上一篇
导入的java中文乱码怎么解决
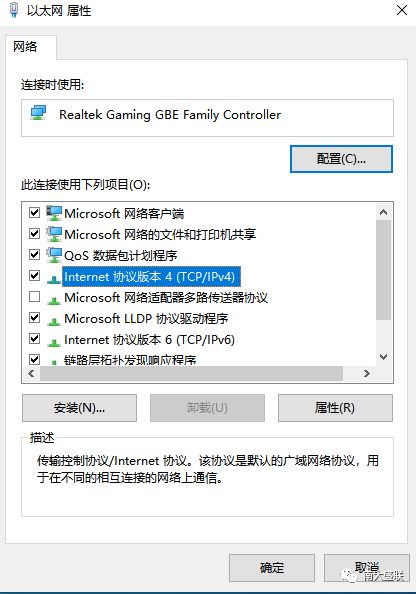
解决Java导入中文乱码需统一编码:源码文件存为UTF-8,编译/运行时加
-Dfile.encoding=UTF-8,IDE配置项目
编码为UTF-8,数据库连接串添加`useUnicode=true&characterEncoding
在Java开发中,中文乱码是一个常见且棘手的问题,其本质是字符编码与解码不一致导致的,以下从底层原理到具体场景,结合代码示例、配置方法和排查技巧,系统性地讲解如何解决这一问题。
核心概念:字符编码的本质
计算机只能识别二进制数据(0/1),而人类可读的文本需通过编码规则转换为二进制,常见编码包括:
| 编码类型 | 特点 | 典型场景 |
|—————-|———————————————————————-|————————|
| ASCII | 单字节,仅支持英文符号 | 早期系统基础 |
| GBK/GB2312 | 双字节,中文兼容ASCII | Windows简体中文版默认 |
| UTF-8 | 变长字节(1-4字节),全球通用,兼容ASCII | Web/移动设备主流 |
| ISO-8859-1 | 西欧语言专用 | 老旧欧洲系统 |
关键原则:编码(写入)与解码(读取)必须使用相同编码,否则会出现乱码,用UTF-8写入的数据,若用GBK读取,必然乱码。
全链路排查与解决方案
开发环境配置(IDE & JVM)
问题表现:直接运行main方法时中文正常,但打包成JAR后乱码;或IDE内控制台输出乱码。
| 环节 | 解决方案 | 示例(IntelliJ IDEA) |
|---|---|---|
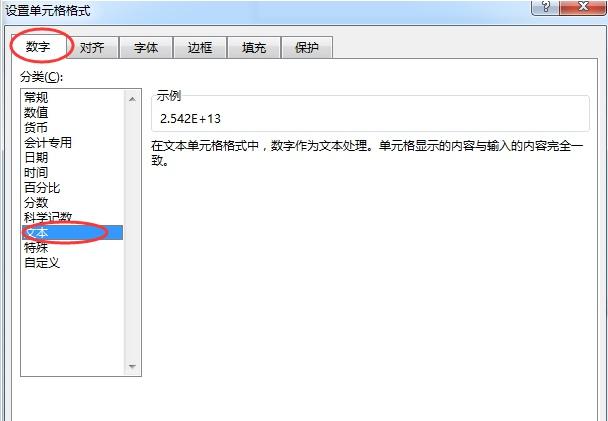
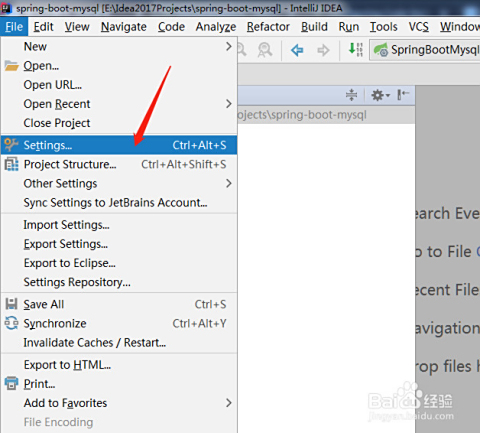
| 项目编码设置 | 确保项目全局编码为UTF-8 | File → Settings → Editor → File Encodings |
| JVM参数 | 启动参数添加-Dfile.encoding=UTF-8 |
运行配置中VM Options栏 |
| 控制台编码 | Windows CMD默认GBK,需主动切换或强制JVM使用UTF-8 | chcp 65001(临时切换CMD编码) |
| 日志/调试输出 | 配置日志框架(Logback/Log4j)的PatternLayoutEncoder为UTF-8 | <encoder class="...">标签内设置编码 |
代码验证:
public class TestEncoding {
public static void main(String[] args) {
String chineseText = "你好世界";
byte[] utf8Bytes = chineseText.getBytes(StandardCharsets.UTF_8); // 正确编码
byte[] gbkBytes = chineseText.getBytes(Charset.forName("GBK")); // 错误编码(模拟乱码)
// 解码时必须匹配编码
String fromUtf8 = new String(utf8Bytes, StandardCharsets.UTF_8); // 正常
String fromGbk = new String(gbkBytes, StandardCharsets.UTF_8); // 乱码!
System.out.println(fromUtf8); // 输出:你好世界
System.out.println(fromGbk); // 输出:港å¨çæ§
}
}
文件I/O操作
高频场景:读取/写入本地文件、CSV/Excel文件时乱码。

| 操作类型 | 错误写法 | 正确写法 | 说明 |
|---|---|---|---|
| 读取文本文件 | new FileReader("data.txt") |
new InputStreamReader(new FileInputStream("data.txt"), StandardCharsets.UTF_8) |
FileReader使用平台默认编码(Windows为GBK),需显式指定UTF-8 |
| 写入文本文件 | new FileWriter("output.txt") |
new OutputStreamWriter(new FileOutputStream("output.txt"), StandardCharsets.UTF_8) |
同上,避免依赖平台默认编码 |
| 读取二进制文件 | DataInputStream直接读文本 |
先用ByteStream读入字节,再用new String(bytes, Charset)解码 |
适用于图片/PDF等含文本的二进制文件 |
完整示例:
import java.io.;
import java.nio.charset.StandardCharsets;
public class FileIOExample {
public static void main(String[] args) throws IOException {
// 写入UTF-8文件
try (OutputStreamWriter writer = new OutputStreamWriter(
new FileOutputStream("output.txt"), StandardCharsets.UTF_8)) {
writer.write("中文测试");
}
// 读取UTF-8文件
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream("output.txt"), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line); // 输出:中文测试
}
}
}
}
数据库交互
典型问题:MySQL/PostgreSQL中存储的中文在Java中读取为乱码。
| 环节 | 错误原因 | 解决方案 |
|---|---|---|
| 数据库表设计 | 未设置表/字段的字符集为UTF-8 | 创建表时指定DEFAULT CHARSET=utf8mb4(MySQL)或utf8(PostgreSQL) |
| JDBC连接URL | URL未包含字符集参数 | 添加?useUnicode=true&characterEncoding=UTF-8(MySQL示例) |
| PreparedStatement | 未显式设置参数编码 | ps.setString(index, "中文", "UTF-8") |
| 结果集获取 | rs.getString()依赖数据库默认编码 |
显式指定编码:new String(rs.getBytes(columnIndex), "UTF-8") |
MySQL示例:
// 正确连接字符串(含UTF-8参数)
String url = "jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC";
Connection conn = DriverManager.getConnection(url, "user", "pass");
// 插入中文
String sql = "INSERT INTO test(name) VALUES(?)";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setString(1, "张三", "UTF-8"); // 显式设置参数编码
ps.executeUpdate();
// 查询中文
ResultSet rs = conn.createStatement().executeQuery("SELECT name FROM test");
while (rs.next()) {
// 方式1:依赖数据库返回的编码(需确认数据库已设为UTF-8)
String name1 = rs.getString("name");
// 方式2:强制按UTF-8解码(更可靠)
byte[] bytes = rs.getBytes("name");
String name2 = new String(bytes, "UTF-8");
System.out.println(name1 + " | " + name2); // 均应输出:张三
}
Web应用(Servlet/JSP)
常见问题:浏览器显示中文乱码,或表单提交后后台接收乱码。
| 环节 | 解决方案 | 示例(Servlet) |
|---|---|---|
| 请求参数解码 | 设置request.setCharacterEncoding("UTF-8")(需在getParameter前调用) |
request.setCharacterEncoding("UTF-8"); String name = request.getParameter("name"); |
| 响应头设置 | 设置response.setContentType("text/html;charset=UTF-8") |
防止浏览器自动选择错误编码 |
| JSP页面声明 | 页首添加<%@ page contentType="text/html;charset=UTF-8" %> |
确保JSP输出的HTTP头正确 |
| 静态资源(CSS/JS) | 确保文件本身是UTF-8编码,且服务器返回的Content-Type头包含charset=UTF-8 |
可在Web服务器(Nginx/Tomcat)中配置 |
Spring Boot示例:
@RestController
public class UserController {
@PostMapping("/login")
public String login(@RequestParam String username, @RequestParam String password) {
// 确保请求参数已按UTF-8解码(Tomcat默认已处理,若用其他容器需手动设置)
return "欢迎:" + username; // 响应会自动设置Content-Type为UTF-8(需配置)
}
}
需在application.properties中添加:
spring.http.encoding.charset=UTF-8 spring.http.encoding.enabled=true spring.messages.encoding=UTF-8
JSON/XML序列化与反序列化
问题场景:Fastjson/Jackson库处理中文时出现乱码。
| 库 | 解决方案 | 示例(Fastjson) |
|---|---|---|
| Fastjson | 创建ParserConfig并设置Features.AllowUnEscapedUnicodeSymbols |
ParserConfig.getGlobalInstance().setCharset(StandardCharsets.UTF_8); |
| Jackson | 配置ObjectMapper的getFactory().configure(JsonGenerator.Feature.ESCAPE_NON_ASCII, true) |
避免转义非ASCII字符导致的截断 |
| Gson | 构造函数传入new GsonBuilder().create()(默认使用UTF-8) |
无需额外配置 |
Fastjson示例:
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.ParserConfig;
import java.nio.charset.StandardCharsets;
public class JsonExample {
public static void main(String[] args) {
// 全局配置(影响所有解析器)
ParserConfig.getGlobalInstance().setCharset(StandardCharsets.UTF_8);
String jsonStr = "{"name":"李四"}";
// 反序列化(自动使用UTF-8)
MyUser user = JSON.parseObject(jsonStr, MyUser.class);
System.out.println(user.getName()); // 输出:李四
// 序列化(默认UTF-8)
String newJson = JSON.toJSONString(user);
System.out.println(newJson); // 输出:{"name":"李四"}
}
static class MyUser { private String name; public String getName() { return name; } }
}
终极排查工具包
当上述方法无效时,可通过以下工具定位问题根源:
| 工具/方法 | 作用 | 使用方法 |
|————————-|————————————————————————–|————————————————————————–|
| System.out.println(Arrays.toString(str.getBytes())) | 查看字符串的实际字节序列 | 对比UTF-8标准字节表(如“你”的UTF-8是E4BDA0) |
| Wireshark | 抓包分析网络传输的字节流 | 检查HTTP请求/响应体的原始字节是否符合UTF-8 |
| Hex Editor | 直接查看文件/数据库blob字段的十六进制内容 | 确认存储的字节是否为UTF-8编码(非乱码后的畸形字节) |
| locale -a(Linux) | 查看系统支持的所有本地化设置 | 排查操作系统层面的编码限制 |
| Maven依赖树 | 检查是否有冲突的编码相关依赖(如旧版commons-lang) | mvn dependency:tree |
常见误区警示
- 误认为
String本身存储编码:Java的String是无状态的Unicode字符序列,不携带编码信息,乱码只发生在字节与字符的转换过程(如I/O、网络传输)。 - 忽略中间件的默认行为:Tomcat默认请求编码为ISO-8859-1,需手动设置为UTF-8(修改
server.xml的URIEncoding="UTF-8")。 - 混合使用不同编码的工具:用记事本(ANSI)编辑的Java文件,即使IDE显示正常,编译后仍可能因原始字节非UTF-8而导致乱码。
- 过度依赖IDE自动转换:部分IDE会在保存时自动转换编码,但可能导致版本控制系统(如Git)中的文件实际编码与IDE显示不一致。
FAQs
Q1: 我已经在代码中全部使用了UTF-8,为什么还是有乱码?
A: 可能遗漏了以下环节之一:① JVM启动参数未设置-Dfile.encoding=UTF-8;② 数据库连接URL缺少characterEncoding=UTF-8;③ Web服务器(如Tomcat)的server.xml未设置URIEncoding="UTF-8";④ 静态资源(如JS/CSS)未以UTF-8编码保存,建议逐层检查整个数据处理链路的编码一致性。
Q2: 旧项目有很多GBK编码的文件,如何安全迁移到UTF-8?
A: 分两步操作:① 使用工具(如Notepad++、iconv命令)批量将文件从GBK转换为UTF-8(注意备份);② 修改项目配置(如IDE编码、JVM参数)为UTF-8,转换后需全面测试功能,尤其是涉及字符串比较、正则表达式的部分(因UTF-8和GBK的字节长度不同可能导致逻辑错误),示例命令:`iconv -f GBK -t UTF-8 old_file.java > new_file