
上一篇
分布式数据库编译
分布式数据库编译需处理数据分片、节点间协同及容错机制,通过全局查询优化生成跨节点执行计划,结合分布式事务协调与并行计算框架,确保SQL语句高效转化为多节点可执行任务,兼顾数据一致性与计算负载
原理、流程与关键技术解析
分布式数据库编译的核心概念
分布式数据库编译是将用户提交的SQL语句转化为可执行的分布式查询计划的过程,与传统单机数据库不同,分布式数据库需要解决数据分片、节点间通信、容错机制等复杂问题,编译过程需要兼顾执行效率、资源利用率和系统容错能力,其核心目标包括:

- 全局优化:跨多个节点的查询优化
- 执行计划生成:适应分布式架构的物理计划
- 容错处理:节点故障时的自动恢复机制
- 数据本地性:最大化利用本地节点数据
分布式数据库编译流程详解
| 编译阶段 | 核心任务 | 技术难点 |
|---|---|---|
| SQL解析 | 词法分析→语法分析→语义检查 | 支持分布式特有语法(如分片键指定、全局表引用) |
| 逻辑优化 | 谓词下推、视图展开、连接重排序 | 跨分片的数据特性感知优化 |
| 物理优化 | 数据分片定位、执行策略选择(广播/单播)、连接算法决策 | 网络传输成本与计算成本的平衡 |
| 执行计划生成 | 构建分布式执行树(Distributed Execution Plan, DEP) | 多节点并行度控制、中间结果物化策略 |
| 调度优化 | 任务分配到具体节点、资源预估 | 数据倾斜检测与动态负载均衡 |
| 容错处理 | 副本选择、失败恢复策略 | 保证恰好一次语义下的故障恢复 |
SQL解析与逻辑优化
- 分布式语法扩展:支持
PARTITION BY、NODE等分布式特有语法 - 元数据管理:维护全局数据字典,包含分片策略、副本位置等信息
- 全局视图合并:将涉及多个分片的表转换为统一逻辑视图
物理优化关键技术
# 示例:分片感知的连接顺序优化
def optimize_join_order(tables):
# 优先连接数据量小的分片表
tables.sort(key=lambda t: t.fragment_size)
# 调整连接顺序以减少中间结果传输
return tables执行计划生成
- 数据分片定位:通过分片键快速定位目标节点
- 执行模式选择:
- 广播模式:小表全量分发(如JOIN右侧小表)
- 单播模式:按分片键精准路由
- 混合模式:动态选择最优路径
- 中间结果处理:
- 物化策略:内存/磁盘存储选择
- Shuffle优化:减少跨节点数据传输
调度与容错机制
- 两阶段提交协议:保证分布式事务原子性
- Speculative Execution:预判慢节点并启动备份任务
- 自适应调度:根据节点负载动态调整任务分配
- 副本感知调度:优先使用最近副本提升性能
典型分布式数据库编译策略对比
| 系统 | 编译特点 |
|---|---|
| Google Spanner | 基于时间戳的全局事务,Paxos协议保障强一致性 |
| CockroachDB | 多版本并发控制(MVCC),动态分片调整 |
| TiDB | 计算与存储分离架构,MPP执行框架 |
| VoltDB | 预编译执行计划,DDL即时生效 |
| Greenplum | 深度优化数据仓库场景,复杂查询的分布式执行 |
核心挑战与解决方案
数据倾斜问题
- 现象:某些分片成为热点,导致节点负载不均
- 解决方案:
- 哈希分片策略优化
- 动态负载探测与任务迁移
- 中间结果预聚合
跨节点Join性能瓶颈
- 传统方法:Broadcast/Hash Join导致网络风暴
- 优化方案:
- 智能分片对齐(Co-partitioning)
- 分层Join策略(Local→Global)
- 向量化执行引擎
故障恢复复杂度
- CAP定理权衡:在保证可用性(A)和分区容忍(P)时,需弱化一致性(C)
- 解决方案:
- Paxos/Raft协议保障元数据一致性
- 多级Checkpoint机制
- 异步复制与补偿日志
性能优化实践
编译期优化
- 统计信息收集:实时更新分片粒度统计信息
- 代价模型改进:包含网络延迟、磁盘IO等分布式因素
- 执行计划缓存:复用高频查询的编译结果
运行时优化
- 自适应查询执行:根据实际数据分布动态调整计划
- Pipeline并行:分段流水线处理提升资源利用率
- 内存分级管理:冷热数据分层存储策略
未来发展趋势
| 发展方向 | 技术特征 |
|---|---|
| 智能编译 | 机器学习驱动的查询优化 |
| 流批一体 | 统一编译框架支持实时/离线混合负载 |
| 异构计算 | GPU/FPGA加速的编译优化 |
| Serverless | 按需编译与弹性资源分配 |
FAQs
Q1:为什么分布式数据库编译比单机数据库更复杂?
A1:主要差异体现在:①需要处理跨节点数据分布和网络通信;②必须考虑节点故障恢复机制;③需要优化全局资源利用率;④存在数据分片导致的查询重写需求,这些额外维度使得编译过程的复杂度呈指数级增长。
Q2:如何判断分布式查询是否需要全表扫描?
A2:关键判断依据包括:①是否包含无法下推的过滤条件;②分片键是否出现在WHERE子句;③统计信息显示的数据分布情况,现代分布式数据库通常会结合规则匹配和代价估算进行智能决策,例如TiDB的Coprocessor机制会尽量将计算
相关文章

大数据数据库编程教程_数据库编程规范

access数据库编程_数据库编程规范
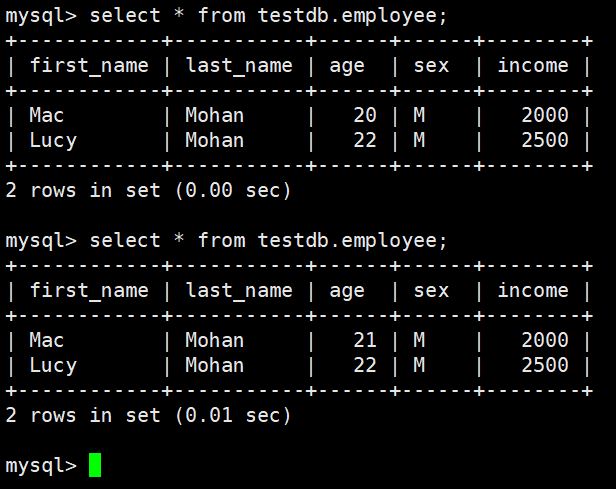
python数据库编程 mysql_数据库编程规范
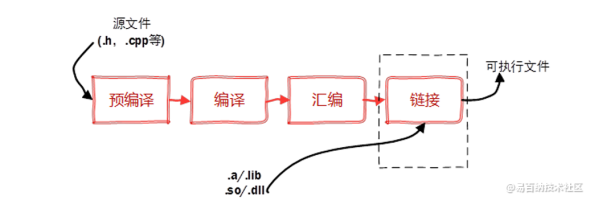
在Linux操作系统中,C语言编译原理涉及多个阶段,包括预处理、编译、汇编和链接。以下是一个关于这些阶段的原创疑问句标题,,探索Linux下C语言编译的奥秘,从预处理到链接的全面解析,涵盖了C语言在Linux下的整个编译流程,旨在引发读者对每个阶段详细内容的好奇心和探索欲望。
c语言常见的编译错误,c语言编译错误怎么解决(c语言常见的编译错误,c语言编译错误怎么解决)
如何高效实现MySQL数据库的分库分表及迁移到分布式数据库DDM?
Oracle数据库中的分布式数据库是什么
分布式数据库 大数据
分布式数据库的数据透明性有哪几种








