上一篇
如何在Java中读取HTML?
在Java中读取HTML文件,可通过FileReader和BufferedReader逐行读取,或使用第三方库如Jsoup解析HTML内容,核心步骤包括:创建文件输入流、读取内容至字符串、关闭资源,
Jsoup还能提取特定元素,适合复杂解析需求。
在Java中读取HTML内容是一项常见任务,广泛应用于网页抓取、数据提取、自动化测试等场景,以下是几种高效可靠的方法,结合原生API和主流第三方库实现:
核心方法及代码示例
原生 java.net 包(基础HTTP请求)
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
public class ReadHtmlBasic {
public static void main(String[] args) {
try {
URL url = new URL("https://example.com");
// 获取输入流并读取内容
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(url.openStream()))) {
String line;
StringBuilder htmlContent = new StringBuilder();
while ((line = reader.readLine()) != null) {
htmlContent.append(line);
}
System.out.println(htmlContent.toString()); // 输出原始HTML
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
特点:
- 无需第三方依赖
- 仅获取静态HTML,无法执行JavaScript
- 需手动处理编码(如指定
"UTF-8")
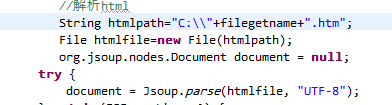
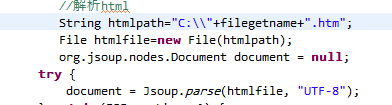
Jsoup(HTML解析库)
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ReadHtmlJsoup {
public static void main(String[] args) {
try {
// 直接解析URL或HTML字符串
Document doc = Jsoup.connect("https://example.com").get();
// 提取标题
String title = doc.title();
System.out.println("标题: " + title);
// 提取所有链接
doc.select("a[href]").forEach(link -> {
System.out.println("链接: " + link.attr("href"));
});
} catch (Exception e) {
e.printStackTrace();
}
}
}
优势:
- 支持CSS选择器,精准提取元素
- 自动处理编码和HTML格式化
- 可清理用户输入的HTML(防XSS)
HtmlUnit(模拟浏览器行为)
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class ReadHtmlDynamic {
public static void main(String[] args) {
try (WebClient webClient = new WebClient()) {
webClient.getOptions().setJavaScriptEnabled(true); // 启用JS
webClient.waitForBackgroundJavaScript(5000); // 等待JS执行
HtmlPage page = webClient.getPage("https://example.com");
String renderedHtml = page.asXml(); // 获取渲染后的HTML
System.out.println(renderedHtml);
} catch (Exception e) {
e.printStackTrace();
}
}
}
适用场景:

- 处理动态内容(如React/Angular生成的页面)
- 模拟点击、表单提交等交互
- 需牺牲性能换取完整性
方法对比与选型建议
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
java.net |
快速获取静态HTML | 无依赖、轻量级 | 功能有限,需手动解析 |
| Jsoup | 数据提取、清洗 | 语法简洁,解析能力强 | 不支持JavaScript |
| HtmlUnit | 动态页面、自动化测试 | 完整浏览器模拟 | 速度慢,资源占用高 |
选型原则:
- 静态页面 → Jsoup(首选,高效易用)
- 动态渲染 → HtmlUnit 或 Selenium
- 基础需求 → 原生
java.net
关键注意事项
-
异常处理
网络请求需捕获IOException、MalformedURLException等异常,建议添加重试机制。 -
编码问题
明确指定字符集(如InputStreamReader(stream, "UTF-8")),避免乱码。 -
限制
若目标页面依赖AJAX,需结合 Selenium 或 HtmlUnit 等工具。 -
遵守Robots协议
检查目标网站的robots.txt,避免违法抓取。 -
反爬虫策略
设置请求头模拟浏览器访问:Jsoup.connect(url) .userAgent("Mozilla/5.0") .timeout(10000) .get();
- 简单文本提取 → 原生
java.net+ 正则表达式(不推荐复杂解析)。 - 结构化数据抓取 → Jsoup(最佳平衡点)。
- 动态页面处理 → HtmlUnit 或 Selenium(需权衡性能)。
选择合适工具需结合目标页面特性及开发效率,对于生产环境,建议优先使用 Jsoup 处理静态内容,动态场景配合 HtmlUnit 确保数据完整性。
引用说明:
- Jsoup官方文档
- HtmlUnit官网
- Oracle java.net文档