上一篇
如何将txt转换为html格式 c
txt转HTML可用文本编辑器创建基础结构后另存为HTML格式,或用在线工具快速转换。
理解核心原理
HTML(超文本标记语言)通过标签定义内容的结构和样式,而TXT是纯文本无格式文件,转换的本质是为文本添加HTML标签(如段落<p><h1>-<h6>、换行<br/>等),使其能被浏览器解析为结构化页面,关键在于:保留原文本的信息完整性(包括空格、缩进、特殊符号),同时用合适的标签还原逻辑层次。
分步实现方法
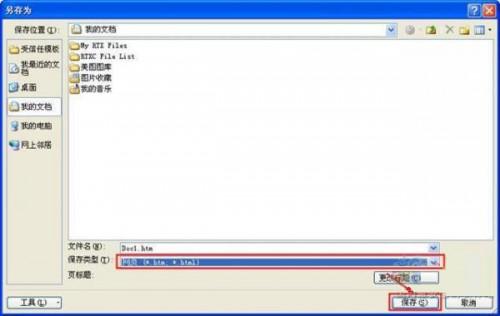
方法1:手动编写(适合简单内容) 较短且结构单一(如一首诗、短文),可直接用文本编辑器(记事本/VS Code)逐行添加标签。
今日天气晴朗,适合出游。
推荐地点:公园、湖边。
注意事项:携带防晒用品。转换为HTML后:
<!DOCTYPE html>
<html>
<head>每日提醒</title>
<meta charset="UTF-8">
</head>
<body>
<h2>今日提示</h2>
<p>今日天气晴朗,适合出游。</p>
<ul>
<li>推荐地点:公园、湖边。</li>
<li>注意事项:携带防晒用品。</li>
</ul>
</body>
</html>
技巧:用<p>包裹段落,<h1>-<h6>等级,<ul>/<ol>列表增强可读性;特殊字符(如&符号需转为&)需转义以避免解析错误,此方法灵活但效率低,仅适用于少量文本。
方法2:使用专用转换工具(高效通用)
市面上有多种工具支持批量转换,以下按类型分类推荐:
① 桌面软件(本地处理更安全)
- Pandoc(跨平台):命令行神器,支持多格式互转,安装后在终端输入:
pandoc input.txt -o output.html
高级参数可控制样式(如--css=style.css引用外部样式表)、插入目录(--toc),其优势在于精准保留Markdown语法(若TXT含类似标记),适合技术用户。 - Word/WPS间接法:打开TXT→另存为DOCX→再另存为HTML,虽多了一步,但能利用办公软件的自动分段、图片嵌入功能(若原TXT有路径描述),适合包含复杂元素的文档。
② 在线转换器(无需安装,即开即用)
访问CloudConvert、OnlineConvertFree等网站,上传TXT文件后选择“转为HTML”,部分工具提供预览功能,可实时调整字体、颜色等基础样式,注意:敏感文件避免上传公共平台!
③ 编程脚本(自动化批量处理)
用Python的BeautifulSoup或lxml库编写脚本,适合处理大量文件,示例代码如下:

from bs4 import BeautifulSoup
def txt_to_html(input_path, output_path):
with open(input_path, 'r', encoding='utf-8') as f:
content = f.read()
# 分割段落(按双换行符)
paragraphs = content.split('nn')
html = f"""<!DOCTYPE html>
<html><head><title>{input_path[:-4]}</title></head><body>"""
for p in paragraphs:
html += f"<p>{p.strip()}</p>" # strip去除首尾空格
html += "</body></html>"
with open(output_path, 'w', encoding='utf-8') as f:
f.write(html)
# 调用函数(示例:将test.txt转为test.html)
txt_to_html('c:/test.txt', 'c:/test.html')
此脚本按双换行分割段落,自动生成基础HTML框架,可通过修改逻辑适配更复杂的分段规则(如单换行为<br/>)。
关键注意事项
- 编码统一:确保TXT和HTML均使用UTF-8编码,避免中文乱码(尤其在Windows系统下,部分旧版软件默认ANSI编码)。
- 特殊字符处理:HTML中
<,>,&等符号会被视为标签起始符,必须转义为<,>,&,原文本中的“5>3”应写为“5>3”。 - 样式分离:若需统一外观(如字体大小、行距),建议将CSS单独存放在
<style>标签或外部文件中,通过类名引用(如<p class="main-text">),便于后期维护。 - 链接与图片:若TXT包含网址或图片路径,可在HTML中用
<a href="url">超链接</a>和<img src="image.jpg" alt="描述">补充多媒体元素。
效果验证与调试
完成转换后,用浏览器打开HTML文件检查:
- 是否所有文本都正确显示?有无截断或重叠?
- 段落间距、缩进是否符合预期?(可通过CSS的
margin/padding调整) - 特殊符号是否被正确转义?(浏览器开发者工具[F12]可查看源码验证)
若发现问题,优先检查原始TXT中的异常字符(如全角半角混用),或调整转换工具的参数(如Pandoc的--wrap=none禁止自动换行)。
相关问答FAQs
Q1:转换后的HTML在不同浏览器中显示不一致怎么办?
A:这是由于浏览器对CSS解析的差异导致的,解决方法有两种:①使用标准化的CSS重置样式表(如Normalize.css);②指定目标浏览器的私有前缀(如-webkit-针对Chrome/Safari),或通过工具Can I use?查询兼容性,推荐优先使用跨浏览器支持的基础属性(如font-size: 16px;而非实验性特性)。
Q2:TXT中有表格数据(用竖线/制表符分隔),如何转换为HTML表格?
A:若表格结构规则(如每行列数固定),可用正则表达式提取数据后生成<table>标签,以制表符分隔为例,Python脚本示例:
import re
rows = re.split(r't+', line) # 按制表符分割每行的单元格
html_table = "<table border='1'><tr>" + "".join([f"<th>{cell}</th>" for cell in header]) + "</tr>"
for row in data_rows:
html_table += "<tr>" + "".join([f"<td>{cell}</td>" for cell in row]) + "</tr>"
html_table += "</table>"
其中header是表头行,data_rows是数据行列表,复杂表格建议先用Excel整理,再导出