上一篇
分布式数据库算法
分布式数据库算法通过数据分片、一致性协议和容错机制实现高效存储,核心包括基于哈希/范围的分区策略、Paxos/Raft共识算法保障数据一致,以及多副本同步与故障恢复机制,平衡CAP定理下的可用性与分区容忍,支持
基础理论与核心挑战
CAP定理约束
分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍(Partition Tolerance)三者,这一理论由Eric Brewer提出,称为CAP定理,实际应用中需根据业务需求权衡:- CA模式:牺牲分区容忍,适用于强一致性要求场景(如金融交易)。
- AP模式:允许临时不一致,适用于高可用场景(如社交媒体)。
- CP模式:牺牲部分可用性,适用于分布式账本等场景。
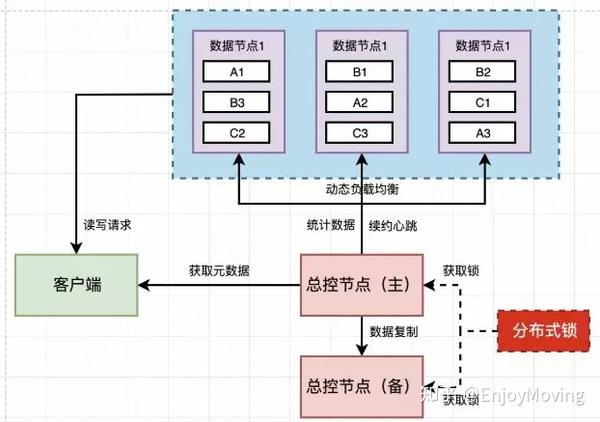
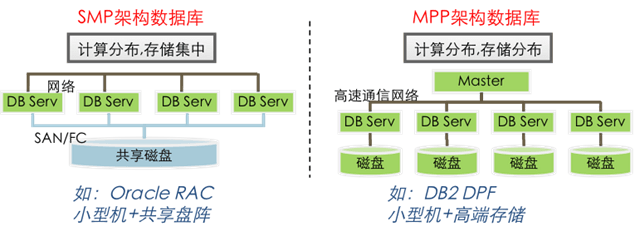
数据分片与负载均衡
数据分片(Sharding)将数据集划分到不同节点,需解决:- 分片策略:范围分片(按数据范围划分)、哈希分片(按键哈希值划分)、目录分片(通过目录服务分配)。
- 负载均衡:动态迁移分片、虚拟节点技术(如Redis Cluster的16384个虚拟槽)实现请求均匀分布。
核心算法与协议
一致性哈希(Consistent Hashing)
用于解决传统哈希分片在节点增减时的大量数据迁移问题。

- 原理:将节点和数据映射到环形哈希空间,数据归属顺时针最近节点。
- 优化:引入虚拟节点(如每个物理节点对应100个虚拟节点),减少数据倾斜。
- 示例:
哈希环:0 → NodeA → 0.3 → NodeB → 0.7 → NodeC → 1.0 数据Key "user123" 哈希值为0.6 → 归属NodeB
分布式一致性协议
| 协议类型 | 特点 | 适用场景 |
|---|---|---|
| Paxos | 通过提议-承诺-学习三阶段达成共识 | 高可靠性系统(如Google Chubby) |
| Raft | 简化为领导者选举+日志复制,易理解 | 分布式数据库(如etcd、TiKV) |
| ZAB | 结合原子广播与崩溃恢复 | Kafka、ZooKeeper |
- Raft算法流程:
- 选举阶段:节点超时未收到心跳则发起选举,多数派原则选出领导者。
- 日志复制:领导者接收客户端请求,追加到日志并同步到追随者。
- 提交机制:当日志条目被多数节点确认后提交,保证线性一致性。
数据复制与故障恢复
- 复制策略:
- 主从复制:主节点处理写操作,从节点异步复制(如MySQL)。
- 多主复制:允许多个节点写入,依赖冲突解决机制(如CRDTs)。
- 故障检测:
采用心跳机制(如每100ms发送心跳)和租约机制(如ZooKeeper的临时节点)。
优化与扩展策略
读写分离与缓存
- 读请求分配到从节点,写请求集中到主节点。
- 引入L1/L2缓存(如Redis)减少数据库压力。
事务管理
- 两阶段提交(2PC):协调者与参与者交互,但存在阻塞问题。
- TCC(Try-Confirm-Cancel):预处理资源锁定,降低阻塞风险。
- 本地化事务:通过分片键设计避免跨节点事务。
新型共识算法
- PBFT:适用于权限链网络,解决拜占庭容错问题。
- HoneyBadger BFT:异步环境下的高效拜占庭容错协议。
典型系统对比
| 系统 | 分片方式 | 一致性协议 | 复制因子 | 特点 |
|---|---|---|---|---|
| Cassandra | 哈希分片 | 无全局协议 | 可配置 | 高写入吞吐量,AP优先 |
| CockroachDB | 范围分片 | Raft | 5 | 强一致性,SQL支持 |
| MongoDB | 哈希+范围 | 无 | 可配置 | 灵活Schema,最终一致 |
FAQs
Q1:如何选择CAP定理中的优先级?
A1:根据业务需求:
- 强一致性场景(如支付):选择CP或CA模式,牺牲部分可用性。
- 高可用场景(如电商浏览):选择AP模式,允许短暂数据延迟。
- 混合策略:通过业务分层(如交易用CP,日志用AP)实现平衡。
Q2:为什么Raft比Paxos更易实现?
A2:Raft通过以下设计简化复杂度:
- 单一领导者:减少节点间协商成本。
- 任期(Term)机制:避免旧领导者干扰新选举。
- 日志匹配原则:仅同步已确认的日志条目,避免冲突。
etcd和Consul均基于Raft实现,代码量比Paxos减少30%-50%。