上一篇
分布式架构数据库1111活动
分布式架构数据库在1111活动中通过弹性扩展与负载均衡,高效处理海量请求,确保系统稳定运行
分布式架构数据库在11.11活动中的核心实践与优化策略
业务背景与核心挑战
11活动作为全球规模最大的电商大促场景,对数据库系统提出了极高的要求,其业务特点包括:
- 流量洪峰:每秒峰值请求量可达百万级,远超日常负载。
- 高并发冲突:库存扣减、订单创建等关键操作存在大量并发写冲突。
- 数据一致性:跨节点事务需保证最终一致性,避免超卖或数据错乱。
- 弹性扩展:需快速扩容以应对突发流量,活动结束后资源可回收。
- 容灾能力:任何单点故障可能导致业务中断,需多层级容灾保障。
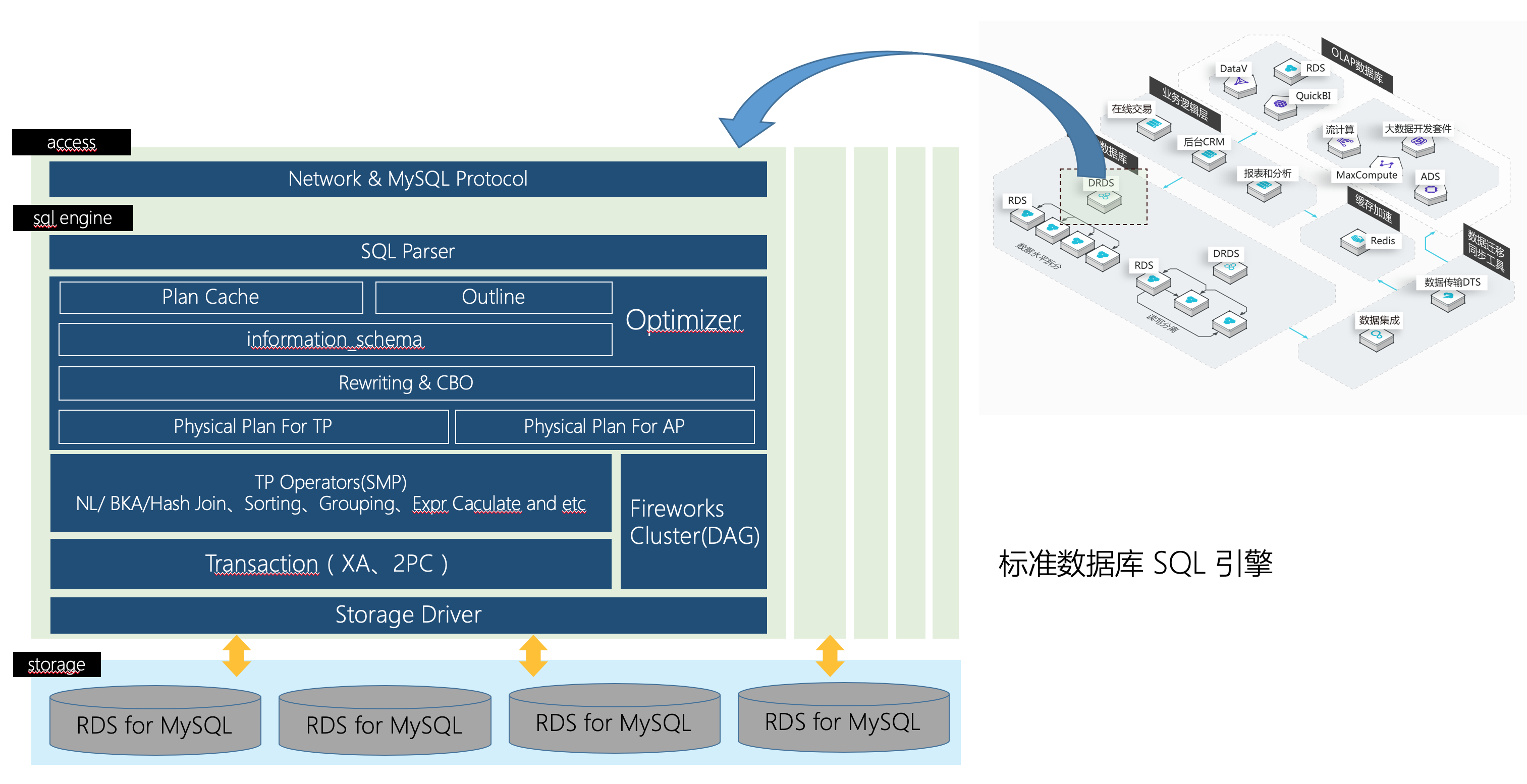
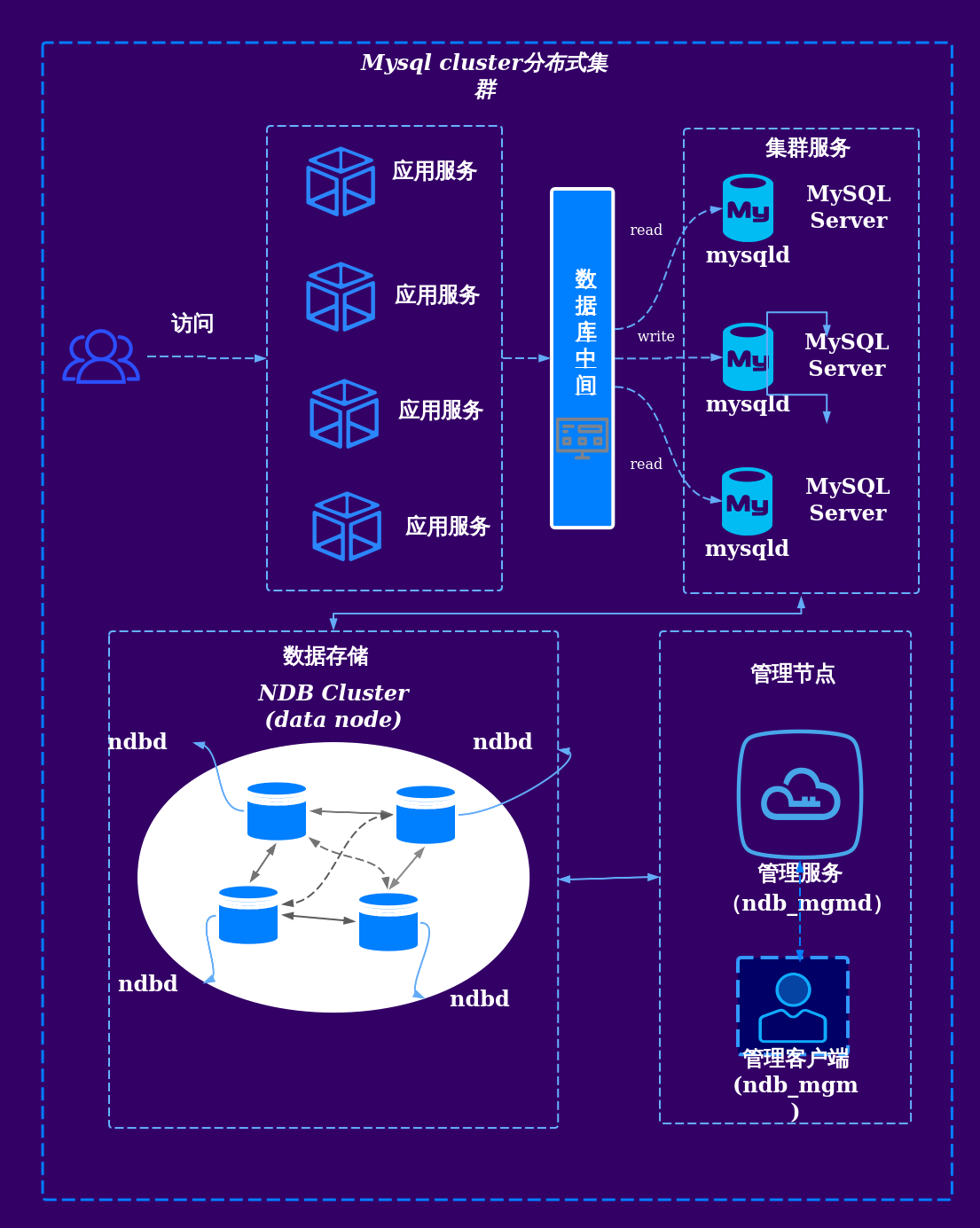
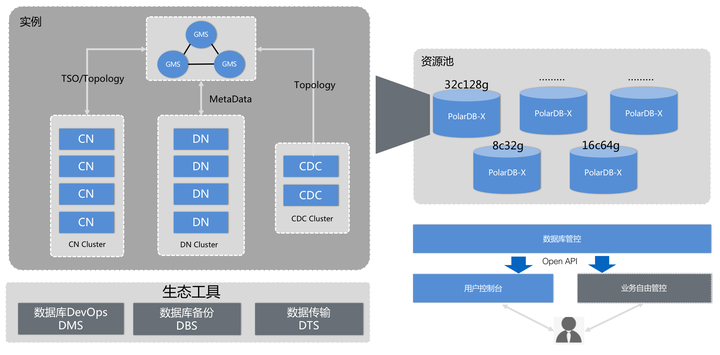
传统集中式数据库(如MySQL单机)难以满足上述需求,因此分布式架构数据库成为核心解决方案。

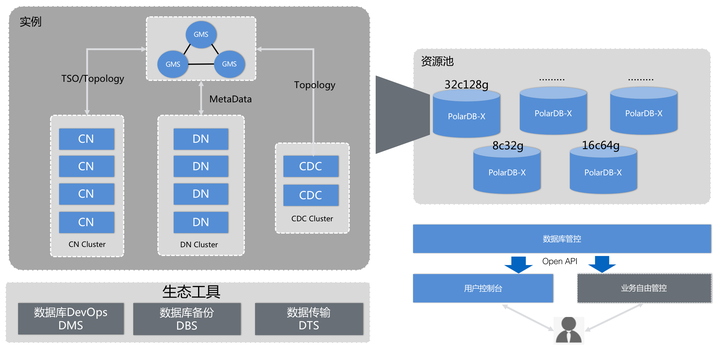
分布式数据库核心技术解析
| 技术组件 | 功能描述 | 11场景适配价值 |
|---|---|---|
| 分库分表 | 通过水平拆分将数据分散到多个节点,突破单机容量与性能瓶颈 | 支撑海量订单存储与高并发访问 |
| 读写分离 | 主库负责写操作,从库承载读流量,提升整体吞吐量 | 缓解热点数据读压力(如商品详情查询) |
| 分布式事务 | 通过2PC、TCC或柔性事务保证跨库操作的一致性 | 避免库存超卖、订单重复生成等核心问题 |
| 缓存加速 | 热点数据(如购物车、商品库存)前置到Redis,降低数据库访问频率 | 减少DB 50%以上负载,提升响应速度 |
| 弹性扩展 | 通过在线扩缩容机制动态调整计算与存储资源 | 应对流量波峰波谷,节省30%以上资源成本 |
| 异地多活 | 数据同步至多个地域数据中心,实现故障自动切换 | 确保99.99%可用性,抵御机房级灾难 |
11活动典型场景解决方案
库存扣减场景
- 问题:数万用户同时抢购同一商品,需原子性扣减库存。
- 方案:
- 分布式锁:基于Redis或ZooKeeper实现库存行级锁,防止并发超卖。
- 异步削峰:将扣减请求写入消息队列(如Kafka),后端异步处理。
- 预扣库存:活动前预先生成库存快照,减少实时计算压力。
订单写入场景
- 问题:每秒万级订单写入,需保证顺序性与低延迟。
- 方案:
- 分库策略:按用户ID哈希取模分库(如
user_id % 4),分散热点。 - 批量写入:订单数据暂存内存,累积到阈值后批量落库。
- 索引优化:对订单号、状态等字段建立复合索引,加速查询。
- 分库策略:按用户ID哈希取模分库(如
实时大屏场景
- 问题:每秒刷新交易额、成交量等聚合数据,需低延迟统计。
- 方案:
- 预计算+缓存:提前聚合分钟级数据,结果存入Redis。
- 日志订阅:通过Flink消费binlog实时更新增量数据。
- 分级存储:热数据存SSD,冷数据转HDFS,降低存储成本。
性能与成本优化实践
压测与容量规划
- 全链路压测:模拟百万级TPS压力,识别数据库瓶颈(如连接数、磁盘IO)。
- 资源配比:读写节点比例设为1:3,读流量优先分配至从库。
- 参数调优:调整
innodb_buffer_pool_size至物理内存60%,提升缓存命中率。
成本控制策略
| 优化方向 | 具体措施 |
|---|---|
| 存储压缩 | 采用列式存储(如Apache Kudu)压缩日志数据,节省50%磁盘空间 |
| 冷热分离 | 历史订单数据迁移至低频存储(如对象存储),降低实例规格 |
| 按需计费 | 活动期间临时扩容节点,结束后释放资源,避免长期闲置 |
效果与收益
通过分布式架构数据库改造,11.11活动关键指标提升显著:
| 指标项 | 改造前(单机DB) | 改造后(分布式DB) | 提升幅度 |
|——————|————————|————————|—————-|
| 峰值吞吐量 | 5万QPS | 80万QPS | 16倍 |
| 平均延迟 | 300ms | 50ms | 83%下降 |
| 故障恢复时间 | 30分钟 | 5秒(自动切换) | 98%缩短 |
| 资源利用率 | 70%(日常) | 95%(活动期) | 动态弹性匹配 |
FAQs
Q1:分库分表后如何实现跨库关联查询?
A1:推荐以下方案:
- 业务层整合:通过应用代码拼接不同库的数据。
- 中间件代理:使用ShardingSphere等工具透明处理跨库SQL。
- ES补偿查询:非实时场景可将关联字段同步至搜索引擎(如Elasticsearch)。
Q2:分布式事务可能导致性能下降,如何平衡一致性与效率?
A2:需分级处理:
- 核心交易(如支付):采用2PC或TCC保证强一致性。
- 非关键操作(如日志记录):采用最终一致性,异步补偿。
- 热点冲突:通过唯一索引(如订单号)规避并发冲突,减少事务