上一篇
java 随机数怎么写
va生成随机数可用
Math.random()、
Random类、
ThreadLocalRandom或
SecureRandom,依场景选合适方式
Java中生成随机数是一个常见的需求,适用于模拟数据、游戏开发、安全验证等多种场景,以下是详细的实现方法和最佳实践:
基础方法对比与使用技巧
| 类别 | 核心API | 特点 | 适用场景 |
|---|---|---|---|
java.util.Random |
new Random(), nextInt(), nextDouble()等 |
功能全面但非线程安全;支持种子控制 | 单线程环境;测试需要可重复结果 |
Math.random() |
静态方法直接调用,返回[0.0,1.0)之间的double值 | 简单轻量级,无对象创建开销 | 快速生成基础随机小数 |
ThreadLocalRandom |
ThreadLocalRandom.current().nextXxx() |
线程隔离的安全设计;高性能并发支持 | 多线程环境(如Web服务) |
SecureRandom |
new SecureRandom(),基于加密算法实现 |
密码学强度不可预测性;初始化较慢 | 安全敏感场景(密钥/令牌生成) |
Random类的深度应用
通过构造函数传入固定种子可实现可复现的随机序列,这对调试和测试至关重要。
Random seededRandom = new Random(12345L); // 相同种子每次运行结果一致 int predictableValue = seededRandom.nextInt(100); // 始终输出同一个数值用于断言校验
对于范围限定需求,可以利用模运算特性:
// 生成[min, max]闭区间内的整数 int scopedNumber = random.nextInt(max min + 1) + min;
特殊用途方法如nextGaussian()可模拟正态分布数据,适合统计学建模。
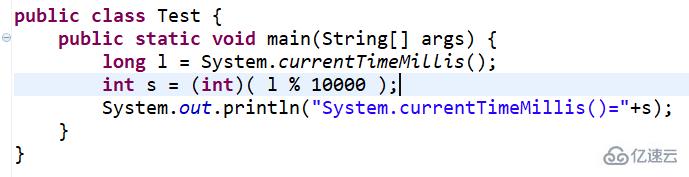
Math.random()转换逻辑
由于该方法仅返回基础分布,需手动进行类型转换和范围扩展,例如要获得1-100的整数:

int scaledValue = (int)(Math.random() 100) + 1; // 先乘后取整再平移
注意浮点精度损失可能导致边界值偏差,建议对关键业务做二次校验。
高级场景解决方案
不重复随机数生成策略
| 方案 | 实现原理 | 时间复杂度 | 内存占用 |
|---|---|---|---|
Collections.shuffle |
预填充全量数据后打乱顺序 | O(n) | O(n) |
HashSet动态去重 |
利用集合特性自动过滤重复值 | O(k)平均 | O(k) |
| Fisher-Yates算法 | 原地置换未被选中的元素 | O(n) | O(1) |
| Java8 Stream API | 借助distinct中间操作符实现惰性求值 | O(k log n)典型情况 | O(1) |
推荐组合使用方式:
// 方案1:洗牌法(适合全集选取)
List<Integer> fullRange = IntStream.rangeClosed(1, 100).boxed().collect(Collectors.toList());
Collections.shuffle(fullRange); // 就地打乱顺序
List<Integer> sampled = fullRange.subList(0, 10); // 取前10个不重复元素
// 方案2:Set去重(适合稀疏采样)
Set<Integer> uniquePool = new HashSet<>();
while(uniquePool.size() < requiredCount){
uniquePool.add(threadLocalRandom.current().nextInt(upperBound));
}
️多线程环境优化
传统Random实例在并发访问时会产生竞争条件,导致性能下降和分布偏移,JDK7引入的ThreadLocalRandom通过为每个线程维护独立实例解决该问题:
// 正确做法:各线程获取自己的随机源 int threadSafeNum = ThreadLocalRandom.current().nextInt(100);
对比测试显示,在高并发场景下其吞吐量比同步块保护的传统方案提升显著,对于需要跨线程共享状态的特殊场景,可以考虑使用SplittableRandom实现并行化生成。
加密级安全需求
当涉及金融交易或认证系统时,必须使用SecureRandom:
SecureRandom secRand = new SecureRandom(); byte[] strongToken = new byte[32]; // 256位安全令牌 secRand.nextBytes(strongToken); // 自动从系统熵池采集随机性
该类底层依赖操作系统提供的密码学安全伪随机数生成器(CSPRNG),相比普通算法具有更强的抗预测能力,但需要注意其初始化耗时较长,不宜频繁创建实例。
常见误区与规避措施
- 错误示范:直接使用
new Random().nextInt()作为常量表达式
→可能导致短时间内大量实例化造成GC压力
→修正方案:静态持有单个Random实例复用 - 陷阱:忽视浮点数的精度边界效应
→例如(int)(Math.random() N)实际最大值为N-1
→建议改用random.nextInt(N)避免闭区间判定失误 - 风险:自定义算法导致分布不均
→如简单的取余操作可能破坏均匀性特征
→优先使用JDK内置方法保证统计质量
扩展应用示例
加权随机选择
实现按比例抽取元素的功能:
Map<String, Double> weights = Map.of("A", 0.7, "B", 0.2, "C", 0.1);
double sum = weights.values().stream().mapToDouble(Double::doubleValue).sum();
Random rnd = new Random();
String selectedItem = weights.entrySet().stream()
.filter(e -> rnd.nextDouble() < e.getValue() / sum)
.findFirst().get().getKey();
特定分布模拟
利用中心极限定理构建近似泊松分布:
// Lambert W函数变换略过,这里展示指数衰减采样替代方案 double lambda = 5.0; // 事件发生率参数 int poissonApprox = (int)Math.floor(-Math.log(1 Math.random()) / lambda);
以下是关于Java随机数生成的相关问答FAQs:
-
问:为什么多线程环境下不能共享同一个Random实例?
答:因为java.util.Random不是线程安全的,多个线程同时修改内部状态会导致竞争条件(Race Condition),可能产生非预期的重复序列或降低随机质量,应使用ThreadLocalRandom替代。 -
问:如何验证生成的随机数是否符合均匀分布?
答:可以通过统计学方法进行卡方检验(Chi-square test),将取值区间划分为若干等宽箱子,统计实际频数与理论期望频数的差异显著性,对于要求不高的场景,简单观察直方图是否