上一篇
txt怎么导入数据库
tx
t文件导入数据库可通过工具(如MySQL Workbench)、编程语言(Python)或SQL命令(BULK INSERT)实现,需先创建匹配的数据表
TXT文件导入数据库是一项常见的数据处理任务,具体操作方式会因数据库类型、数据结构和工具选择而有所不同,以下是详细的实现步骤及注意事项,涵盖多种主流方法:
通用准备流程
- 分析数据格式:检查TXT文件的分隔符(如逗号、制表符)、编码格式(UTF-8/GBK等)以及是否包含表头行,这些参数将直接影响后续解析逻辑,若字段间用空格分隔且无标题行,则需手动指定列顺序;反之若有明确的列名标注,可简化映射过程。
- 设计目标表结构:根据文件中的字段数量、类型(字符串型、数值型、日期型等)创建对应的数据库表格,特别注意特殊字符处理需求,比如引号包裹的文本可能需要转义操作,建议先在小规模样本上测试兼容性再全面部署。
- 预处理异常值:清洗无效记录(空行、注释符号开头的行为常见干扰项),统一单位标准(如时间戳格式归一化),确保每条数据的完整性和一致性,此阶段可通过正则表达式辅助定位非常规条目。
通过SQL命令直接导入(以MySQL为例)
适用于结构化程度高的简单文本文件,核心思路是利用LOAD DATA INFILE语句实现批量加载:
LOAD DATA LOCAL INFILE '/path/to/file.txt' INTO TABLE target_table_name FIELDS TERMINATED BY ',' -根据实际调整分隔符 ENCLOSED BY '"' -可选,用于带引号的字段 LINES TERMINATED BY 'n' -换行符识别 IGNORE 1 LINES -跳过首行表头(若有) (col1, col2, ...); -显式列出对应列名
️注意权限设置:默认情况下出于安全考虑禁用本地文件读取功能,需在MySQL配置文件或启动参数中添加local-infile=1启用该特性,路径应基于服务器视角而非客户端本地路径。

Python脚本自动化处理
当涉及复杂转换逻辑时,编程方案更具灵活性,典型实现如下:
-
依赖库安装:推荐组合使用
pandas进行高效解析与SQLAlchemy作为ORM框架连接各类数据库,对于特定方言的支持更优,例如PostgreSQL可用psycopg2驱动。 -
示例代码框架:
import pandas as pd from sqlalchemy import create_engine # 读取阶段:自动推断多数类型,但敏感字段建议显式声明dtype参数 df = pd.read_csv('data.txt', sep='t', header=None) # 适配制表符分割场景 # 类型强制转换示例:防止科学计数法破坏精度 df['numeric_column'] = df['numeric_column'].astype(str).str.replace('^([0-9]+).0+$', r'1') # 连接阶段:不同数据库URL模板参考官方文档 engine = create_engine('mysql+pymysql://user:pass@host:port/dbname') df.to_sql('tablename', con=engine, if_exists='append', index=False) -
性能优化技巧:分批次提交事务(每千条左右提交一次)、禁用索引预建、多线程并行写入等方式可显著提升大数据量下的执行效率,实测表明,针对百万级记录集,合理配置chunksize能使速度提高数倍。
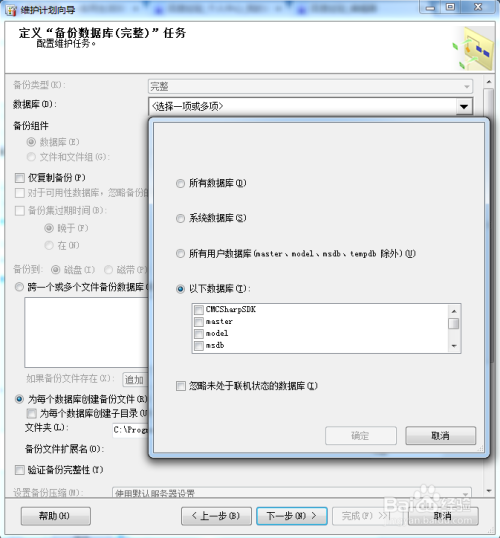
SQL Server专用工具链
微软生态体系内提供多种可视化操作途径:
| 工具 | 优势 | 适用场景 |
|———————|——————————-|——————————|
| BULK INSERT命令 | 语法简洁,执行效率高 | 纯扁平文件快速迁移 |
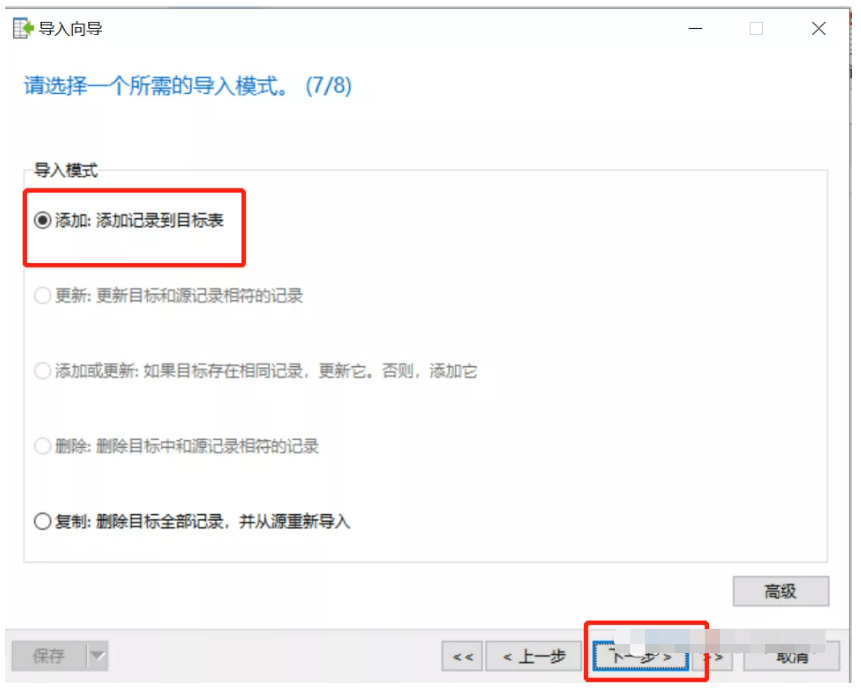
| SSMS导入向导 | 图形界面引导式配置 | 交互式调试与预览效果确认 |
| SSIS包 | 支持ETL全流程编排 | 需结合其他源系统做复杂变换时 |
其中BULK INSERT的基础用法如下:
BULK INSERT dbo.TargetTable FROM 'C:tempsource.txt' WITH (FORMATFILE = 'format.xml', FIRSTROW = 2); -第二个参数指明实际数据起始行号
配套的XML格式定义文件允许精确控制各字段映射关系,尤其适合列位置不固定的脏数据清洗场景。
常见问题排查指南
- 字符编码错误:若出现乱码现象,优先检查源文件编码声明是否正确,并在读取时显式指定encoding参数(如
encoding='gbk')。 - 主键冲突失效:批量插入时应关闭唯一性约束检查(临时),待全部完成后重新校验完整性,可通过TRUNCATE代替DELETE清空旧数据避免锁表问题。
- 性能瓶颈定位:使用EXPLAIN分析慢查询执行计划,重点关注全表扫描、文件排序等耗时操作环节,必要时建立临时索引加速关联过程。
FAQs
Q1: 如果TXT文件中某些行的列数不一致怎么办?
A: 可以通过两种方式解决:①在脚本预处理阶段填充缺失值为NULL或默认占位符;②创建表时允许可变长度的数据类型(如VARCHAR),并在应用层做容错处理,使用pandas时添加error_bad_lines=False参数可跳过非规行并记录日志。
Q2: 如何监控大型TXT文件的导入进度?
A: 对于SQL原生工具,可通过事务提交频率估算剩余工作量;而在Python脚本中,可以结合tqdm库显示动态进度条,或者定期打印