上一篇
怎么求数据库文件有多少条记录
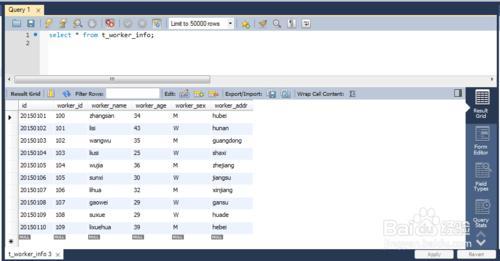
查询数据库文件的记录数,常用方法是执行SQL语句
SELECT COUNT() FROM table_name,适用于大多数关系型数据库,不同数据库系统语法类似,也可通过管理
是几种常见的查看数据库文件中记录条数的方法,适用于不同的场景和数据库类型:
SQL方式(通用)
-
基础COUNT函数
- 语法:
SELECT COUNT() FROM table_name;
该语句会返回指定表中的总行数,包含所有字段均为NULL的记录,这是最直接且跨数据库兼容的方法,几乎支持所有关系型数据库(如MySQL、PostgreSQL、SQL Server等),若需统计用户表的用户总量,可执行:SELECT COUNT() FROM users; - 条件过滤:添加
WHERE子句实现精准计数,比如仅统计活跃用户:SELECT COUNT() FROM users WHERE status = 'active'; - 分组统计:结合
GROUP BY分析不同类别的数据分布,示例:按部门统计员工数量:SELECT department, COUNT() FROM employees GROUP BY department;;进一步用HAVING筛选结果(如仅显示人数超过10的部门):HAVING COUNT() > 10。
- 语法:
-
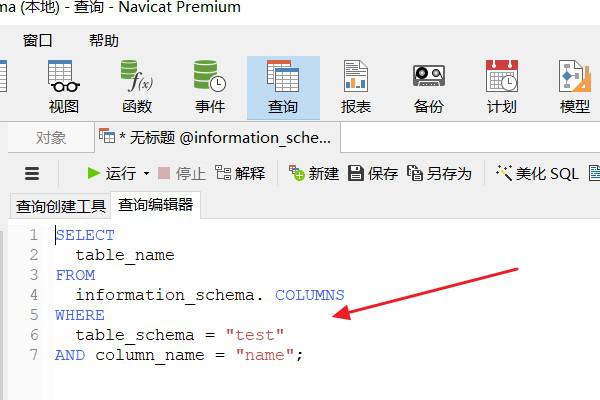
系统元数据视图
- MySQL:查询
information_schema.TABLES系统表,直接获取预存的行数估计值:SELECT TABLE_ROWS FROM information_schema.TABLES WHERE TABLE_SCHEMA = 'your_database' AND TABLE_NAME = 'target_table';
注意此值为近似值,可能因未及时更新而产生偏差。

- SQL Server:通过动态管理视图
sys.dm_db_partition_stats精确求和:SELECT SUM(row_count) FROM sys.dm_db_partition_stats WHERE object_id = OBJECT_ID('table_name') AND index_id IN (0,1);其中
index_id=0表示堆表结构,1为聚集索引,两者相加即总行数。 - PostgreSQL:使用内置监控视图
pg_stat_user_tables快速读取实时统计数据:SELECT relname AS table_name, n_live_tup AS live_rows FROM pg_stat_user_tables;
- MySQL:查询
-
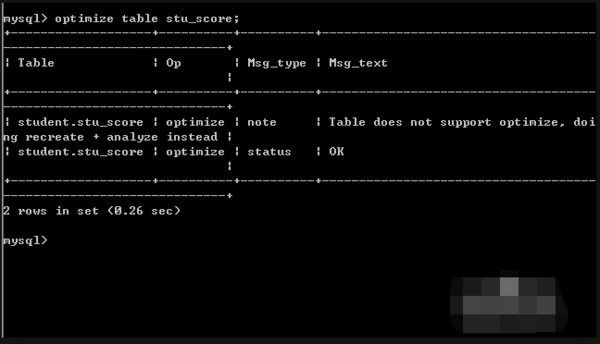
性能优化策略
- 索引利用:对频繁统计的列建立索引,加速
COUNT()执行速度,若常按地区汇总订单量,则应在region字段上建索引。 - 分区表处理:针对海量数据表,采用分区技术分散存储,避免全表扫描导致的性能瓶颈,如按时间范围分区的历史日志表,每次仅需扫描相关分区即可完成计数。
- 缓存机制:对于高频访问的计数需求,可将结果存入Redis等缓存系统,减少数据库负载。
- 索引利用:对频繁统计的列建立索引,加速
-
存储过程封装
以下是一个通用模板示例(以MySQL为例):CREATE PROCEDURE GetRowCount(IN tblName VARCHAR(50)) BEGIN SET @sql := CONCAT('SELECT COUNT() FROM ', tblName); PREPARE stmt FROM @sql; EXECUTE stmt; DEALLOCATE PREPARE stmt; END; -调用方式:CALL GetRowCount('orders');这种方式特别适合复杂业务逻辑中重复调用的场景,同时能有效防止SQL注入攻击。
NoSQL数据库方案
| 类型 | 命令示例 | 说明 |
|---|---|---|
| MongoDB | db.collection.countDocuments() |
支持查询游标批量处理 |
db.collection.estimatedDocumentCount() |
快速估算(不精确但高效) | |
| Cassandra | CQL: SELECT COUNT() FROM keyspace.table; |
注意其底层架构可能导致计数延迟 |
非结构化数据处理
对于CSV/Excel等扁平文件:
- 命令行工具:Unix系统下可用
wc -l filename.csv快速统计行数;Windows则通过findstr /R /C:"^"管道运算实现类似效果。 - 编程语言脚本:Python中逐行读取文件对象并累加计数器是最基础的实现方式,大型数据集推荐使用Pandas库向量化操作提升效率。
辅助工具链集成
现代IDE(如DataGrip、DBeaver)普遍提供可视化界面直接展示表的数据量,而BI工具(Tableau、Power BI)在构建看板时会自动关联元数据中的记录数属性,这些图形化操作本质上仍是执行上述SQL逻辑。
以下是相关问答FAQs:
-
问:为什么有时用系统视图查到的数字和COUNT()结果不一致?
答:因为系统视图保存的是最后一次ANALYZE TABLE时的快照数据,而实际数据可能已发生变化,可通过执行ANALYZE TABLE table_name;强制刷新统计信息同步差异。 -
问:大数据量下如何避免COUNT()导致数据库卡顿?
答:可采用抽样估算策略,例如MySQL的`SELECT ROUND(AVG(blocks),2)(SELECT blocks FROM (SHOW STATUS LIKE ‘Key_blocks_used’) x) AS estimated_rows FROM (SELECT BLOCK_SIZE/1024 AS blocks FROM information_schema.innodb_sys_tablespaces LIMIT 1) y;`,或者业务层维护计数