上一篇
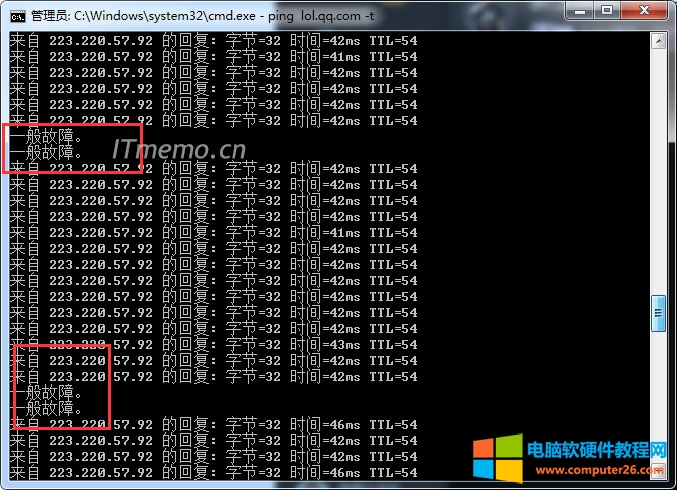
分布式数据库管理系统ping后显示一般故障
分布式数据库ping后报一般故障,需检查网络连通性、防火墙配置及节点状态,确认各分片/副本服务运行正常,排查网络
分布式数据库管理系统Ping后显示一般故障的详细分析与解决方案
在分布式数据库管理系统(Distributed Database Management System, DDBMS)的运维过程中,通过ping命令测试节点连通性时出现“一般故障”提示,可能涉及网络、配置、服务状态或硬件资源等多方面问题,本文将从故障现象、可能原因、排查步骤及解决方案四个维度展开分析,并提供常见问题解答。
故障现象描述
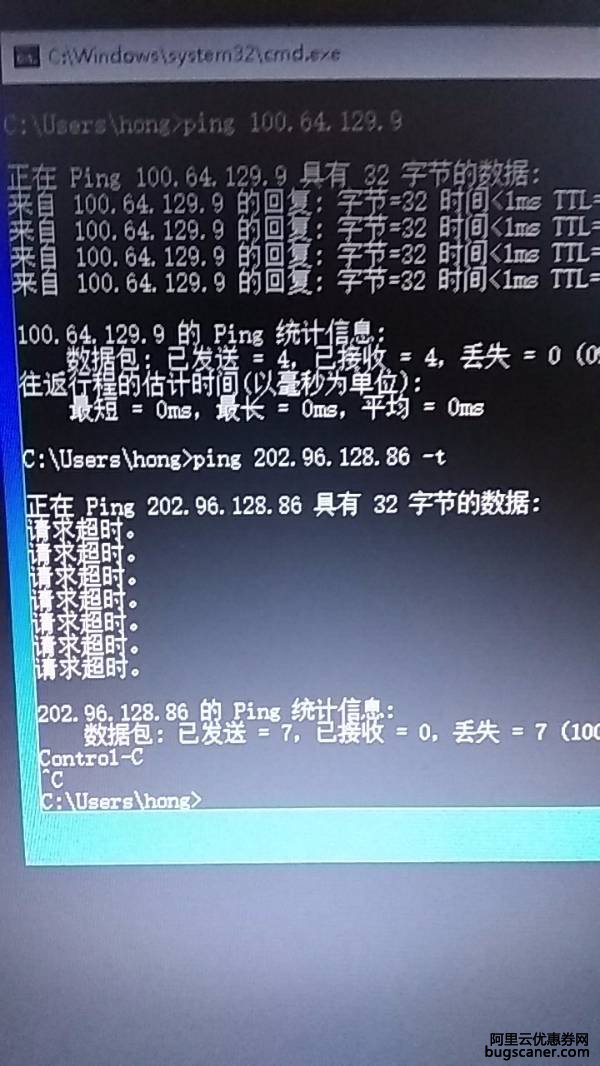
Ping不通目标节点
- 执行
ping <节点IP>或ping <节点域名>后,返回“请求超时”或“一般故障”。 - 可能伴随其他症状:数据库服务不可用、业务请求延迟增高、节点间心跳检测失败。
- 执行
部分节点连通性异常
- 集群中某些节点可正常响应
ping,而其他节点出现故障。 - 可能影响数据分片、副本同步或负载均衡功能。
- 集群中某些节点可正常响应
可能原因分类
| 故障类别 | 典型原因 |
|---|---|
| 网络层问题 | 节点网络接口宕机或未绑定正确IP 中间网络设备(交换机/路由器)阻断ICMP包 VPC路由表错误或安全组限制 |
| 操作系统层问题 | 防火墙策略拦截ICMP协议(如iptables或firewalld规则)主机网络命名服务(DNS)解析失败 |
| 数据库服务层问题 | 节点服务进程崩溃或未启动 分布式协议(如Paxos/Raft)选举超时 资源耗尽(内存/CPU/磁盘)导致服务不可用 |
| 配置错误 | 节点IP配置错误或未加入集群 SSL/TLS加密导致ICMP被禁用 心跳检测端口与Ping端口不匹配 |
系统性排查步骤
步骤1:验证基础网络连通性
- 命令:
ping <目标IP> -c 4 - 预期结果:若网络正常,应收到4次ICMP响应;若超时,需检查:
- 源/目标节点网络接口状态(
ip a查看IP绑定)。 - 中间网络设备是否允许ICMP(如云厂商安全组规则)。
- 本地DNS解析是否正确(
nslookup <域名>)。
- 源/目标节点网络接口状态(
步骤2:检查操作系统防火墙配置
常见场景:Linux系统默认禁用ICMP或仅允许出站流量。
排查命令:
# 检查firewalld状态 firewall-cmd --state # 若为"running",需查看规则 firewall-cmd --list-all # 确认是否存在"icmp-block-inversion"规则 # 检查iptables规则 iptables -L -n -v # 查看INPUT链是否DROP ICMP请求
解决方案:临时关闭防火墙测试(
systemctl stop firewalld),确认是否为防火墙拦截。
步骤3:验证数据库服务状态
命令:
# 检查进程是否存在 ps -ef | grep <数据库服务名> # 如`tidb`、`cockroach` # 查看服务日志 tail -n 100 /var/log/<数据库日志路径>/log # 关注报错信息
可能问题:
- 服务进程因内存溢出(OOM)被杀死。
- 配置文件错误(如监听地址非
0.0.0导致外部无法访问)。
步骤4:检查分布式协议状态
- 场景:若使用Raft/Paxos协议,节点间心跳中断可能导致脑裂。
- 命令:
# 以TiDB为例,查看Raft状态 pd-ctl region -j | grep "leader" # 确认Leader节点是否正常
- 解决方案:重启异常节点或强制重新选举(需谨慎操作)。
步骤5:资源监控与限流分析
- 监控指标:CPU、内存、磁盘IO、网络带宽。
- 命令:
# 查看资源使用率 top -c # CPU占用 free -m # 内存剩余 df -h # 磁盘空间 iostat -x # 磁盘IO负载
- 可能问题:资源耗尽导致服务不可用,需扩容或优化配置。
解决方案汇总表
| 故障原因 | 解决措施 |
|---|---|
| 防火墙拦截ICMP | 修改防火墙规则允许ICMP(firewall-cmd --add-rich-rule='rule family="ipv4" source address="0.0.0.0/0" accept') |
| 服务进程未启动 | 重启数据库服务(如systemctl restart tidb) |
| 节点IP配置错误 | 修正/etc/hosts或集群配置文件中的IP地址 |
| 网络路由中断 | 检查VPC路由表、安全组规则,确保节点间网络互通 |
| 资源耗尽(如内存OOM) | 调整ulimit参数,增加swap分区,或升级硬件资源 |
| 分布式协议脑裂 | 停止异常节点,触发新主节点选举(需参考具体数据库文档) |
相关FAQs
Q1:为什么能ping通节点但数据库服务仍然不可用?
A1:ping仅验证网络层连通性,而数据库服务可能因以下原因不可用:
- 服务进程未监听正确端口(如仅监听
0.0.1)。 - 数据库实例处于维护模式或未加入集群。
- 客户端与服务端协议版本不兼容(如SSL证书错误)。
解决方法:通过telnet <IP>:<端口>测试服务端口连通性,并检查服务日志。
Q2:如何避免分布式数据库因网络故障导致脑裂?
A2:可采取以下措施:
- 部署多活数据中心,启用跨区域仲裁机制(如TiDB的Placement Driver)。
- 配置合理的心跳超时参数(如将Raft心跳时间从默认1s调整为500ms)。
- 使用专线或高质量网络服务商,减少网络抖动。
- 定期演练故障切换