上一篇
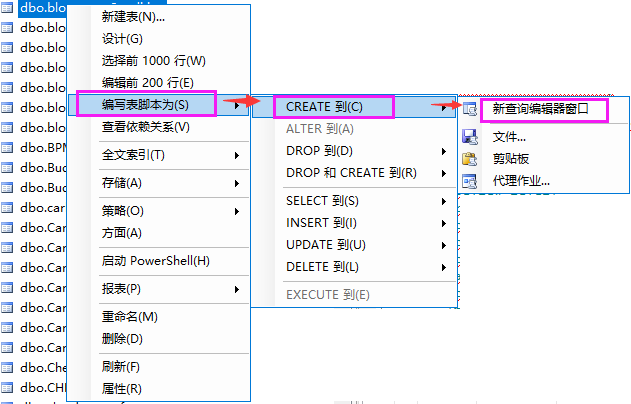
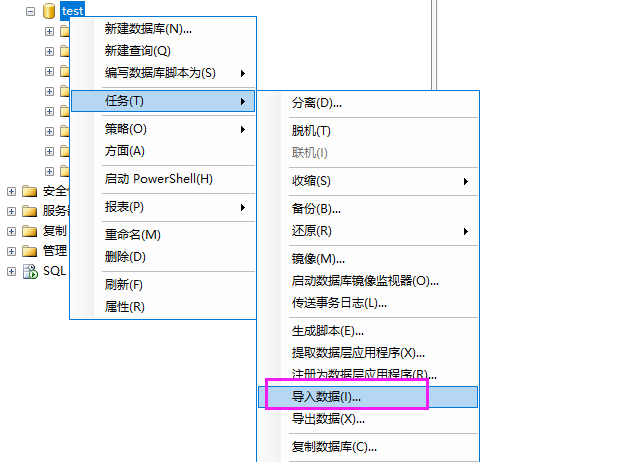
怎么在数据库表里复制粘贴
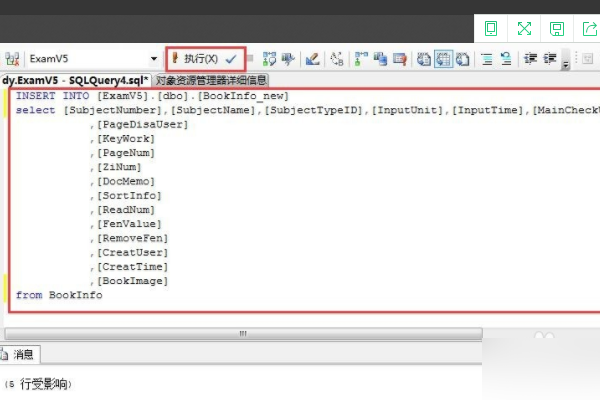
数据库表中复制粘贴可通过SQL语句(如
INSERT INTO ... SELECT FROM ...)
数据库表中进行“复制粘贴”操作是日常数据管理和维护中的常见需求,但具体实现方式会因使用的数据库管理系统(DBMS)、数据量大小以及是否需要保留关联关系等因素而有所不同,以下是详细的步骤指南和注意事项,涵盖主流关系型数据库(如MySQL、PostgreSQL、SQL Server)及工具辅助方法。
基础概念澄清
这里的“复制粘贴”并非像文本编辑器那样直接Ctrl+C/V,而是通过SQL语句或图形化界面完成以下目标:
复制整张表结构+数据(包括字段类型、约束、索引等);
仅复制部分选定行的数据;
跨数据库迁移特定记录。
需注意:若涉及外键约束,直接复制可能导致引用完整性错误,需谨慎处理关联表顺序。
完整方案对比表
| 场景 | 适用工具/命令 | 优点 | 局限性 |
|---|---|---|---|
| 快速克隆整个表 | CREATE TABLE new_table AS SELECT FROM old_table; |
语法简单,自动继承原表属性 | 不适用于大规模分片场景 |
| 选择性复制列 | INSERT INTO target_table (col1, col2) SELECT colA, colB FROM source_table; |
灵活控制字段映射 | 需手动指定对应关系 |
| 带条件的行过滤 | 添加WHERE子句到SELECT语句中 | 精准筛选所需数据 | 复杂条件可能影响性能 |
| 图形化操作 | Navicat/DBeaver等IDE的拖拽功能 | 可视化降低学习成本 | 批量操作效率低于脚本批量执行 |
| 大数据量优化 | 分批次插入(BATCH模式) | 减少事务日志压力 | 代码复杂度增加 |
分步实操详解
SQL标准语法实现全表复制
以MySQL为例,假设现有名为employees的员工信息表,欲创建其副本employees_backup:
CREATE TABLE employees_backup AS SELECT FROM employees;
此命令将执行以下动作:
根据原表定义新建目标表;
将所有现存记录插入新表中;
默认包含主键、索引和非空约束(但不会自动创建外键)。
️ 警告:若原表存在触发器或存储过程依赖,需额外配置以确保功能一致性。
对于PostgreSQL用户,可改用:
CREATE TABLE employees_archive (LIKE employees INCLUDING ALL); INSERT INTO employees_archive SELECT FROM employees;
其中INCLUDING ALL参数确保复制所有依赖对象(如默认值、权限设置)。
按条件筛选子集复制
当只需迁移符合特定规则的数据时,例如提取薪资高于5000元的记录到测试环境:
INSERT INTO staging_area (id, name, salary, join_date) SELECT id, name, salary, join_date FROM production_db.staff WHERE salary > 5000 AND department = 'Engineering';
关键点解析:
️ 显式列出目标列可避免隐式转换错误;
️ 使用别名处理源与目标列名不一致的情况;
️ 多条件组合时应优先在WHERE子句过滤,而非事后删除冗余行。
跨数据库实例迁移技巧
若需将本地开发环境的表同步至云端生产库,推荐采用以下流程:
① 导出源数据为SQL脚本:
mysqldump -u root -p --no-data mydatabase > schema_only.sql # 仅结构 mysqldump -u root -p mydatabase > full_backup.sql # 含数据
② 修改连接参数后导入目标库:
USE target_database; SOURCE '/path/to/full_backup.sql';
③ 针对异构数据库(如从MySQL迁至SQL Server),建议先用ETL工具转换兼容格式。
GUI工具高效实践
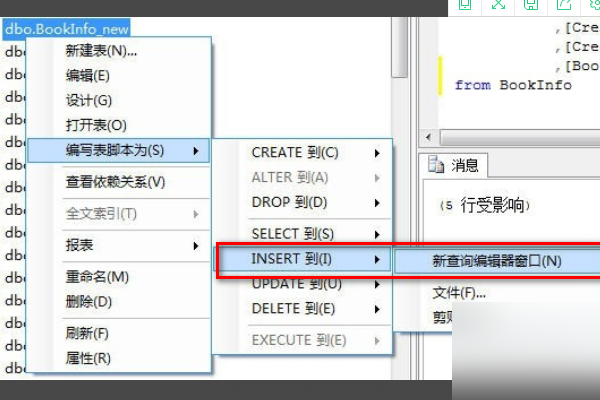
以Navicat为例演示三步完成复制:
1️⃣ 右键点击源表 → “复制到…”;
2️⃣ 选择目标数据库/模式;
3️⃣ 勾选选项:“包括数据”“保留主键”“生成自增序列”。
高级设置中还可调整字符集编码、存储引擎等高级参数。

典型错误排查手册
| 报错信息 | 根本原因分析 | 解决方案示例 |
|---|---|---|
| Duplicate entry ‘xxx’ for key PRIMARY | 主键冲突(已存在相同ID记录) | ALTER TABLE new_table DROP PRIMARY KEY; |
| Error 1062: too many keys specified | 违反唯一性约束 | 使用IGNORE关键字忽略重复项 |
| Foreign key check failed | 关联父表中缺少对应参照记录 | 先插入父表数据再处理子表 |
| Incorrect string value: ‘x…’ | 字符编码不匹配(UTF8 vs Latin1) | 统一设置为CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; |
性能调优建议
▶︎ 大表迁移时分块处理:每次处理1万条记录并提交事务,示例如下:
SET @batch_size = 10000;
WHILE (SELECT COUNT() FROM temp_queue) > 0 DO
INSERT INTO destination_table (...)
SELECT ... FROM source_table LIMIT @batch_size;
END WHILE;
▶︎ 禁用非必要索引后再批量插入,完成后重建索引;
▶︎ 关闭外键检查临时提升速度:SET FOREIGN_KEY_CHECKS=0;(慎用!)
FAQs
Q1: 如果我只想复制某个表的部分列怎么办?
A: 在SELECT子句中明确指定需要的列即可。
CREATE TABLE filtered_contacts AS SELECT user_id, email, created_at FROM users WHERE active = 1;
这将只复制三列而非全部字段,若目标表已存在,则改用INSERT INTO … SELECT语法。
Q2: 复制后的表如何同步后续新增的数据?
A: 可通过以下任一方式实现增量更新:
① 定时任务执行差异同步脚本;
② 设置触发器自动捕获INSERT/UPDATE事件;
③ 使用CDC(Change Data Capture)机制捕获变更流。
推荐方案:结合Binlog解析工具