上一篇
导入java文件乱码怎么解决
导入Java文件乱码多因编码不匹配所致,可将
文件转为UTF-8编码,并在IDE中设置项目及文件编码为UTF-8,读取时用`new String(bytes, StandardCharsets.
当您遇到导入Java文件时出现乱码现象,通常是由于字符编码不匹配导致的,以下是系统性的解决方案、原因分析和实践指南,涵盖从开发环境到运行环境的全流程排查与修复方法。
核心原因定位
| 层级 | 典型表现 | 根本原因 |
|---|---|---|
| 文件存储层 | 源代码文件中的中文显示为方块/问号 | 文件实际编码(如ANSI/GBK)与声明编码(如UTF-8)不一致 |
| ️ 开发工具层 | IDE内查看正常但编译后输出乱码 | IDE未统一设置项目/模块的字符编码 |
| 编译构建层 | 命令行编译报错或生成物含乱码 | javac未显式指定输入/输出编码参数 |
| 运行环境层 | JAR包在不同机器上运行结果异常 | JVM启动参数未强制指定文件编码,依赖系统默认Locale设置 |
| 打包发布层 | 资源文件(图片/XML)加载失败 | Maven/Gradle未统一资源过滤时的编码策略 |
分步解决方案
文件存储层治理(根源性修复)
-
检测现有文件真实编码
使用十六进制编辑器(推荐HxD)查看文件头部字节特征:- UTF-8:EF BB BF (BOM头) 或直接以
FF开头 - GBK/ANSI:
FF FE(Unicode Little Endian)或其他非标准序列
注意:Notepad++可直接通过插件→NppExec执行chcp命令检测活动窗口编码
- UTF-8:EF BB BF (BOM头) 或直接以
-
标准化转换流程
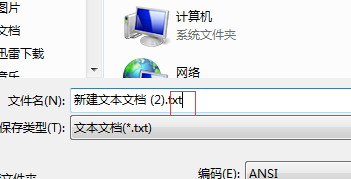
新建文件必须保存为 UTF-8 without BOM(关键!)
禁止混合使用Windows默认的GBK编码
Windows用户需特别关闭记事本的自动检测功能:reg add HKEY_LOCAL_MACHINESOFTWAREMicrosoftNotepad /v NoAutoDetect /t REG_DWORD /d 1 -
批量修正历史文件
使用iconv工具进行无损转换(Linux/macOS):
iconv -f GBK -t UTF-8 old.java > new.java
Windows推荐使用UltraEdit的批量转换功能,勾选”使用UTF-8编码”并取消”写入BOM”
IDE环境配置(以三大主流工具为例)
| 工具 | 关键配置路径 | 推荐设置值 | 注意事项 |
|---|---|---|---|
| IntelliJ IDEA | File → Settings → Editor → File Encodings | Global: UTF-8 Project: UTF-8 |
确保Transparent native-to-ascii conversion禁用 |
| Eclipse | Window → Preferences → General → Workspace | Text file encoding: UTF-8 | 同时修改linked resource的独立编码设置 |
| VS Code | .vscode/settings.json | “files.encoding”: “utf8” | 添加"files.insertFinalNewline": false防尾行干扰 |
编译阶段控制
-
命令行编译强制编码
javac -encoding UTF-8 -sourcepath . -d bin src/com/example/.java
说明:
-encoding同时控制源码读取和字节码写入编码 -
Maven插件配置
在pom.xml中添加:<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin>
运行环境加固
-
JVM启动参数强制编码
java -Dfile.encoding=UTF-8 -jar yourapp.jar
验证生效:在程序首行添加
System.out.println(System.getProperty("file.encoding")); -
跨平台兼容性处理
对于Windows→Linux部署场景,需额外注意:- Linux系统默认使用LF换行符,Windows使用CRLF
- 通过
dos2unix工具统一换行符:dos2unix .java
特殊场景应对
场景1:日志输出乱码
- 根本原因:控制台默认编码与程序输出编码不一致
- 解决方案:
System.setProperty("sun.jnu.encoding", "UTF-8"); // Java7+有效 new java.io.PrintStream(new java.io.OutputStreamWriter(System.out, "UTF-8"), true);
场景2:数据库连接乱码
- JDBC URL追加编码参数:
jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=UTF-8 - MyBatis配置:在
mybatis-config.xml中添加:<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> <setting name="defaultExecutorType" value="REUSE"/> <setting name="defaultStatementTimeout" value="3000"/> <setting name="logImpl" value="SLF4J"/> <setting name="jdbcTypeForNull" value="NULL"/> <setting name="callSettersOnNulls" value="true"/> <setting name="characterEncoding" value="UTF-8"/> </settings>
常见问题FAQs
Q1: 我明明已经将文件保存为UTF-8,为什么IDE里还是显示乱码?
A: 这是典型的”双重编码”问题,请按以下顺序排查:
- 确认文件实际编码是否为UTF-8(用HxD查看文件头)
- 检查IDE的”默认文本编码”设置是否覆盖了项目级设置
- 如果文件包含BOM头(EF BB BF),某些IDE会误判编码,建议删除BOM头:
- Notepad++:菜单栏→编码→以UTF-8无BOM重新编码
- UltraEdit:另存为时取消”包含BOM”选项
Q2: 为什么我的程序在本地运行正常,部署到服务器就出现乱码?
A: 这是典型的运行环境差异问题,重点检查:
- 服务器系统编码:执行
locale命令查看Linux/Unix系统的当前编码,应为en_US.UTF-8或zh_CN.UTF-8 - Tomcat/Jetty配置:在
server.xml中添加URIEncoding过滤器:<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8"/>
- 数据库连接池:确保数据库驱动URL包含
characterEncoding=UTF-8参数,且数据库表字符集为utf8mb4(MySQL)或UTF8(PostgreSQL