
上一篇
html识别ps图片文字
HTML本身无法直接识别PS图片中的文字,需结合OCR技术实现,可通过Canvas将图片转为数据URL,引入Tesseract.js等OCR库进行文字识别,最终将提取的文本动态渲染至网页元素,注意保持图片清晰度与正文字方向以提升识别
识别PS图片文字的流程
图片预处理
- 灰度化:将彩色图片转为灰度图,降低颜色干扰。
- 二值化:通过阈值处理将图片转为黑白,增强文字对比度。
- 降噪:去除图片中的噪点(如斑点、杂色)。
- 倾斜矫正(可选):若文字倾斜,需进行透视变换校正。
选择OCR工具
常用工具及特点:
| 工具名称 | 适用场景 | 特点 |
|—————-|————————|——————————-|
| Tesseract | 开源免费 | 支持多语言,但复杂字体识别率低 |
| 百度AI开放平台 | 中文识别 | 高精度,需API调用 |
| 阿里云OCR | 多场景(含PS特效) | 支持模糊/艺术字,付费服务 |
| ABBYY FineReader | 专业文档识别 | 高准确率,适合复杂排版 |文字识别与后处理

- 分段识别:对长文本按段落或区域拆分,提升准确性。
- 校正错别字:OCR可能误识模糊或特效文字,需人工校对。
- 格式还原:保留原文本的排版(如加粗、换行),需结合CSS样式。
HTML展示识别结果
基础结构
<div class="ocr-result"> <h3>识别结果:</h3> <p>这是第一行文字...</p> <p>这是第二行文字...</p> </div>特殊字符处理
- 换行符:将替换为
<br>标签。 - 空格与缩进:使用
保留空格,或用CSStext-indent控制缩进。 - 符号转义:如
&转为&,防止HTML解析错误。
- 换行符:将替换为
样式优化
.ocr-result { font-family: "Microsoft YaHei", sans-serif; / 适配中文字体 / line-height: 1.6; white-space: pre-wrap; / 保留换行 / }
常见问题与解答
问题1:PS保存的JPEG图片文字模糊,如何提高识别率?
解答:
- 在PS中另存为
PNG或TIFF格式,避免压缩导致文字失真。 - 使用
图像大小调整分辨率至300dpi以上,增强清晰度。 - 若文字仍有锯齿,可尝试
滤镜 > 锐化或表面模糊预处理。
问题2:艺术字(如渐变、投影)无法识别怎么办?
解答:
- 分层处理:在PS中单独提取文字图层(若源文件可用),导出为透明背景PNG。
- 阈值调整:在OCR工具中启用“自适应阈值”或手动调节二值化参数。
- 手动修正:对无法识别的部分截取图片,重新识别后拼接结果
相关文章
图片文字提取在线软件免费,图片文字提取在线(图片文字提取免费工具在线)

电脑如何清理碎片文件,碎片文件(电脑如何清理碎片文件,碎片文件夹)

文字识别_华为OCR_图片转化为文字_在线图片文字识别
关于AngularJS中的ngbindhtml指令,一个原创的疑问句标题可以是,,如何在AngularJS中使用ngbindhtml指令安全地绑定并显示HTML内容?,清晰地表达了想要了解如何在AngularJS中利用ngbindhtml指令来绑定并显示HTML内容,同时强调了安全地这一关键点,表明提问者对于数据绑定的安全性有所关注。
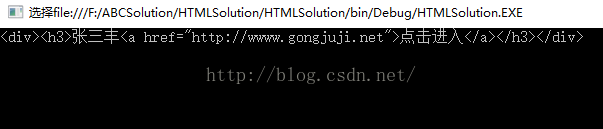
html识别不出中文字符串

如何鉴别ps图片的真假
在html中如何让图片居中 html如何把图片居中,图片居中怎么设置html
ps图片文字处理教程_使用教程








