上一篇
反向传播网络错误如何解决
检查数据归一化、调整学习率、验证梯度计算、优化网络结构(如添加批归一化)、确认权重初始化合理,逐步排查代码逻辑
反向传播网络错误解决方案详解
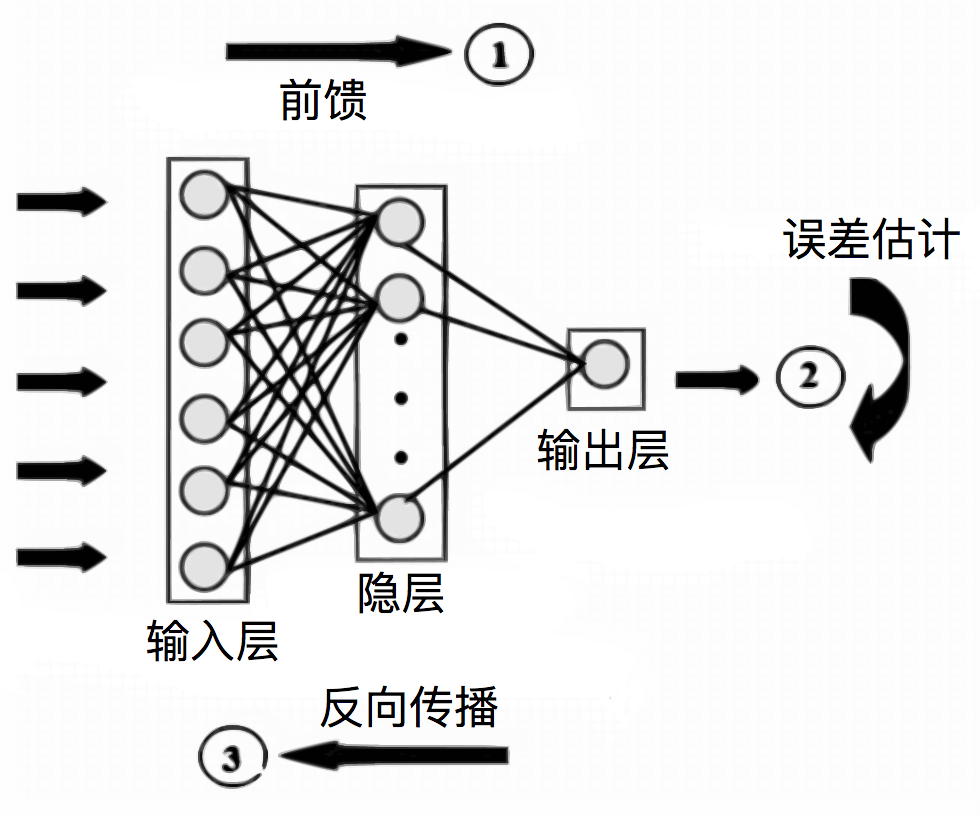
反向传播(Backpropagation)是深度学习的核心算法,但在实际应用中,模型训练常因各种错误导致无法收敛或性能不佳,以下是常见错误的分类、原因分析及解决方案,结合调试技巧与最佳实践,帮助快速定位并修复问题。
常见错误类型与解决方案
| 错误类型 | 典型表现 | 可能原因 | 解决方案 |
|---|---|---|---|
| 梯度消失/爆炸 | 损失值不变、NaN、训练停滞 | 激活函数选择不当(如Sigmoid深层网络)、权重初始化过大/过小 | 改用ReLU/Leaky ReLU激活函数 使用He/Xavier初始化方法 添加Batch Normalization层 |
| 数据问题 | 损失剧烈波动、模型不收敛 | 数据未归一化、标签错误、数据泄漏(训练/验证集混淆) | 标准化输入数据(均值0,方差1) 检查数据标签与任务匹配性 划分独立的训练/验证/测试集 |
| 模型过拟合 | 训练集损失低,验证集损失高 | 网络容量过大、正则化不足 | 添加Dropout层 使用L2正则化 降低网络层数或隐藏单元数量 |
| 超参数配置错误 | 损失不下降、训练速度慢 | 学习率过高/过低、批量大小过大/过小 | 使用学习率调度器(如Cosine Annealing) 尝试Adam/RMSProp优化器 调整批量大小(常见范围16-128) |
| 损失函数不匹配 | 损失值异常或模型输出偏离目标 | 分类任务使用MSE、回归任务使用交叉熵 | 根据任务选择损失函数: 分类:CrossEntropyLoss 回归:MSELoss 二分类:BCEWithLogitsLoss |
分步调试与优化流程
验证基础功能
- 简化模型:从单层感知机或浅层网络开始,确保反向传播基础功能正常。
- 线性模型测试:用线性回归模型验证数据输入与损失计算是否正确。
- 示例代码:
# 测试线性模型是否能拟合简单数据 model = nn.Linear(1, 1) data = torch.tensor([[1.0], [2.0], [3.0]]) target = torch.tensor([[2.0], [4.0], [6.0]]) # 若损失无法下降,检查数据预处理与标签
检查梯度流

- 梯度打印:在反向传播后打印梯度,确认是否出现NaN或全零。
- 梯度截断:对梯度进行阈值限制(如
torch.nn.utils.clip_grad_value_)。 - 示例:
for name, param in model.named_parameters(): if param.grad is not None: print(f"{name} grad: {param.grad.abs().mean()}")
可视化诊断
- 损失曲线:绘制训练与验证损失,判断过拟合或欠拟合。
- 激活值分布:检查每层输出是否满足激活函数特性(如ReLU需保证部分输出>0)。
- 工具推荐:TensorBoard、Matplotlib绘制权重直方图与激活值热图。
超参数敏感性分析
- 学习率扫描:从
1e-5到1e-1尝试不同学习率,观察损失变化。 - 批量大小实验:对比不同批量大小(如32 vs 128)对收敛速度的影响。
- 优化器对比:测试SGD+动量、AdamW等优化器的效果差异。
- 学习率扫描:从
常见问题FAQs
Q1:为什么模型训练时出现NaN损失?
- 原因:
- 梯度爆炸导致数值溢出(如未初始化权重过大)。
- 学习率过高,参数更新步长过大。
- 解决方法:
- 降低学习率(如从
1e-2调整为1e-3)。 - 启用梯度裁剪(Gradient Clipping)。
- 检查权重初始化方法(如He初始化)。
- 降低学习率(如从
Q2:验证集损失始终高于训练集怎么办?
- 原因:
- 模型过拟合(如网络容量过大、正则化不足)。
- 数据泄漏(验证集与训练集分布不一致)。
- 解决方法:
- 添加Dropout层或L2正则化。
- 严格划分训练/验证集,避免数据重复。
- 使用数据增强(如随机裁剪、翻转)增加训练集多样性。
最佳实践归纳
- 模块化调试:从简单模型开始,逐步增加复杂度。
- 日志记录:保存损失、准确率、梯度等关键指标,便于回溯分析。
- 版本控制:使用Git管理代码,避免参数混乱。
- 复现经典模型:参考ResNet、VGG等开源代码,验证框架正确性。
通过系统化的错误排查与优化,可有效解决反向传播中的常见问题,提升模型