上一篇
如何将html转换成txt文件格式
文本编辑器打开HTML文件,另存为纯文本格式(.txt)即可转换。
HTML转换为TXT文件格式是一项常见的需求,尤其适用于需要提取纯文本内容而忽略样式和脚本的场景,以下是详细的操作步骤、工具推荐及注意事项:
手动复制粘贴法(适合简单页面)
- 打开HTML文件
使用浏览器(如Chrome/Edge/Firefox)直接打开目标HTML文件,此时页面会渲染出完整的图文混排效果,但广告、动态元素可能干扰操作。 - 全选并复制内容
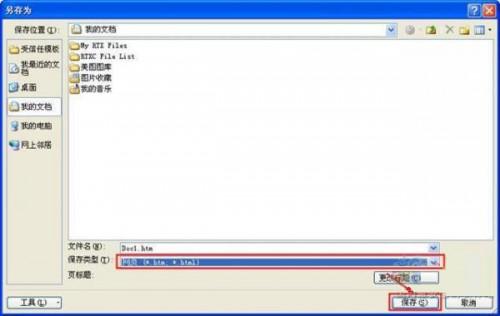
按下快捷键Ctrl+A(Windows)或Command+A(Mac)全选页面内容,然后通过Ctrl+C/Command+C复制到剪贴板,此步骤会包含所有可见文本,包括段落、标题等结构化信息。 - 新建TXT文档并粘贴
启动记事本或其他纯文本编辑器(如VS Code),创建新文件后粘贴剪贴板内容,由于TXT不支持格式标签,所有<p>、<h1>等HTML标记将被自动过滤,仅保留原始文字。 - 清理残留杂质
检查是否存在多余的空格、换行符或特殊符号(如 实体编码),手动删除非必要字符以确保文本纯净度,连续多个空行可合并为单行间距。
️注意:该方法无法处理图片中的文字(OCR需额外工具)、复杂表格结构及内联CSS样式导致的异常断句问题。
编程自动化转换(批量处理首选)
| 语言/工具 | 核心代码示例 | 优势与限制 |
|---|---|---|
| Python | python<br>from bs4 import BeautifulSoup<br>with open('input.html', 'r', encoding='utf-8') as f:<br> soup = BeautifulSoup(f, 'html.parser')<br>text = soup.get_text(' ', strip=True)<br>with open('output.txt', 'w', encoding='utf-8') as t:<br> t.write(text)<br> |
支持大规模文件处理 依赖第三方库安装 |
| Node.js | javascript<br>const fs = require('fs');<br>const cheerio = require('cheerio');<br>let $ = cheerio.load(fs.readFileSync('input.html'));<br>fs.writeFileSync('output.txt', $.text());<br> |
高性能流式处理 ️需熟悉异步编程模型 |
| 在线转换器 | 访问CloudConvert等网站上传文件即可生成TXT下载链接 | 无需本地配置 注意隐私安全风险 |
技术要点解析:BeautifulSoup的get_text()方法可通过参数控制空白符处理策略,设置strip=True能自动去除多余空白;Cheerio则模拟jQuery选择器实现精准内容定位。

进阶技巧:保留语义结构的优化方案
对于需要维持章节层级关系的文档(如电子书),建议采用以下增强型策略:
- 标记化输出
在提取文本时插入人工分隔符,例如用“====CHAPTER N====”标注章节标题,帮助后续排版软件识别逻辑结构。 - 元数据植入
通过正则表达式匹配<meta name="description">等关键标签,将重要元信息附加到TXT头部作为注释块。 - 编码规范化
统一指定UTF-8无BOM编码保存文件,避免不同系统间的乱码问题,可在Python中使用encoding='utf-8-sig'参数实现。
典型错误排查指南
| 现象 | 原因分析 | 解决方案 |
|---|---|---|
| 乱码 | 源文件编码与解析器不匹配 | 显式声明编码方式(如<meta charset="UTF-8">) |
| 缺失部分内容 | JavaScript动态加载的内容未被捕获 | 改用Selenium等带渲染引擎的工具 |
| 多余空白行 | HTML中的<br/>标签被转换 |
预处理阶段移除冗余换行符 |
FAQs
Q1: 为什么转换后的TXT文件出现大量空白段落?
A: 这是由于HTML源码中存在多余的<p>空标签或连续换行符所致,解决方案是在代码层面过滤无效标签,例如使用BeautifulSoup时设置decompose(['br'])移除所有换行标记,或者在保存前执行正则替换/n{3,}/g压缩多余空行。
Q2: 能否保留原始链接供参考?
A: 标准TXT格式不支持超链接锚点,但可通过附录形式实现,具体做法是将<a href="url">锚文本</a>转换为“锚文本”格式的Markdown式写法,既保持可读性又留存网络线索,这需要定制化解析规则来实现特定语法转换。
通过上述方法组合运用,可实现从基础到高级的HTML转TXT全流程控制,实际实施时建议先进行小样本测试,根据文档特点调整解析策略,最终达到理想的文本