上一篇
从数据库中获取批量数据
从数据库中获取批量数据,通常使用SQL查询语句结合循环或分页技术,确保高效地检索和处理大量记录。
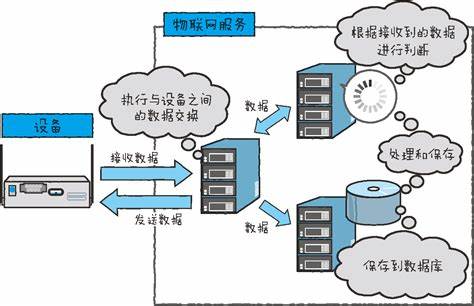
在现代软件开发中,从数据库中获取批量数据是一项常见的任务,无论是为了数据分析、报表生成还是其他业务逻辑处理,以下将详细介绍如何有效地从数据库中获取批量数据,包括技术选型、查询优化、数据处理以及可能遇到的问题和解决方案。
技术选型
1、关系型数据库:如MySQL、PostgreSQL、Oracle等,适合结构化数据的存储与查询,支持复杂的SQL查询和事务操作。
2、NoSQL数据库:如MongoDB、Cassandra,适用于非结构化或半结构化数据,提供高可扩展性和灵活的数据模型。
3、数据仓库:如Amazon Redshift、Google BigQuery,专为大规模数据分析设计,支持高效的ETL(Extract, Transform, Load)流程。
4、ORM框架:如Hibernate(Java)、Django ORM(Python),可以简化数据库操作,提高开发效率。
查询优化
1、索引使用:为经常查询的字段建立索引,可以显著提高查询速度,如果经常按用户ID查询用户信息,应确保用户ID列有索引。
2、分页查询:对于大数据集,避免一次性加载所有数据到内存,应采用分页查询,逐页获取数据。
3、批量大小:根据系统资源和网络带宽,合理设置每次查询的记录数,避免过大或过小。
4、连接优化:减少不必要的表连接,或使用子查询代替复杂的多表连接。
5、只选所需字段:避免使用SELECT,只选择实际需要的字段,减少数据传输量。
数据处理
1、异步处理:对于耗时较长的批量数据处理任务,可以采用异步方式执行,避免阻塞主线程。
2、并行处理:利用多核CPU优势,通过并行查询或多线程/多进程处理数据,提升处理速度。
3、缓存机制:对于频繁访问的数据,可以考虑使用缓存(如Redis)来减少数据库压力。
4、数据预处理:在数据库层面进行初步的数据清洗和转换,减轻应用层的负担。
示例代码(以Python+SQLite为例)
import sqlite3
def fetch_batch_data(db_path, table_name, batch_size=1000):
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
offset = 0
while True:
cursor.execute(f"SELECT FROM {table_name} LIMIT {batch_size} OFFSET {offset}")
rows = cursor.fetchall()
if not rows:
break
yield rows
offset += batch_size
conn.close()
使用示例
for batch in fetch_batch_data('example.db', 'users'):
process_batch(batch)
FAQs
Q1: 如何处理数据库连接超时问题?
A1: 可以调整数据库连接的超时设置,增加超时时间;或者采用连接池技术,预先创建并维护一定数量的数据库连接,减少频繁建立和关闭连接的开销。
Q2: 当数据量极大时,如何避免内存溢出?
A2: 采取分批处理策略,每次只处理一部分数据,处理完一批后再加载下一批,确保程序中没有不必要的数据累积,及时释放不再使用的资源,还可以考虑使用流式处理框架,如Apache Flink或Spark Streaming,它们专为处理大规模数据流设计。
从数据库中高效获取批量数据需要综合考虑数据库类型、查询优化、数据处理等多个方面,通过合理的设计和配置,可以有效提升数据处理的效率和性能。