上一篇
数据库中的数据是乱码怎么解决
字符集编码,统一设置为UTF-8或兼容格式即可修复
核心原因分析
乱码的本质是数据在不同环节使用了不一致的字符集解析方式,客户端与数据库服务器默认编码不同、表/字段层级未显式指定字符集、传输过程中二进制数据被误读为文本等,典型场景包括中文显示为“???”、特殊符号变形或内容完全不可读。
分步解决方案
1. 检查并统一数据库字符集设置
- 操作路径:登录MySQL执行
SHOW VARIABLES LIKE 'character_set%';(其他数据库如PostgreSQL使用类似命令),重点关注character_set_server(服务器端)、collation_server(排序规则)是否为UTF-8系列(推荐utf8mb4),若非UTF-8,可通过修改配置文件(my.cnf)重启实例调整。 - 作用域扩展:不仅修改全局设置,还需逐级向下验证库(DATABASE)、表(TABLE)、列(COLUMN)的字符集定义,使用
SHOW CREATE TABLE tablename;查看建表语句中的DEFAULT CHARSET和COLLATE参数是否符合预期,对于已存在的非UTF-8表,可执行ALTER TABLE ... CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;进行无损转换。 - ️注意:此操作可能影响历史备份兼容性,建议先在测试环境验证。
2. 规范应用程序连接参数
- JDBC示例:在URL中明确添加编码声明:
jdbc:mysql://host:port/dbname?useUnicode=true&characterEncoding=UTF-8,遗漏该参数会导致驱动默认采用ISO-8859-1等拉丁字符集解析结果集。 - ORM框架适配:Hibernate需在
hibernate.cfg.xml中配置<property name="hibernate.connection.CharSet">UTF-8</property>;MyBatis则通过settings的jdbcTypeForNull策略补充编码元数据。 - 终端工具同步性:Navicat、DBeaver等客户端必须在“新建连接”对话框手动选择与数据库一致的字符集,避免依赖操作系统区域设置自动推断失败的情况。
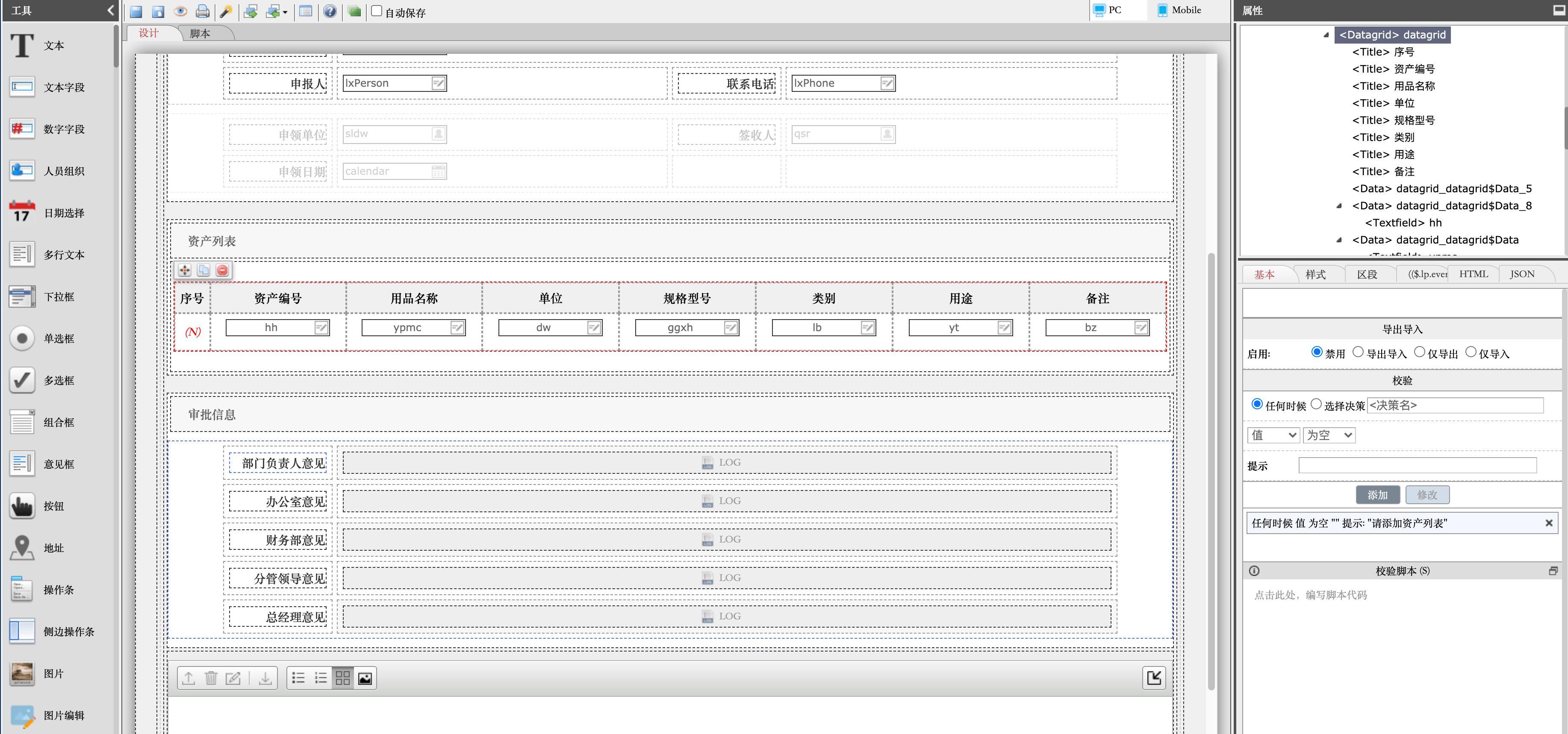
3. 数据导入导出全链路控制
| 场景 | 关键指令/配置 | 常见错误规避 |
|---|---|---|
| CSV文件导入 | LOAD DATA INFILE 'file.csv' INTO TABLE tb CHARACTER SET utf8mb4; |
忽略文件自身的BOM头导致首列缺失 |
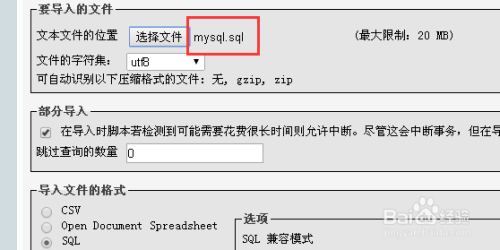
| SQL转储恢复 | mysqldump --default-character-set=utf8mb4 --skip-opt ... |
未加--result-file=NULL引发二次编码被墙 |
| ETL工具传输 | Spark作业设置option("charset", "UTF-8") |
Hadoop集群HDFS默认块存储破坏多字节字符 |
特别提示:处理二进制字段(BLOB/TEXT类型)时,禁用所有自动类型转换功能,直接以十六进制模式读写原始字节流。
4. 历史遗留数据处理方案
当无法重构上游系统时,可采用以下应急措施:
- 批量转码脚本:编写存储过程逐行调用
CONVERT(column USING utf8mb4)函数更新脏数据,例如针对GBK编码残留的数据:UPDATE old_table SET content = CONVERT(content USING utf8mb4) WHERE CharLength(content)<>Length(content);
- 中间代理层设计:在应用层增加编码嗅探模块,动态检测入站请求的实际编码(基于统计模型判断GBK/Big5/Shift_JIS),再转换为目标字符集存储,Python的
chardet库可实现此功能。
5. 监控与预防机制建设
部署审计规则拦截高风险写入操作:
- 触发器实现入库前校验:
BEFORE INSERT ON your_table FOR EACH ROW BEGIN IF NOT REGEXP_LIKE(NEW.text_col, '^[\x00-\xFF]+$') THEN ... END IF; END; - Prometheus指标暴露非UTF-8写入次数:通过解析Binlog事件统计
CharacterSet mismatch errors异常计数。
典型案例对比表
| 故障现象 | 根本原因 | 解决耗时 | 修复成本 |
|---|---|---|---|
| Web表单提交后姓名变问号 | HTTP头未声明Accept-Charset | 2小时 | Nginx配置修正 |
| Excel导出数字格式错乱 | OpenOffice默认使用CP1252 | 4小时 | VBA宏强制指定编码 |
| 日文片假名显示方块 | TrueType字体缺失Glyph页面 | 6小时 | 系统级安装CJK补全包 |
| JSON API返回Base64串 | FastAPI框架未启用response_model定制 | 8小时 | Pydantic模型重构 |
相关问答FAQs
Q1: 如果已经按照上述步骤操作但仍存在部分乱码怎么办?
A: 可能存在两种特殊情况:①存储引擎差异——InnoDB与MyISAM对索引键的前缀长度限制不同,超过767字节会导致截断;②并发写入冲突——多线程同时修改同一记录时产生脏读,建议启用事务隔离级别READ COMMITTED并缩小锁粒度,此时可通过SHOW FULL PROCESSLIST;定位阻塞会话。
Q2: 如何快速定位是哪个环节导致的乱码?
A: 采用分段排查法:①用HEX函数查看原始二进制值是否完整;②在中间件出入口打印Charset标识;③抓包分析TCP层是否有分片重组错误,推荐工具组合:Wireshark+tcpdump+iconv命令行测试,形成