上一篇
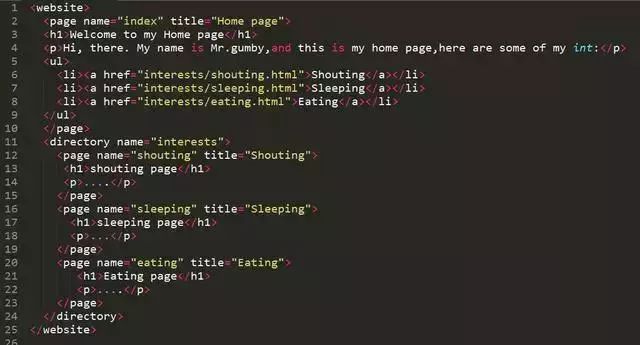
如何读取html文件内容
文本编辑器(如VS Code)、浏览器查看源码功能或编程语言(Python的BeautifulSoup库)读取HTML文件
是关于如何读取HTML文件内容的详细说明,涵盖不同场景下的解决方案及具体实现步骤:
基础概念与原理
HTML(HyperText Markup Language)本质是文本格式的数据载体,其内容由标签结构组成,无论是手动查看还是程序化解析,核心目标都是获取其中的文本、标签层级关系或特定元素属性,根据需求复杂度不同,可选择从简单到高级的技术方案。
常见方法分类对比
| 工具类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 文本编辑器直接打开 | 快速预览小规模静态页面 | 无需编码,直观可见 | 无法自动化处理大量文件 |
| Python标准库 | 基础的文件读写操作 | 原生支持,零依赖 | 需自行处理解析逻辑 |
| BeautifulSoup | 复杂网页结构提取与清洗 | 语法友好,容错性强 | 依赖第三方库安装 |
| lxml/html.parser | 高性能精准定位元素 | 执行速度快,支持XPath表达式 | 学习曲线较陡 |
分步实操指南(以Python为例)
环境准备阶段
建议通过pip install beautifulsoup4 lxml命令安装必要的依赖库,这两个库组合使用时既能保证解析效率又能兼顾代码可读性,特别注意要确保本地Python版本与库版本的兼容性。
基础读取流程
# 方式一:使用open()配合BeautifulSoup
with open('./example.html', 'r', encoding='utf-8') as f:
content = f.read() # 获取原始字节流
soup = BeautifulSoup(content, 'lxml') # 指定解析器提升性能
# 方式二:链式调用简化写法(推荐)
soup = BeautifulSoup(open('./example.html', encoding='utf-8'), features='html.parser')
上述代码中,encoding='utf-8'参数至关重要,它能避免中文乱码问题;features='html.parser'则允许切换不同的底层解析引擎。
深度解析技巧
- 节点遍历:通过
find_all()方法按标签名批量定位元素,例如soup.find_all('p')可提取所有段落文本,结合get_text()方法能去除嵌套标签只保留纯文字内容。 - 属性过滤:当需要精准匹配特定class或id时,可以使用字典语法:
soup.find(attrs={"class": "header"}),这种方式特别适合从动态生成的网页中抓取关键数据块。 - CSS选择器应用:现代开发更倾向使用类似jQuery的选择器语法,如
soup.select('div > a[href="https"]'),能够跨层级穿透复杂的DOM结构。
异常处理机制
实际项目中常遇到以下问题及应对策略:
- 编码识别错误:尝试添加
errors='ignore'参数跳过非规字符,或者用chardet库自动检测编码格式。 - 断链修复:对于不完整的HTML片段,设置
formatter="html"参数可使解析器自动补全缺失的闭合标签。 - 内存优化:处理超大文件时采用逐行读取模式(
for line in f:),避免一次性加载导致内存溢出。
扩展应用场景示例
| 需求类型 | 典型实现方案 |
|---|---|
| 数据采集系统 | 结合requests库实现网页爬虫,定时抓取目标站点更新内容 |
| 模板引擎开发 | 将HTML作为视图模板,动态插入变量生成个性化页面 |
| 文档转换工具 | 提取章节标题构建目录树,转换为Markdown或其他格式输出 |
| SEO分析平台 | 统计meta标签中的关键词密度,评估页面优化程度 |
注意事项与最佳实践
- 性能权衡:在速度敏感的场景下优先选用
lxml解析器,若侧重兼容性则选择默认的html.parser,两者在大多数情况下表现相近,但在处理非常规写法的HTML时会有差异。 - 安全边界:永远不要信任外部输入的HTML内容,使用
sanitize()方法过滤潜在反面脚本后再渲染显示,特别是用户上传的文件必须经过严格校验。 - 编码统一性:始终显式指定文件编码格式,尤其在跨国团队协作项目中,建议统一采用UTF-8编码存储所有资源文件。
以下是两个常见问题及其解答:
FAQs
Q1: 如果遇到文件打开失败提示权限拒绝怎么办?
A: 检查当前用户的读权限设置,可通过chmod +r filename.html命令修改Linux系统的访问权限;Windows用户则需要右键属性面板确认取消只读属性,同时确保程序运行账户具有相应目录的访问权限。
Q2: 如何处理带有框架(iframe)的嵌套页面?
A: 先解析主页面获取所有iframe源链接,然后递归请求并解析每个子页面的内容,可以使用队列数据结构管理待抓取的URL列表,配合深度优先或广度优先算法实现完整爬取,注意设置最大递归层数防止