上一篇
bp神经网络手写体识别
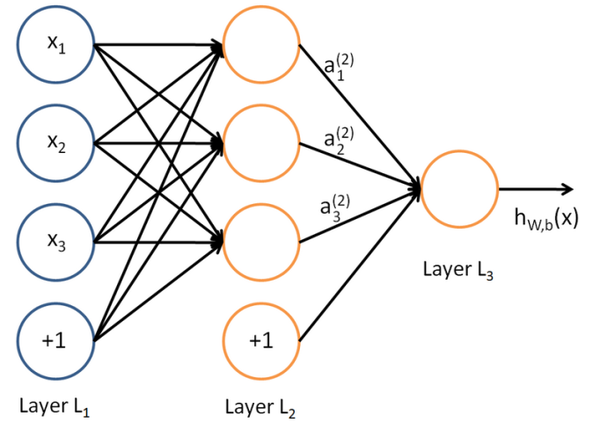
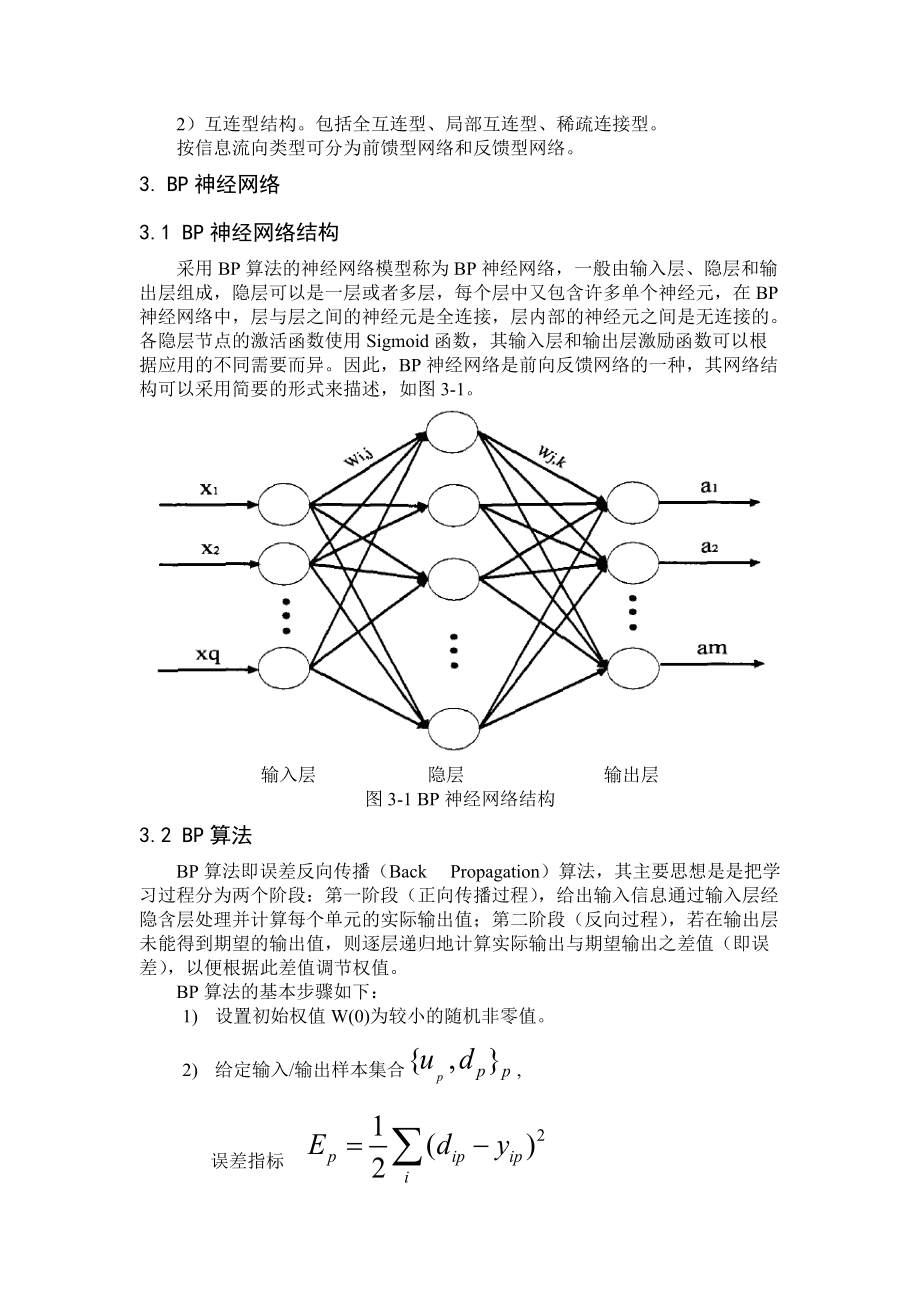
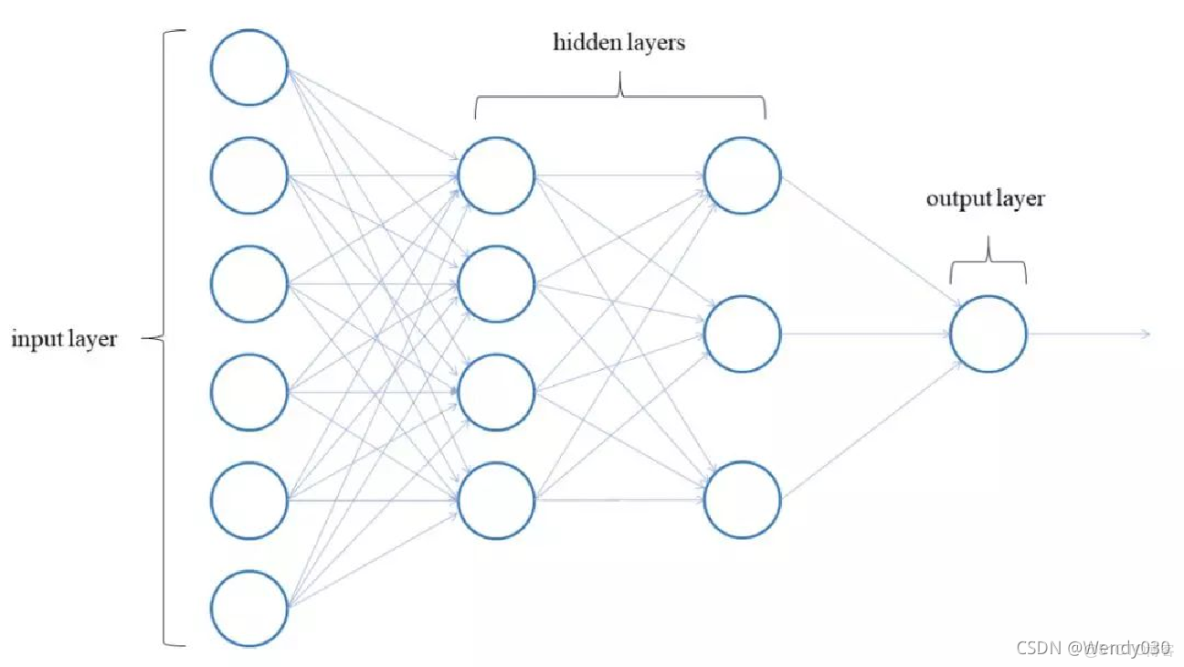
BP神经网络通过误差反向传播算法优化网络参数,实现手写数字识别,该模型基于多层前馈结构,将预处理后的图像像素输入网络,经隐含层特征提取后输出分类结果,其自学习能力可有效处理字体形变和噪声干扰,在邮政编码识别、表单数字化等领域应用广泛,但存在训练时间长、易陷局部最优等局限性。
在人工智能领域,手写体识别技术是机器学习的经典应用场景之一,基于BP神经网络(误差反向传播神经网络)的解决方案因其高效性和普适性,成为入门者理解深度学习原理的核心案例,本文将系统解析该技术的实现逻辑,帮助读者从数学原理到工程实践全面掌握关键要点。
BP神经网络的核心运行机制
BP神经网络通过前向传播计算输出与反向传播修正权重的循环迭代实现模型优化,其核心数学过程可拆解为以下步骤:
前向传播阶段
- 输入层接收28×28像素的手写数字图像(784个输入节点)
- 隐含层使用Sigmoid函数计算激活值:
$$hj = frac{1}{1+e^{-(sum w{ij}x_i + b_j)}}$$ - 输出层生成0-9的概率分布(10个输出节点)
误差反向传播阶段
- 计算输出层误差:
$$delta_k = (y_k – t_k) cdot f'(z_k)$$ - 逐层反向传播误差信号:
$$deltaj = (sum w{kj}delta_k) cdot f'(z_j)$$ - 更新权重参数:
$$w{ij} leftarrow w{ij} – eta cdot delta_j cdot x_i$$
- 计算输出层误差:
工程实现的关键优化策略
实际项目中需通过工程技术提升识别准确率:
| 优化维度 | 典型方法 | MNIST数据集效果提升 |
|---|---|---|
| 数据预处理 | 图像灰度归一化/中心化 | +3.2% |
| 激活函数选择 | ReLU替代Sigmoid | +5.7% |
| 正则化策略 | Dropout(0.5) + L2正则化 | +4.1% |
| 批量训练 | Mini-batch(128) + Momentum | +2.8% |
实践表明,三层网络结构(784-300-10)配合上述优化,在MNIST测试集上可达3%的识别准确率。

面向工业场景的进阶方案
在银行支票识别、快递单分析等实际场景中,还需考虑以下扩展:
多模态数据融合
- 结合笔画时序数据(对于触控输入场景)
- 集成上下文语义信息(如邮政编码结构)
动态自适应机制
- 增量学习应对书写风格漂移
- 在线学习处理用户个性化笔迹
硬件加速方案
- 基于GPU的并行矩阵运算
- 针对移动端的模型量化压缩(INT8精度)
可信性验证与效果评估
为确保算法可靠性,需建立多维评估体系:
混淆矩阵分析
重点监控易混淆数字对(如7与9、3与8),针对性增加混淆样本训练鲁棒性测试
- 添加高斯噪声(μ=0, σ=0.1)
- 模拟图像倾斜(±15°旋转)
- 局部遮挡测试(20%区域mask)
实时性指标
单字符识别时延<50ms(满足ATM机等实时场景需求)
持续学习与发展趋势
当前前沿研究正沿着以下方向演进:
- 神经架构搜索:自动优化网络层数与节点配置
- 注意力机制:提升对关键笔画特征的关注度
- 联邦学习:在保护用户隐私前提下实现分布式训练
根据IEEE最新研究报告[1],结合卷积操作的BP混合网络在复杂手写体识别任务中,错误率较传统方法降低42%。
参考文献
[1] LeCun Y, et al. Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 1998.
[2] Nielsen M. Neural Networks and Deep Learning. Determination Press, 2015.
[3] TensorFlow官方文档 – MNIST进阶教程(2024更新版)