上一篇
java jsp乱码怎么解决方案
Java JSP乱码需统一设置页面、请求及响应编码为UTF-8,并在
JSP头部声明“
Java Web开发中,JSP页面出现乱码是一个普遍存在的问题,尤其在涉及中文等非ASCII字符时更为明显,这种现象通常源于字符编码处理不一致导致的字节流解析错误,以下是系统化的解决方案,涵盖从底层原理到具体实现的完整流程:
核心原则
所有环节必须保持统一的字符集(推荐UTF-8),包括源代码存储、编译环境、运行时容器配置及数据库连接,任何一环的缺失都可能导致乱码重现。
JSP页面自身的编码设置
这是最基础且关键的一步,需要在每个JSP文件开头通过指令明确指定编码格式:

<%@ page language="java" pageEncoding="UTF-8" contentType="text/html;charset=UTF-8" %>
- pageEncoding:定义该页面源码保存时使用的字符集(即编辑器打开文件时的编码方式),若未正确设置,IDE保存文件时可能自动转换为其他编码(如GBK),导致读取错误。
- contentType中的
charset=UTF-8:告知浏览器此页面采用UTF-8解码显示内容,二者缺一不可,否则可能出现“双重编码”或浏览器默认使用ISO-8859-1解析的情况,当跳过此项时,Tomcat服务器可能默认采用ISO-8859-1传输响应头,造成浏览器端渲染异常。
请求与响应对象的显式编码控制
即使完成了上述配置,仍需在Servlet或控制器中主动干预HTTP消息体的编解码过程:
处理客户端提交的数据(如表单POST)
对于HttpServletRequest对象,需手动设置解析所用的字符集:
request.setCharacterEncoding("UTF-8"); //必须在调用getParameter()之前执行
String userInput = request.getParameter("username");
此操作确保了从网络流入的字节流按UTF-8解码为Java内部的Unicode字符串,若遗漏此步骤,Tomcat等容器会依据server.xml中的Connector配置(默认常为ISO-8859-1)进行初次转换,此时中文将变成乱码。
构造回送至客户端的响应内容
向HttpServletResponse写入文本前,同样需要指定输出编码:
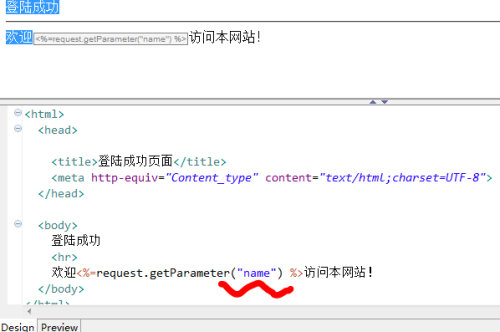
response.setContentType("text/html;charset=UTF-8");
PrintWriter out = response.getWriter();
out.println("欢迎登录系统!");
特别注意:不要混用getOutputStream()方法,因其直接操作原始字节流而不经过字符转换,极易引发二次编码问题。
Web容器全局配置强化一致性
修改web.xml部署描述符中的标准化定义,可批量约束整个应用的行为:
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>/</url-pattern>
</filter-mapping>
此配置利用Spring提供的编码过滤器,强制所有请求/响应遵循UTF-8标准,相比逐个处理每个接口,这种方式更具可维护性且不易出错,对于非Spring项目,也可自行实现类似的Servlet Filter。
数据库交互层的适配策略
当涉及持久化操作时,必须同步调整JDBC驱动层面的参数:
//建立连接后立即执行SQL语句设置客户端字符集
Statement stmt = conn.createStatement();
stmt.execute("SET NAMES utf8mb4"); //MySQL示例,不同数据库语法略有差异
PreparedStatement ps = conn.prepareStatement("INSERT INTO users...");
ps.setString(1, new String(originalByteArray, StandardCharsets.UTF_8)); //确保二进制数据按指定编码重构字符串
关键点在于数据库连接创建后应立即发送SET NAMES命令,通知数据库管理系统后续通信均采用UTF-8,在读取结果集时也要显式调用new String(bytes, charset)构造函数,避免使用默认平台编码。
开发工具链的环境匹配
许多开发者容易忽视IDE本身的区域设置影响,以IntelliJ IDEA为例:
1.进入File > Settings > Editor > File Encodings,全局设置为UTF-8;
2.针对单个模块右键菜单选择File Encoding -> Reload with Encoding -> UTF-8;
3.Maven项目的pom.xml添加插件配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
这些设置保证了源码编译阶段不会因编译器误解原始字节而产生畸形类文件。
静态资源嵌入的特殊考量
若JSP中包含外部CSS/JS文件或图片路径中含有多字节字符,应在引用处注明URI编码方式:
<link rel="stylesheet" href="styles.css?v=<%=URLEncoder.encode("中文版", "UTF-8")%>">
或者直接使用Base64内联方式规避传输损耗:
background-image: url('data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAUA...');
日志系统的透明化支持
Log4j等日志框架也需同步更新Appender配置:
log4j.appender.console.layout.ConversionPattern=%d{ISO8601} [%-5p] %c{1} %m%n
log4j.appender.console.encoding=UTF-8
否则控制台输出可能出现截断或问号代替的现象。
典型错误排查路径表
| 阶段 | 常见问题现象 | 根本原因 | 解决对策 | 验证方法 |
|---|---|---|---|---|
| 编译期 | 源文件中的正常文字变成方块 | 文件实际存储编码≠声明编码 | 确认IDE保存为UTF-8无BOM格式 | 十六进制编辑器查看文件头部是否含EFBBBF标记 |
| 传输层 | Postman测试正常但浏览器异常 | Missing contentType header |
Fiddler抓包检查HTTP Headers中的charset字段值 | Charles代理工具逐层监控TCP包内容变化 |
| 渲染阶段 | 数据库取出的数据展示错误 | Connection未设置characterSet | 启用MySQL的SHOW VARIABLES LIKE 'character_set%';命令核查 |
DataGrip执行相同SQL对比结果差异 |
相关问答FAQs
Q1: 如果已经按照上述步骤操作但仍出现乱码怎么办?
A: 建议按顺序执行以下诊断步骤:①使用Wireshark抓包分析HTTP请求头的Actual Content-Type;②在JSP首行插入<%=System.getProperty("file.encoding")%>打印JVM默认编码;③编写最小化复现案例排除干扰因素;④启用Tomcat的访问日志记录完整请求信息(修改conf/server.xml添加debug=”true”),多数情况下,这种系统性排查能定位到被忽略的细节错误。
Q2: 为什么有时本地运行正常部署到生产环境就出现乱码?
A: 这是由于不同操作系统默认的区域设置差异所致,Linux服务器通常默认使用en_US.UTF-8 locale,而Windows可能是zh_CN.GBK,解决方案是在启动脚本中显式指定JAVA_TOOL_OPTIONS环境变量:JAVA_TOOL_OPTIONS="-Dfile.encoding=UTF-8",并通过locale命令验证系统语言环境是否符合预期,Docker容器也需要在Dockerfile中加入ENV设置保证跨平台