像的质量,在扫描或拍摄文档时,尽量保证文字清晰、光照均匀、无阴影和模糊现象,纸张平整无褶皱,选择合适的 OCR 软件及其参数设置,不同的软件在处理不同类型文档时可能有优劣之分,根据文档的语言、格式等特点选择最适合的 OCR 工具,并调整其图像预处理、字符识别等相关参数,对 OCR 软件进行训练,如果有大量特定领域或特定字体风格的文档需要处理,可以收集这些文档的样本数据,对 OCR 软件进行定制化训练,使其更适应这类文字的识别,在识别结果后处理阶段,利用语言模型、词典等进行语法和词法检查,纠正一些明显的错误,也可以有效提高整体的识别准确率