
上一篇
分布式数据库 导出
分布式数据库导出需处理数据分片、一致性及并发控制,常用工具如Sqoop或Brtools,导出后需
分布式数据库导出的核心概念与应用场景
分布式数据库的导出是指将存储在多个节点上的数据整合并提取为结构化文件(如CSV、JSON)或二进制文件的过程,其核心目标包括数据迁移、备份、分析、合规审计等场景,与传统单机数据库相比,分布式数据库的导出需解决数据分片、一致性保障、网络传输效率等复杂问题。
关键特性与挑战
| 特性 | 挑战 |
|---|---|
| 数据分片存储(Sharding) | 跨节点数据合并与一致性保障 |
| 高并发读写 | 导出时资源竞争与性能下降 |
| 水平扩展能力 | 大规模数据导出时的带宽与存储压力 |
| 多副本机制 | 避免数据冗余导致的导出冲突 |
分布式数据库导出的常见工具与技术
不同分布式数据库的导出工具差异显著,需根据数据库类型和场景选择:
关系型分布式数据库
- MySQL/ShardingSphere:使用
mysqldump或SELECT INTO OUTFILE,需配合分片键(Sharding Key)逐片导出。 - CockroachDB:支持
COPY命令导出全表数据,自动处理范围分区(Range Partition)。 - TiDB:通过
TIDB_ROW_FORMAT=1参数优化导出性能,支持流式导出至Kafka。
NoSQL分布式数据库
- MongoDB(分片集群):
mongoexport工具需指定--host参数连接所有分片,或通过aggregate管道按标签(Tag)导出。 - Cassandra:使用
nodetool export或sstable2json工具,需注意修复(Repair)数据以确保一致性。 - HBase:通过
HBase API遍历 Region 导出,或使用 Phoenix 的EXPORT TO功能生成CSV。
云原生分布式数据库
- AWS DynamoDB:
dynamodb-dump工具支持按需备份,需配置并行线程数以匹配吞吐量。 - Azure Cosmos DB:SDK 提供
Query Container接口,可分页导出数据并自动处理分区键(Partition Key)。
分布式数据库导出的典型流程
阶段1:需求分析与准备
明确导出目标:

- 全量导出:适用于备份或跨集群迁移。
- 增量导出:基于时间戳或日志(如MySQL的Binlog、MongoDB的Oplog)。
- 过滤导出:通过条件查询(如
WHERE子句)提取特定数据。
环境检查:
- 确保所有分片节点的网络连通性。
- 关闭无关业务负载,避免导出期间的资源争抢。
- 检查存储空间是否足够存放导出文件。
阶段2:执行导出
以 ShardingSphere + MySQL 为例:
# 1. 获取所有分片节点地址
shards=$(shardingctl list-shards --db-name=test_db)
# 2. 遍历分片节点并导出数据
for shard in $shards; do
mysqldump -h $shard -u root -p test_db > shard_${shard}.sql &
done
# 3. 合并分片文件(需手动处理主键冲突)
cat shard_.sql > full_export.sql阶段3:数据验证与清理
- 校验完整性:对比源库与导出文件的记录数、校验和(Checksum)。
- 压缩与加密:使用
gzip压缩或OpenSSL加密敏感数据。 - 清理临时文件:删除分片导出的中间文件,释放存储空间。
分布式数据库导出的常见问题与解决方案
问题1:导出过程中出现数据不一致
- 原因:导出耗时较长,期间数据被修改。
- 解决方案:
- 一致性快照:在导出前冻结数据(如MySQL的
FLUSH TABLES WITH READ LOCK)。 - 事务隔离:使用
REPEATABLE READ隔离级别确保读取一致性。 - 增量补偿:记录导出期间的变更日志,后续合并修正。
- 一致性快照:在导出前冻结数据(如MySQL的
问题2:大规模数据导出导致网络拥堵
- 原因:并发导出占用大量带宽,影响其他业务。
- 解决方案:
- 限速导出:通过工具(如
rsync的--bwlimit)限制传输速率。 - 分时导出:选择业务低峰期执行导出任务。
- 本地缓存:先导出到各节点本地磁盘,再集中传输。
- 限速导出:通过工具(如
分布式数据库导出的最佳实践
分层导出策略:
- 优先导出索引与约束信息,再处理数据。
- 对大表采用“分区导出”,例如按时间范围拆分。
资源隔离:
- 为导出任务分配专用线程池或CPU核心组。
- 使用独立存储路径,避免与业务数据竞争IO。
自动化与监控:
- 集成到运维平台(如Zabbix、Prometheus),实时监控导出进度与错误。
- 通过脚本实现失败重试机制(如
curl的--retry参数)。
相关问答FAQs
Q1:如何选择分布式数据库的导出工具?
A1:需综合考虑以下因素:
- 数据库类型:关系型数据库优先使用原生工具(如
mysqldump),NoSQL数据库依赖官方SDK或CLI。 - 数据规模:小规模数据可直接导出,大规模数据需支持分片、断点续传的工具。
- 目标格式:若需与下游系统兼容,选择支持多格式(如Parquet、Avro)的工具。
Q2:导出过程中发生中断如何恢复?
A2:恢复步骤如下:
- 检查中断点:通过日志定位已导出的分片或块(如
mysqldump的--where条件)。 - 重启导出任务:使用支持断点续传的工具(如
pg_dump的-j参数),或手动跳过已完成部分。 - 验证数据完整性:对比中断前后的校验和,确保无数据
相关文章

Chrome 如何导出证书?,详解 Chrome 浏览器证书导出步骤与注意事项,,Chrome 浏览器简介,证书重要性,导出证书前准备,确认网站使用 HTTPS,打开开发者工具,导出证书步骤,查看证书信息,复制证书到文件,导入证书方法,打开Chrome设置页面,选择管理证书,完成证书导入,常见问题解答,无法查看证书信息,导出证书失败,导入证书无效,归纳与未来趋势,Chrome 安全功能发展趋势,用户需关注网络安全措施

如何高效实现MySQL数据库的分库分表及迁移到分布式数据库DDM?
Oracle数据库中的分布式数据库是什么
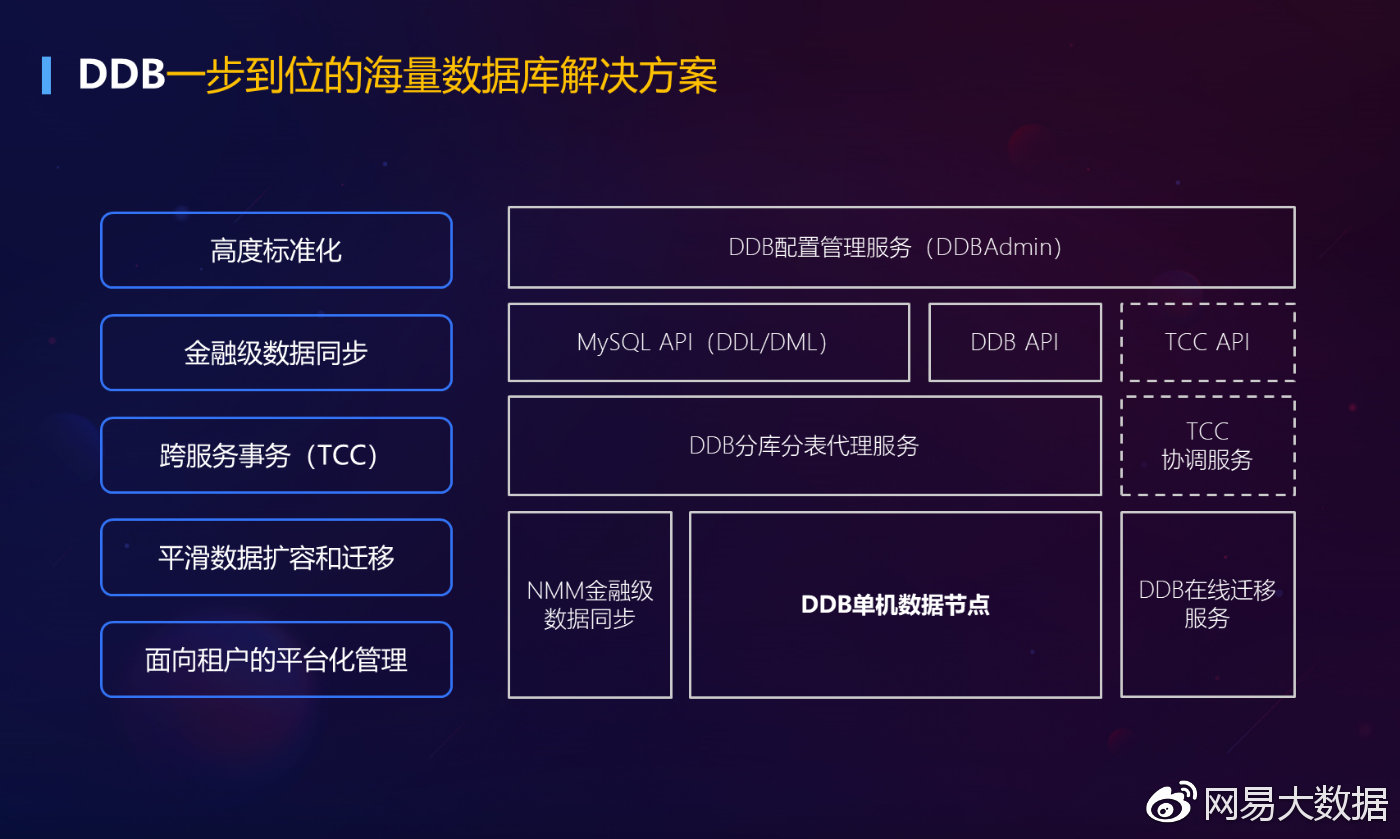
分布式数据库 大数据
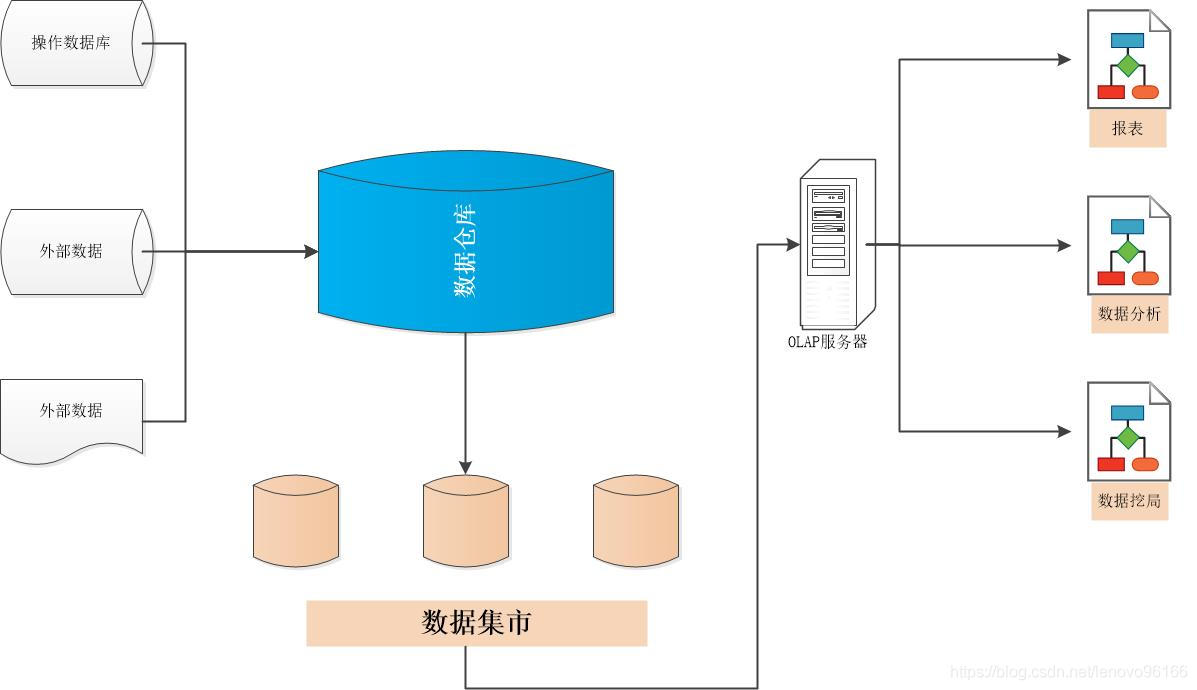
分布式数据库的数据透明性有哪几种
分布式数据库的数据存储策略
分布式数据库的数据一致性
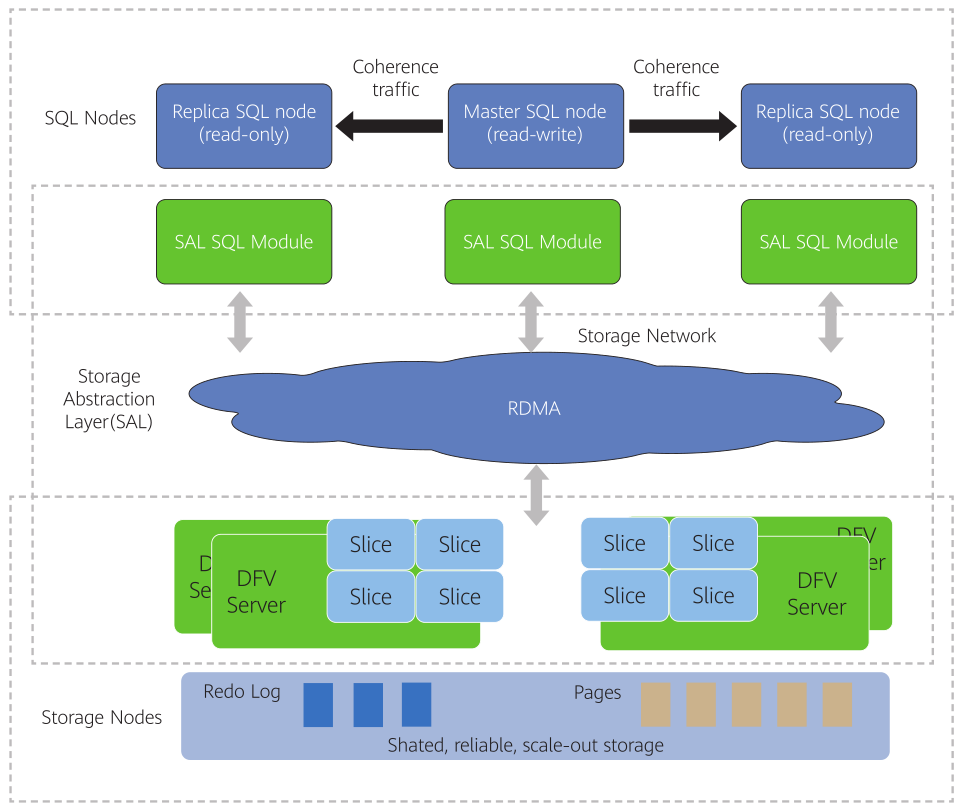
MySQL作为分布式数据库,GaussDB(for MySQL)与其他服务的关系究竟如何?
如何搭建一个使用MySQL分布式数据库的实时报警平台?








