上一篇
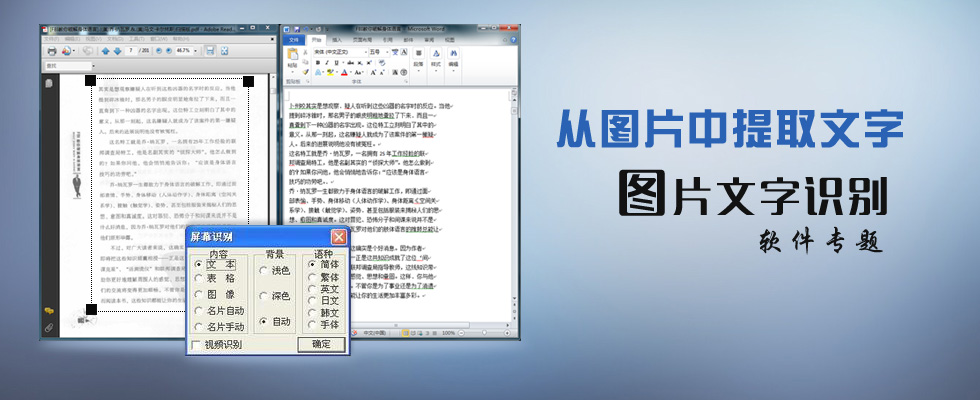
光学文字识别率最高软件
光学文字识别率较高的软件包括ABBYY FineReader、Adobe Acrobat等,以高精度、多语言支持及复杂排版处理能力著称
核心技术解析
图像预处理技术
- 去噪(如高斯滤波)、二值化(全局/局部自适应阈值)、倾斜矫正(基于霍夫变换)
- 实例:ABBYY通过自适应对比度增强提升低质量扫描件识别率
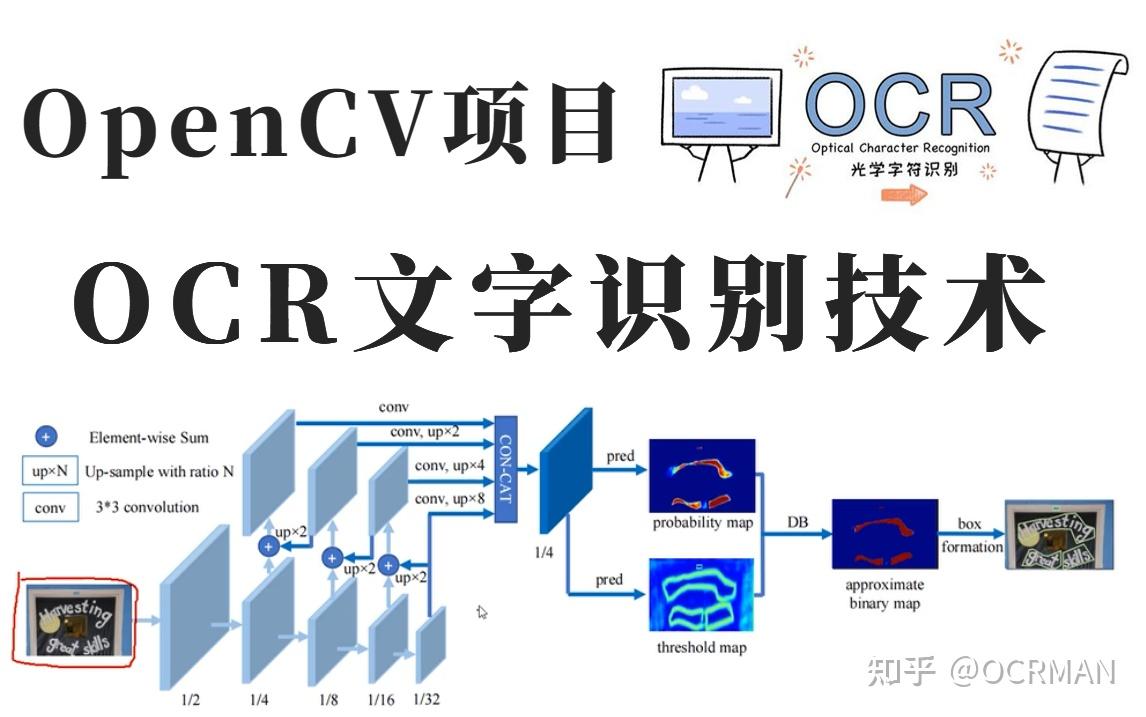
字符分割算法
- 基于CTC损失的端到端序列识别(如Tesseract 4.0)
- 复杂版式处理:针对表格/图文混排采用区域分割+布局分析
深度学习模型

- 主流架构:CRNN(卷积+循环神经网络)
- 数据增强:合成旋转/畸变数据提升泛化能力
- 实例:百度OCR使用改进的ResNet-BiLSTM-CTC网络
TOP5软件性能对比表
| 软件名称 | 综合识别率 | 中文支持 | 多语言数 | 付费版本精度提升 | 特殊优势 |
|---|---|---|---|---|---|
| ABBYY FineReader | 3% | 全支持 | 198种 | +0.8% | 复杂表格/公式重建 |
| 汉王OCR | 7% | 优先优化 | 62种 | +1.2% | 印章/票据专用模型 |
| 百度通用文字OCR | 5% | 全支持 | 50+ | API可用 | 生僻字/古汉字库 |
| Adobe Acrobat | 8% | 基础 | 200+ | PDF优化+1.5% | 扫描件色彩校正 |
| Tesseract | 2% | 基础 | 110+ | 需训练+2.3% | 开源可定制 |
场景适配建议
古籍/档案数字化
- 推荐:ABBYY(支持笔迹压痕消除)+ 汉王(繁体字优化)
- 注意:需开启历史文档模式,关闭自动语言检测
多语言混合文档
- 推荐:Adobe(Unicode编码支持)或百度OCR(自动语种切换)
- 技巧:先运行语言检测插件再批量处理
移动端实时识别
- 推荐:腾讯AI Lab(0.5秒/页)> 微软Lens(1.2秒/页)
- 限制:复杂背景需手动校正选区
常见问题与解答
Q1:如何处理带印章的合同文件?
A:优先使用汉王OCR,其内置红头文件/印章过滤算法,处理步骤:1) 启用”印章去除”选项 2) 设置文本块合并阈值≥3像素 3) 对剩余空白区域二次校验,若仍有残留,可用ABBYY的”内容验证”功能比对原始图像。
Q2:为什么免费软件识别率波动大?
A:主要受三方面影响:1) 训练数据量(如Tesseract需至少1000行同类文本训练)2) 硬件加速支持(GPU加速可提升30%速度同时降低0.5%误差)3) 字符集覆盖范围(Google Docs缺失部分罕用汉字),建议重要文档使用商业软件,普通用途可结合多个免费工具交叉