
上一篇
GPU服务器使用技巧如何快速提升性能?
GPU服务器通过搭载高性能显卡加速计算任务,主要用于深度学习训练、图像渲染及科学计算等领域,用户需安装GPU驱动与CUDA工具包,配置深度学习框架后运行并行计算任务,支持远程访问并通过命令行或开发工具调用显卡资源,提升运算效率。
GPU服务器是一种搭载图形处理器(Graphics Processing Unit)的高性能计算设备,凭借其并行计算能力,广泛应用于人工智能训练、深度学习、科学模拟、视频渲染等领域,对于初次接触GPU服务器的用户而言,了解其基本使用方法至关重要,本文将从基础配置到实际应用,逐步解析如何高效利用GPU服务器。

GPU服务器的核心优势
GPU服务器与传统CPU服务器的最大区别在于其计算架构,GPU拥有数千个核心,可同时处理大量简单计算任务,适合以下场景:
- 深度学习与AI模型训练:如TensorFlow、PyTorch框架下的神经网络训练。
- 大数据分析:并行处理海量数据,加速数据清洗、特征提取。
- 图形渲染与视频处理:3D建模、影视特效制作。
- 科学计算:流体力学模拟、分子动力学等复杂计算。
GPU服务器的使用步骤
准备工作:选择适合的硬件与驱动
- 硬件配置:根据需求选择GPU型号(如NVIDIA A100、RTX 4090等)、显存大小(建议至少16GB)、CPU与内存的匹配性。
- 安装驱动与工具包:
- 下载GPU厂商提供的驱动程序(如NVIDIA官网的CUDA Toolkit)。
- 安装深度学习框架(如使用
conda install pytorch或pip install tensorflow-gpu)。
# 示例:Ubuntu系统安装NVIDIA驱动 sudo apt install nvidia-driver-535 nvidia-smi # 验证驱动是否安装成功
配置开发环境
- 容器化部署:使用Docker或NVIDIA Container Toolkit快速部署环境。
- 虚拟环境管理:通过Anaconda创建独立Python环境,避免依赖冲突。
# 使用Docker运行支持GPU的容器 docker run --gpus all -it nvidia/cuda:11.8.0-base
运行GPU加速任务
- 代码适配:确保代码调用GPU资源(如PyTorch中指定
device='cuda:0')。 - 资源监控:通过
nvidia-smi或第三方工具(如Prometheus)实时查看显存占用、温度等。
# PyTorch示例:将模型和数据迁移到GPU import torch model = torch.nn.Linear(10, 5).cuda() input_data = torch.randn(10).cuda() output = model(input_data)
优化与调试
- 显存管理:使用
torch.cuda.empty_cache()释放未使用的显存。 - 分布式训练:多卡并行时,通过
torch.nn.DataParallel或Horovod框架提升效率。
注意事项与常见问题
- 兼容性问题:CUDA版本需与框架要求匹配(如PyTorch 2.0需CUDA 11.7以上)。
- 散热与功耗:高负载运行时确保服务器散热良好,避免过热降频。
- 成本控制:按需选择云服务(如按小时计费)或本地部署。
典型应用场景案例
- AI公司:训练图像分类模型时,GPU服务器可将训练时间从数天缩短至几小时。
- 影视工作室:渲染4K视频时,GPU加速比CPU快10倍以上。
- 科研机构:气候模拟任务中,利用多GPU并行计算提升效率。
进阶资源推荐
- 官方文档:NVIDIA CUDA Toolkit指南、PyTorch官方教程。
- 社区支持:Stack Overflow、GitHub开源项目。
- 云服务商方案:AWS EC2 GPU实例、阿里云GN6系列。
引用说明
- NVIDIA CUDA安装指南:https://docs.nvidia.com/cuda/
- PyTorch官方文档:https://pytorch.org/docs/stable/notes/cuda.html
- Docker GPU容器配置:https://docs.docker.com/config/containers/resource_constraints/#gpu
相关文章

腾讯云gpu服务器,腾讯云GPU服务器(腾讯云gpu服务器,腾讯云gpu服务器区别)

Contabo:GPU服务器(Nvidia Tesla T4 16 GB)(conda gpu)(gpu服务器使用教程)

gpu服务器怎么用,GPU服务器搭建2022年更新(gpu服务器怎么使用)
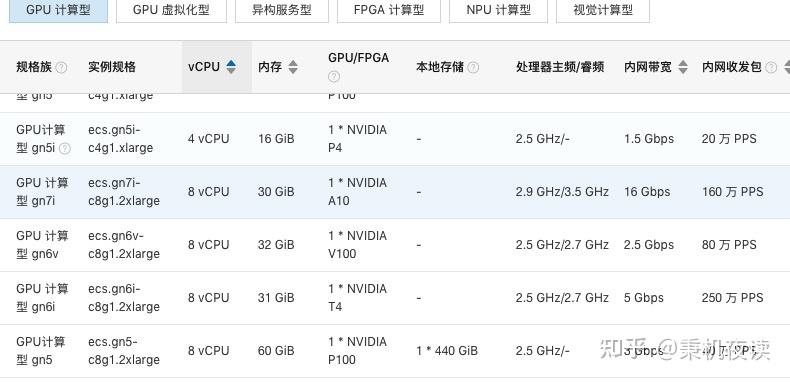
腾讯云gpu服务器(阿里云 GPU服务器)(腾讯云gpu服务器价格)
gpu服务器租用,阿里云gpu服务器租用2022年更新(阿里云gpu服务器租用价格表)
GPU服务器虚拟化:高性能计算和资源利用的更佳选择 (gpu服务器 虚拟化)
如何快速提升网站排名,快速提升网站排名的方法
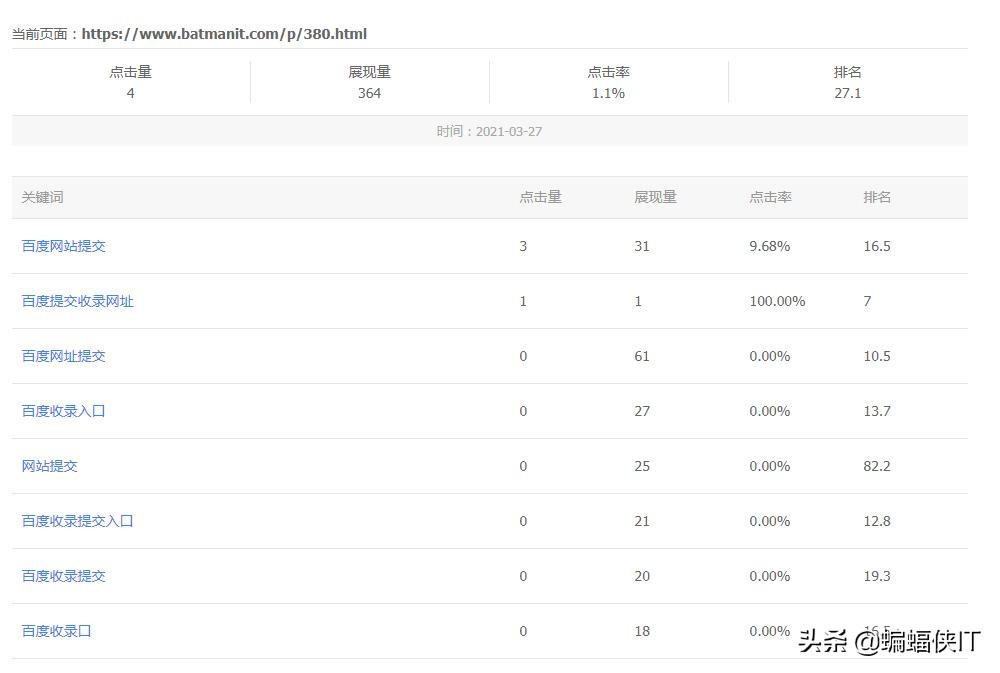
如何快速提升关键词排名,关键词排名的快速提升方法
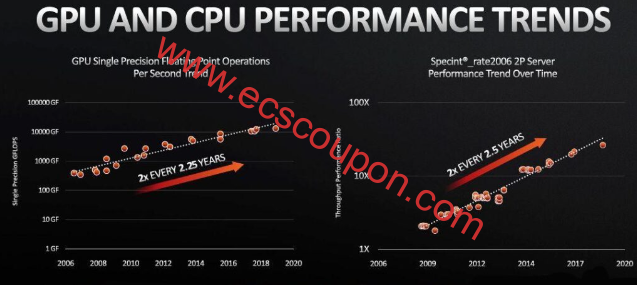
GPU服务器是否需要增加内存才能提升性能?








