上一篇
数据库空库怎么导
空数据库后,用工具(如Navicat)或命令行执行SQL脚本导入结构与初始数据,确保字符集
是关于数据库空库导入的详细操作指南,涵盖不同场景下的实现方法和注意事项:
通用准备阶段
-
环境确认
- 确保目标服务器已安装对应类型的数据库管理系统(如MySQL/SQL Server/Oracle等),并具备管理员权限,建议提前检查版本兼容性,例如从旧版迁移至新版时可能需要额外参数支持。
- 关闭防火墙或设置白名单,允许必要的端口通信,若涉及远程操作,需验证网络连通性及认证方式(如Windows身份验证与SQL账户的区别)。
-
源数据校验
- 对即将导入的数据文件进行完整性检查,包括文件大小、编码格式(推荐UTF-8无BOM)、特殊字符转义处理等,可使用十六进制编辑器查看头部信息是否符合预期结构。
- 若为多分卷压缩包,建议先本地解压测试后再执行线上操作,对于加密文件,需提前获取解密密钥并测试解密流程。
-
存储规划
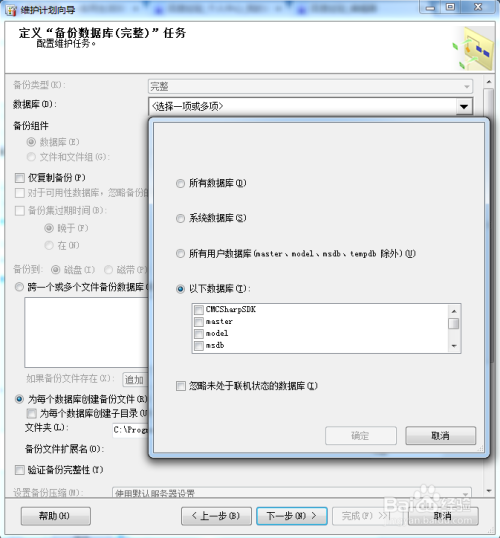
- 根据预估数据量分配合理的磁盘空间,以SQL Server为例,创建数据库时可通过T-SQL脚本精确控制初始大小、最大容量和增长步长:
CREATE DATABASE [DBName] ON PRIMARY (NAME=N'DBName', FILENAME='C:DataDBName.mdf', SIZE=20MB, MAXSIZE=50MB, FILEGROWTH=10MB) LOG ON (NAME=N'DBName_log', FILENAME='C:DataDBName_log.ldf', SIZE=5MB, MAXSIZE=10MB); - 考虑分离事务日志文件与数据文件的物理存放路径,避免I/O争用影响性能。
- 根据预估数据量分配合理的磁盘空间,以SQL Server为例,创建数据库时可通过T-SQL脚本精确控制初始大小、最大容量和增长步长:
主流数据库实施方案对比
| 数据库类型 | 核心工具 | 典型命令示例 | 关键参数说明 |
|---|---|---|---|
| SQL Server | BCP + T-SQL | bcp AdventureWorks2012.Production.ProductModel out C:tempmodel.txt -S serverName -T -c |
-S指定服务器实例,-T启用信任连接 |
| Oracle | expdp/impdp | expdp system/password@orcl DIRECTORY=dpump CONTENT=METADATA_ONLY SCHEMAS=hr |
CONTENT模式仅导出对象定义 |
| MySQL | mysql客户端 |
mysql -u root -p your_database < backup.sql |
优先执行DROP TABLE避免残留依赖 |
| PostgreSQL | pg_restore |
pg_restore -U postgres -d newdb -v latest_backup.dump |
-v开启详细日志输出便于排查错误 |
高级实施要点
-
对象创建顺序控制
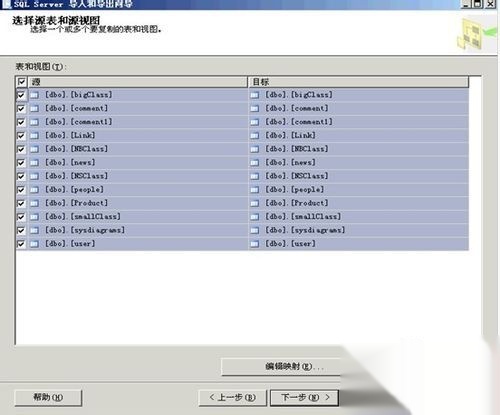
- 当导入包含多个关联对象的脚本时(如视图依赖基础表),必须严格按照“先建底层结构→再上层应用”的顺序执行,可通过拆分SQL文件或使用事务回滚机制保障原子性操作。
- 示例:在MySQL中采用
source命令分步执行:SET FOREIGN_KEY_CHECKS=0; source schema.sql; source data.sql; SET FOREIGN_KEY_CHECKS=1;
-
大数据量优化策略
- 批量插入技术:禁用索引后批量导入再重建,可将速度提升数倍,例如在PostgreSQL中使用
ALTER TABLE tablename DISABLE TRIGGER ALL;配合COPY命令。 - 并行加载机制:利用多线程工具如mydumper实现分块传输,特别适合跨地域灾备场景下的断点续传需求。
- 批量插入技术:禁用索引后批量导入再重建,可将速度提升数倍,例如在PostgreSQL中使用
-
约束处理方案

- 临时关闭唯一性校验:针对历史遗留数据的主键冲突问题,可采用
TRUNCATE TABLE替代DELETE语句快速清空目标表。 - 外键级联删除配置:通过
ON DELETE CASCADE属性自动维护引用完整性,减少手动干预成本。
- 临时关闭唯一性校验:针对历史遗留数据的主键冲突问题,可采用
异常处置预案
| 错误类型 | 根本原因分析 | 解决方案 |
|---|---|---|
| 字符集不匹配 | 源文件编码与数据库默认字符集不一致 | 修改连接字符串添加Charset=utf8mb4参数 |
| 权限拒绝 | 执行用户缺乏必要操作许可 | 授予db_owner角色或调整安全策略 |
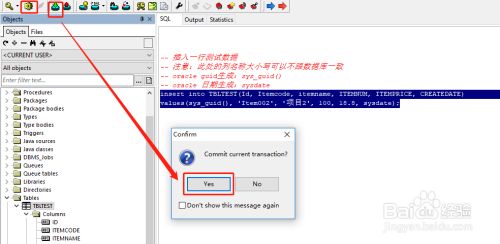
| 内存溢出 | 单次提交事务过大导致缓冲区不足 | 分割大事务为多个小批次提交 |
| 锁等待超时 | 高并发写入引发行级锁竞争 | 启用乐观锁机制或调整隔离级别 |
验证与收尾工作
- 结构一致性核查:比对源库与目标库的系统表元数据,重点检查存储引擎类型、排序规则等隐蔽参数是否一致,推荐使用DBDiff工具自动化对比过程。
- 功能回归测试:随机抽取关键业务场景进行端到端验证,确保触发器、存储过程等高级特性正常生效,特别注意时区转换相关的函数行为差异。
- 监控指标观察:持续关注CPU利用率、磁盘IOPS、锁等待统计等性能指标至少24小时,确认系统处于稳态后方可对外开放服务。
FAQs:
Q1: 如果导入过程中出现“重复键值违反唯一约束”该怎么办?
A: 这种情况通常由目标表中已存在相同主键记录导致,解决方法包括:①使用IGNORE INTO语法跳过错误行;②先执行TRUNCATE TABLE彻底清空旧数据;③手动修正冲突的主键值后再试,建议优先采用第二种方案保证数据纯净度。
Q2: 如何判断大型SQL脚本是否成功执行完毕?
A: 可以通过以下三种方式确认:①检查返回码是否为0;②查询information_schema.processlist确认无残留会话;③执行SELECT COUNT() FROM tablename;验证预期记录数是否到位,对于复杂事务,还应检查binlog的应用进度确保