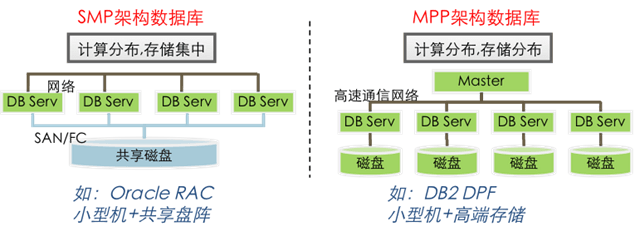
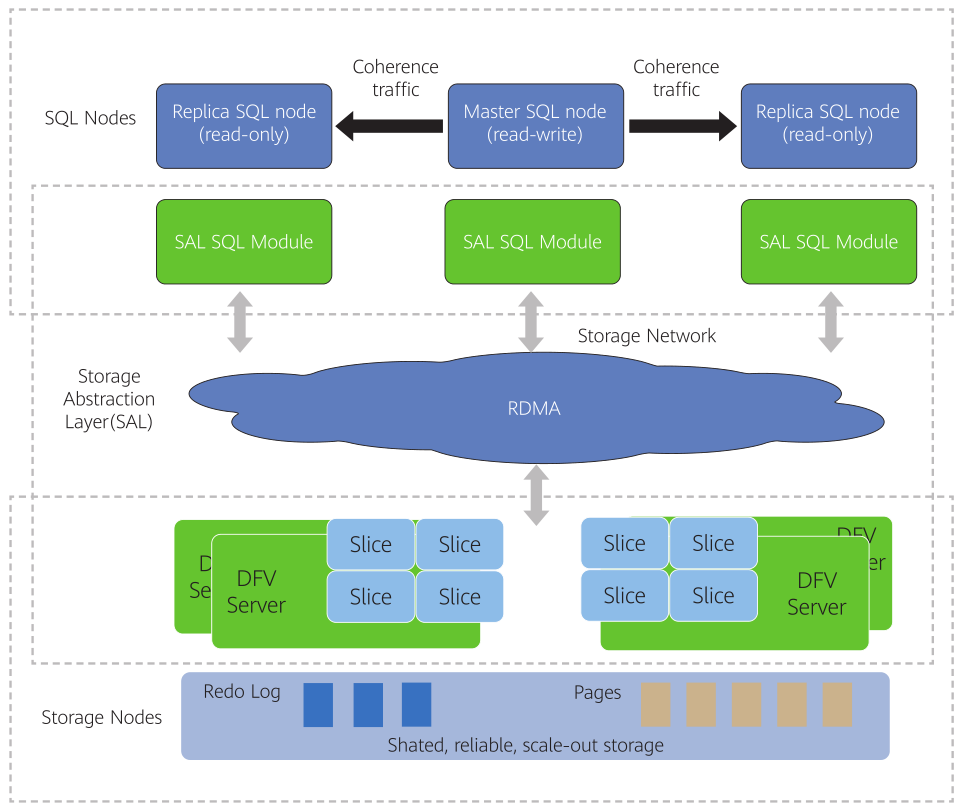
上一篇
分布式数据库 对比
分布式数据库采用 分布式架构,扩展性强、高可用,但一致性与成本挑战大;传统数据库集中式,扩展有限,成本低
分布式数据库核心特性对比与技术解析
分布式数据库分类与基础特性
分布式数据库根据数据模型和技术实现可分为四类:传统关系型分布式数据库(如MySQL Cluster)、NoSQL分布式数据库(如MongoDB、Cassandra)、NewSQL分布式数据库(如CockroachDB、TiDB)、多模分布式数据库(如Couchbase),以下从12个维度进行对比分析:
| 特性维度 | 传统关系型(MySQL Cluster) | NoSQL(MongoDB) | NewSQL(CockroachDB) | 多模数据库(Couchbase) |
|---|---|---|---|---|
| 数据模型 | 结构化表 | JSON/BSON文档 | SQL+ACID事务 | 文档+键值+列族混合 |
| 一致性协议 | 异步复制 | 最终一致性(Tumbstone) | Raft共识算法 | 向量时钟冲突解决 |
| 水平扩展 | 手动分片 | 自动分片(Shard Key) | 透明全局路由 | 动态分区 |
| 事务支持 | 本地ACID事务 | 无事务 | 全局分布式事务 | 受限事务(单文档) |
| CAP定理取舍 | AP优先(网络分区时可用) | P优先(高可用) | CP优先(强一致性) | AP+BP混合模式 |
| 查询语言 | SQL | MongoDB Query Language | PostgreSQL兼容SQL | N1QL(类SQL) |
| 存储引擎 | InnoDB集群 | WiredTiger | RocksDB+Raft日志 | EP-Engine内存存储 |
| 延迟表现 | 10-50ms(跨节点) | <1ms(单节点) | 5-20ms(Paxos优化) | 5-5ms(内存优先) |
| 扩展上限 | 百节点级 | 千节点级 | 理论无限(DNS服务发现) | 千节点级 |
| 运维复杂度 | 高(需管理分片规则) | 中(自动分片) | 低(自动化运维) | 中高(多模管理) |
| 成本模型 | 硬件成本高(SSD优先) | 成本适中(HDD可支撑) | 云原生优化(低成本) | 内存密集型(高成本) |
| 典型场景 | 金融交易核心系统 | 存储 | 云计算全业务支撑 | 游戏实时数据+分析 |
关键技术差异深度解析
- 一致性保障机制
- 传统关系型采用异步复制+主从切换,在网络分区时可能产生数据不一致
- NoSQL普遍采用乐观锁+版本控制(如Cassandra的MD5哈希),牺牲强一致性换取可用性
- NewSQL通过Raft/Paxos协议实现线性一致性,CockroachDB的MVCC版本控制可追溯历史状态
- 多模数据库采用冲突自由复制(CRF)策略,Couchbase通过序列化ID解决并发冲突
- 扩展性实现原理
- MySQL Cluster依赖手动配置分片规则,跨节点JOIN操作性能衰减明显
- MongoDB Sharding自动拆分Chunk,但跨Shard查询需Mongos路由层,存在性能瓶颈
- TiDB采用Raft协议实现计算与存储分离,PD组件动态调度Region分布
- Cassandra通过Consistent Hashing实现无缝扩容,新增节点仅需迁移10%数据
- 事务处理能力
- 传统关系型仅支持本地事务,跨节点事务需两阶段提交(2PC)导致性能下降
- NewSQL通过Percolator事务模型(如CockroachDB)实现全局事务,利用Tombstone标记实现高效冲突检测
- 多模数据库通常限制事务范围,Redis仅支持单键事务,Couchbase提供XA/XD事务但需应用层协调
场景适配性分析
互联网电商场景:推荐使用NoSQL(如Cassandra),其高写入吞吐量(单节点10万+ TPS)适合瞬秒场景,但需接受最终一致性风险,若涉及订单核心交易,应选用NewSQL(如TiDB)保证事务完整性。
物联网时序数据处理:InfluxDB等TSDB更适合,其基于时间分区的存储结构可高效处理每秒百万级写入,但缺乏复杂查询能力,对比而言,TimescaleDB通过PostgreSQL扩展实现SQL分析,但写入性能较原生TSDB下降40%。
混合负载场景:多模数据库(如Couchbase)可同时处理用户画像文档(JSON)、推荐系统向量(BLOB)和实时排行榜(Key-Value),但需为不同数据类型配置独立存储引擎,资源利用率比NewSQL低20-30%。
技术演进趋势
存算分离架构:Snowflake式架构将计算层与存储层解耦,AWS Redshift Spectrum已实现PB级数据即时分析,但带来跨数据中心网络带宽压力。
Serverless化部署:FaunaDB等新型数据库支持按需计费,自动扩缩容响应速度达秒级,但冷启动延迟可能超过传统实例3倍。
AI原生优化:CockroachDB 23.1版本引入向量化执行引擎,复杂查询加速比提升300%,但索引维护开销增加40%。
FAQs
Q1:如何根据业务特征选择分布式数据库?
- 高频写入且容忍短暂不一致:选Cassandra/MongoDB
- 金融级事务+复杂查询:选CockroachDB/TiDB
- 混合数据类型+低延迟:选Couchbase
- 时序数据分析为主:选InfluxDB/TimescaleDB
Q2:分布式数据库相比集中式数据库的主要劣势是什么?
- 运维复杂度指数级上升(如Shard平衡、故障转移)
- 网络延迟导致跨节点查询性能下降(典型增加5-10ms)
- CAP定理限制下的一致性与可用性权衡
- 硬件成本增加30-50%(需SSD/