上一篇
数据库怎么导入大文件
库导入大文件可采用分块处理、批量插入、专用工具或优化配置;MySQL可用
LOAD DATA INFILE高效加载
是关于如何在数据库中导入大文件的详细步骤和方法归纳,涵盖不同场景下的技术方案、优化策略及注意事项:
主流技术方案对比与实现细节
| 方法名称 | 适用场景 | 核心优势 | 典型命令/工具示例 | 注意事项 |
|---|---|---|---|---|
LOAD DATA INFILE |
结构化文本(如CSV/TSV)批量导入 | 直接解析本地文件,绕过应用程序层效率更高 | LOAD DATA INFILE '/path/to/file.csv' INTO TABLE table_name; |
需确保字段顺序与表结构严格匹配;建议先禁用索引提升速度 |
| 分块处理+批量插入 | 超大规模非结构化或半结构化数据 | 降低内存溢出风险,支持断点续传 | Python脚本配合executemany()实现每千条事务提交 |
需自定义逻辑处理异常数据行 |
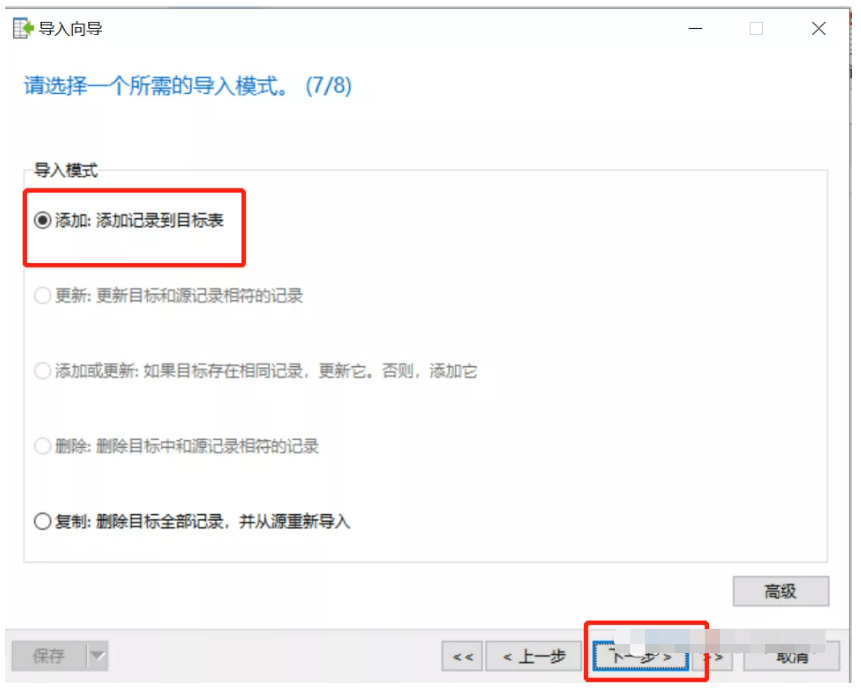
| 数据库专用导入工具 | 标准化格式迁移(如SQLDumpSplitter) | 自动化切割大文件并分段加载 | SQLDumpSplitter四步操作:选择文件→设定分卷大小→指定目录→执行分割 | 分割后的文件需按顺序合并导入 |
| 命令行客户端导入 | 快速部署与调试 | 减少GUI交互开销,适合运维自动化 | mysqlimport -u user -p dbname data.csv --fields-terminated-by=, |
字符集编码一致性校验至关重要 |
关键实施要点解析
预处理阶段
- 格式标准化:统一日期格式为
YYYY-MM-DD、数值型字段去除单位符号等,例如CSV文件中存在混合类型的列时,可通过正则表达式预清洗。 - 索引管理:在导入前执行
ALTER TABLE table_name DISABLE KEYS;临时禁用索引,导入完成后再重建,可提速约30%-50%。 - 存储引擎选择:对于MyISAM引擎表,建议采用
LOAD DATA LOCAL INFILE替代标准语法以获得更高性能。
参数调优策略
| 配置项 | 推荐值范围 | 作用说明 |
|---|---|---|
bulk_insert_buffer_size |
8M~64M | 增大缓冲区减少磁盘I/O次数 |
max_allowed_packet |
≥实际数据包大小 | 避免因默认限制导致的中断错误 |
innodb_flush_log_at_trxcommit |
2 | 权衡数据安全与写入性能 |
错误处理机制
- 事务回滚控制:设置每N条记录作为一个事务单元,发生错误时仅回滚当前批次而非整个导入过程,例如MySQL中可通过
SET autocommit=0; START TRANSACTION;实现精细控制。 - 日志记录:启用
--verbose参数输出详细执行日志,便于定位第X行出现的数据类型不匹配等问题。
进阶实践技巧
当面对TB级超大数据时,可采用多层架构设计:

- 中间件缓冲层:使用Kafka搭建消息队列,将原始文件拆解为多个消息分区异步消费。
- 分布式加载:通过ShardingSphere等框架实现水平分表,各节点并行导入后再聚合元数据。
- 压缩传输:对已排序的数据文件进行GZIP压缩传输,某些数据库支持透明解压解析(如PostgreSQL的COPY命令)。
常见误区规避指南
️ 陷阱1:盲目追求单次全量导入可能导致OOM(内存溢出),解决方案:采用“滚动窗口”模式,每次只加载可覆盖内存容量的数据块。
️ 陷阱2:忽略字符集兼容性问题引发乱码,务必在连接字符串中显式指定charset=utf8mb4等参数。
️ 陷阱3:未考虑锁竞争影响线上业务,建议在低峰期执行导入操作,或采用Online DDL工具进行在线表结构变更。
FAQs
Q1: 为什么使用LOAD DATA INFILE比逐条INSERT快这么多?
A: 因为该方法直接绕过应用程序层协议栈,由数据库引擎原生解析二进制日志文件,减少了网络往返时延和SQL编译开销,测试表明同等条件下性能差异可达两个数量级。
Q2: 遇到“The specified path is invalid”报错如何处理?
A: 此错误通常由三种原因导致:①文件实际存放路径与SQL中指定的绝对路径不一致;②MySQL服务进程无权限访问该目录;③SELinux等安全模块拦截,解决方法依次是:核对真实存储位置→修改目录权限为755→临时关闭安全