上一篇
怎么复制数据库中的表结构
数据库表结构可用
CREATE TABLE new_table LIKE old_table;语句,或通过管理工具导出/导入DDL脚本实现
数据库中的表结构是一项常见的数据库管理任务,适用于数据迁移、备份、开发测试环境搭建等场景,以下是详细的操作指南,涵盖主流关系型数据库(MySQL/PostgreSQL/Oracle/SQL Server)及通用方法,并附注意事项和常见问题解答。

核心原理与适用场景
复制表结构的本质是提取目标表的元数据(字段名、类型、约束、索引、注释等),然后在新位置重建相同模式的对象,典型应用场景包括:
跨数据库迁移时保留原有设计规范;
创建临时表用于ETL处理;
快速搭建测试环境的基准数据集;
标准化多租户系统的共享架构模板。
需注意:此操作仅复制结构,不包含实际存储的数据记录,若需同步数据,需额外执行INSERT INTO ... SELECT语句。
分步实现方案
SQL脚本导出法(通用且精准)
这是最推荐的方式,通过数据库自带的DDL生成功能实现无损复制,以MySQL为例:
-查看完整建表语句(含所有约束和索引) SHOW CREATE TABLE `原表名`;
执行结果类似:
CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(50) COLLATE utf8mb4_general_ci NOT NULL, `email` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uk_email` (`email`), CONSTRAINT `fk_profile` FOREIGN KEY (`profile_id`) REFERENCES `profiles` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
将上述输出保存为.sql文件后,修改表名为新名称(如users_copy),再于目标库执行即可完成结构克隆。
优势:完整保留主键、外键、默认值、存储引擎等高级属性;兼容不同版本升级后的兼容性调整。
| 数据库类型 | 关键命令 | 备注 |
|---|---|---|
| PostgreSQL | \d+ tablename |
psql终端专用 |
| SQL Server | EXEC sp_helptext 'tablename'; |
或使用SSMS图形化界面 |
| Oracle | DBMS_METADATA.GET_DDL('TABLE', 'SCHEMA_NAME', 'TABLE_NAME') |
需授予权限给调用者 |
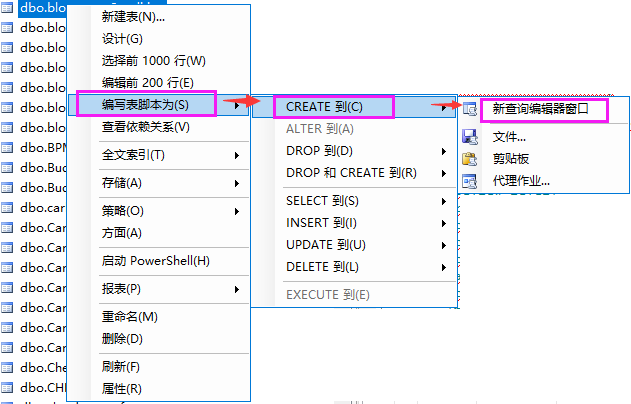
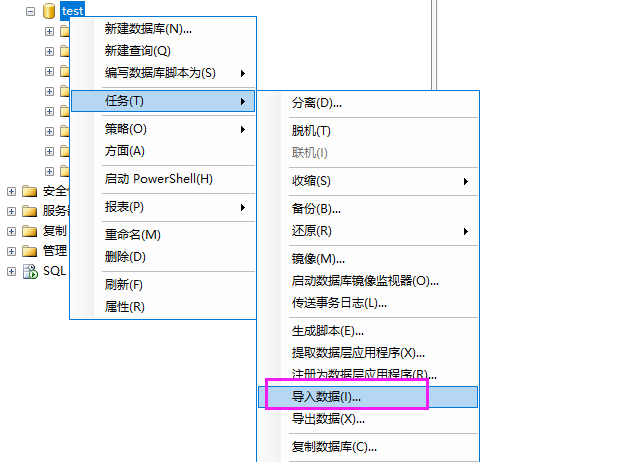
可视化工具辅助(适合新手)
主流GUI工具均支持右键拖拽式复制:
- Navicat Premium:在对象浏览器中选中表→右键“复制到”→选择目标连接和新模式;
- DBeaver Community Edition:通过“数据库→传输工具”模块实现跨库结构同步;
- HeidiSQL:提供“Export Structure Only”选项直接生成无数据的SQL脚本。
此类工具自动处理复杂依赖关系(如视图、触发器),但可能因厂商锁定导致跨平台兼容性下降。
程序化实现(批量自动化需求)
当需要大规模批量操作时,可借助编程语言调用JDBC/ODBC接口:
# Python示例(使用pymysql库)
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='xxx', db='source_db')
cursor = conn.cursor()
cursor.execute("SHOW FULL COLUMNS FROM old_table")
columns = [dict(zip(['Field','Type','Null','Key','Default','Extra'], row)) for row in cursor.fetchall()]
# 根据解析结果动态构建CREATE TABLE语句
new_cols = []
for col in columns:
null_flag = "NULL" if col['Null'] == 'YES' else "NOT NULL"
default_val = f"DEFAULT {col['Default']}" if col['Default'] is not None else ""
new_cols.append(f"`{col['Field']}` {col['Type']} {null_flag} {default_val}")
create_stmt = f"CREATE TABLE new_table ({', '.join(new_cols)});"
cursor.execute(create_stmt)
conn.commit()
️ 注意处理特殊字符转义和大小写敏感问题,建议优先测试单表明细后再扩展至全量。
关键细节把控
① 约束与索引的完整性传递
原始表中存在的三大类对象必须显式迁移:
| 类型 | 作用说明 | 遗漏后果 |
|————–|————————–|————————|
| PRIMARY KEY | 确保唯一性和查询性能 | 插入重复记录导致错误 |
| FOREIGN KEY | 维护参照完整性 | 破坏关联关系的有效性 |
| UNIQUE/CHECK | 实施业务规则限制 | 允许非规数据进入系统 |
若忽略外键约束,则可能在新表中插入违反业务逻辑的数据组合。
② 自增列的特殊处理
对于含AUTO_INCREMENT属性的字段(如MySQL),需确认两点:
是否重置起始值?可通过ALTER TABLE tablename AUTO_INCREMENT=1;指定;
目标表是否存在同名序列对象冲突?(尤其PostgreSQL使用SERIAL类型时)。
③ 字符集与排序规则适配
跨语言环境部署时极易出现问题。
- Windows默认使用
latin1编码,而Linux多为utf8mb4; - SQL Server区分
Latin1_General_CI_AS和Chinese_PRC_CI_AS排序规则。
解决方案是在CREATE TABLE末尾明确指定:) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; -MySQL示例
④ 分区策略继承
如果源表采用分区表设计(如按时间范围分区),直接复制可能导致性能骤降,此时应评估是否需要:
️ 保持相同分区策略 → 添加PARTITION BY ...子句;
禁用分区 → 移除相关定义改为普通堆表。
典型错误排查手册
| 现象描述 | 根本原因 | 解决方法 |
|---|---|---|
| “Duplicate entry”报错 | 未清除自增计数器 | 执行TRUNCATE TABLE或重置AUTO_INCREMENT值 |
| 外键约束失败 | 参照表尚未创建 | 按依赖顺序先创建父表再子表 |
| 中文乱码 | 字符集不匹配 | 统一设置为UTF-8家族编码格式 |
| 存储过程无法调用 | 仅复制结构未迁移过程定义 | 单独导出存储过程脚本并执行 |
FAQs
Q1: 如果只需要复制部分列怎么办?
A: 修改由SHOW CREATE TABLE获得的DDL脚本,删除不需要的列定义,然后执行新的CREATE TABLE语句,例如原始有(id, name, age),现只需(id, name),则手动移除age相关的行即可,注意保持逗号分隔符的正确性。
Q2: 能否在不同版本的数据库间复制表结构?
A: 理论上可行但存在风险,例如从MySQL 5.7迁移到8.0时,某些过时语法(如旧版ENUM类型)会报错,建议先用较低版本的兼容性模式生成脚本,再逐步应用到高版本,并通过EXPLAIN计划验证执行效率,对于跨数据库类型迁移(如MySQL→PostgreSQL),推荐使用中间件工具如Flyway或