上一篇
怎么从数据库中读取分类
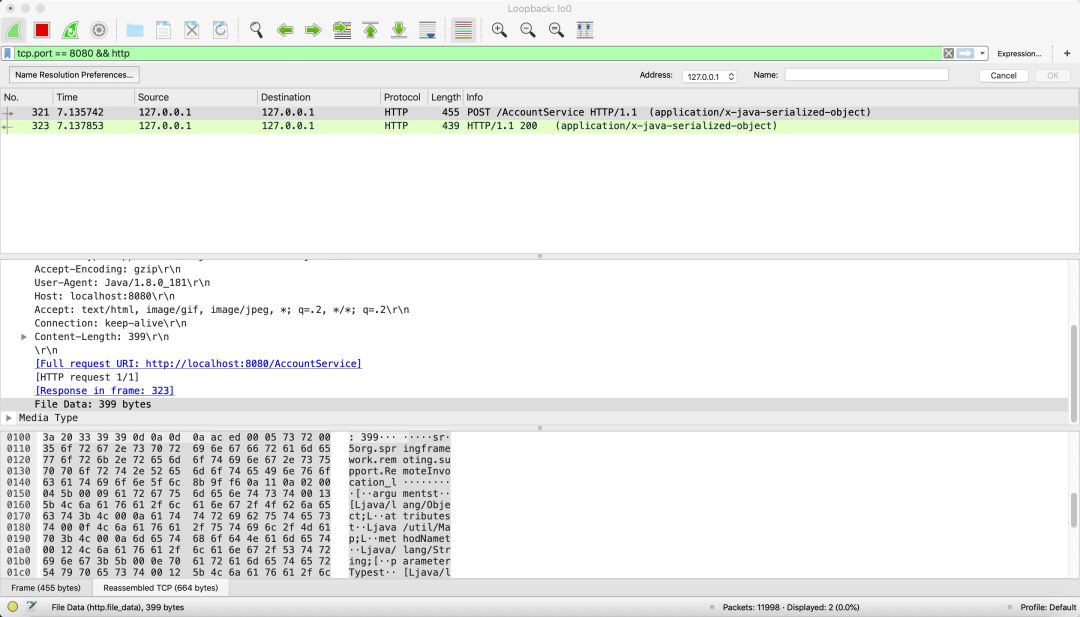
SQL 语句(如
SELECT FROM table WHERE category='某类')或编程接口按分类条件查询数据库
数据库中读取分类数据是信息系统开发中的常见需求,其实现方式取决于数据库类型、表结构设计以及业务场景的具体特点,以下是详细的技术实现步骤和最佳实践方案:
基础方法与核心原理
-
SQL语句构建
- 直接查询法:通过
SELECT FROM category_table WHERE category_id = X获取指定分类的完整记录,若需层级关系,可扩展为递归查询(如MySQL的WITH RECURSIVE语法)。 - 父子关联查询:使用自连接或嵌套子查询实现多级分类展示,例如查找某个分类的所有子类时,可用
SELECT FROM category WHERE parent_id = <上级ID>;反向查找父节点则通过SELECT FROM category WHERE id = <当前ID> AND parent_id != 0实现。 - 范围筛选优化:采用相关子查询技术限定结果集范围,类似
SELECT ProductID, Name FROM Product AS P1 WHERE (SELECT COUNT() FROM Product AS P2 WHERE P1.ProductID >= P2.ProductID) BETWEEN 6 AND 10 ORDER BY ProductID的逻辑可移植到分类场景。
- 直接查询法:通过
-
索引策略配置
- 单列索引:在分类ID字段建立B+树索引,加速等值查询和排序操作,这是最基础的优化手段,适用于高频访问的主键检索。
- 复合索引设计:针对同时涉及多个过滤条件的复杂查询(如按父类+状态筛选),创建多列联合索引能显著提升性能,例如
(parent_id, is_active)的组合键设置。 - 全文检索支持:当需要基于分类名称进行模糊匹配时,可启用全文索引功能,特别适合电商网站的搜索框自动补全场景。
-
数据建模规范
- 规范化设计:遵循范式理论创建独立的分类表,包含元数据字段(如创建时间、更新标记)、层级关系指针(parent_id)、业务属性扩展区等标准化结构,这种设计有利于维护数据完整性,避免冗余存储。
- 预分配代理键:使用自增主键作为唯一标识符,既保证写入顺序又便于缓存命中,相比自然业务号,数据库生成的ID具有更好的局部性原理特性。
- 闭包表模式:对于存在多级嵌套的大型分类体系,建议单独建立路径关系表存储所有祖先节点信息,以空间换时间的方案解决深度遍历效率问题。
高级处理技巧
| 技术维度 | 实现要点 | 适用场景 |
|---|---|---|
| 缓存机制 | Redis分布式锁保障并发安全,二级缓存预热热点分类数据 | 高并发读操作 |
| 批量加载 | ORM框架的延迟加载特性配合N+1问题消除策略 | 列表页分页展示 |
| 异步刷新 | 消息队列监听变更事件,异步更新缓存层与搜索引擎索引 | 实时性要求不高的业务模块 |
| 视图虚拟化 | 物化视图定期刷新聚合统计结果,减少实时计算压力 | 数据分析看板 |
性能调优路径
- 执行计划分析:定期使用EXPLAIN命令检查查询执行路径,重点关注扫描行数与索引利用率指标,若发现全表扫描现象,应及时补充缺失索引或重构SQL逻辑。
- 分区裁剪:针对海量数据的超大型系统,按时间范围或区域代码进行水平分区,使查询引擎能快速定位有效数据集,例如按月份划分的销售品类统计表。
- 连接算法选择:JOIN操作优先选用哈希连接而非嵌套循环,尤其在处理大表关联时效果更明显,可通过调整数据库参数指定特定连接策略。
典型错误规避指南
- 过度联表陷阱:避免单个SQL跨过多表连接导致笛卡尔积爆炸,建议拆分复杂查询为多个简单步骤执行。
- 脏读风险防控:事务隔离级别设置不当可能引发幻读问题,特别是可重复读级别下仍无法完全避免插入冲突时,应考虑乐观锁机制。
- 字符集兼容性:多语言环境下确保排序规则统一,防止因校对规则差异导致乱序结果,推荐使用utf8mb4字符集并配置合适的collation设置。
FAQs
Q1:如何处理多级分类的无限层级展示?
A:推荐采用闭包表方案存储所有祖先路径,配合递归CTE(公共表达式)实现高效遍历,对于固定深度的结构,也可预先计算每层的缩进量辅助前端渲染。

Q2:大量并发请求下如何保证分类数据的一致性?
A:采用分布式锁(如Redis RedLock算法)控制写操作原子性,结合版本号乐观并发控制机制,读操作可通过负载均衡分散到多个副本节点,利用只读实例减轻主库