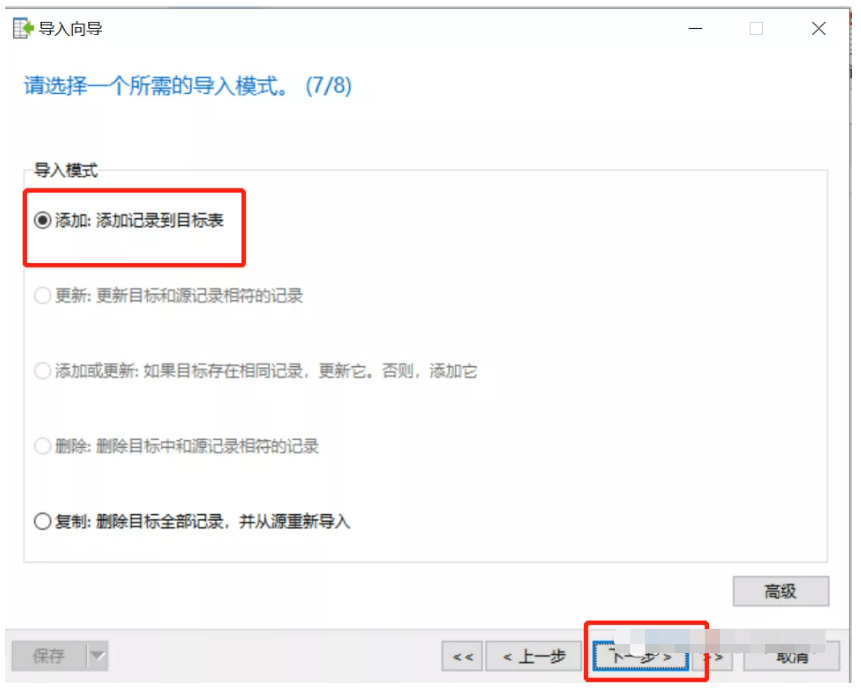
上一篇
plsql怎么导入表数据库表
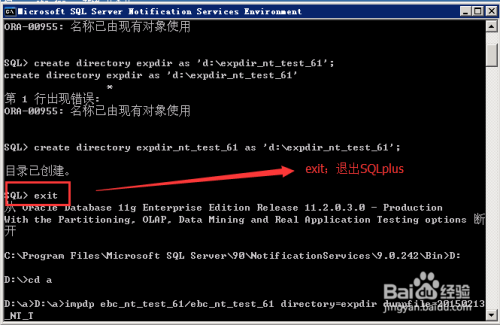
PLSQL中,可通过工具菜单选择“导入表”来
导入数据库
表结构及序列;数据则按需单独导入,需确保目标库存在对应用户和表
是使用PL/SQL导入数据库表的详细操作指南,涵盖多种场景和注意事项:
准备工作
-
确认权限与环境
- 确保当前用户具备目标模式(Schema)下的
CREATE TABLE、INSERT等必要权限,若涉及跨模式操作,需由DBA授予相应角色。 - 安装并配置好PL/SQL开发工具(如PL/SQL Developer或Oracle SQL Developer),成功建立与数据库的连接。
- 确保当前用户具备目标模式(Schema)下的
-
数据源准备
- 常见导入格式包括:CSV/Excel电子表格、其他数据库导出的DMP文件、SQL脚本文件(含
CREATE TABLE + INSERT语句),根据实际需求选择合适的方式。
- 常见导入格式包括:CSV/Excel电子表格、其他数据库导出的DMP文件、SQL脚本文件(含
通过PL/SQL Developer图形化界面导入
方法1:执行SQL脚本批量建表+插数据
-
打开已连接的数据库会话,点击顶部工具栏的“文件”→“打开”,选择本地保存的
.sql脚本文件,典型结构如下:-示例:创建员工信息表并插入测试数据 CREATE TABLE employees ( id NUMBER PRIMARY KEY, name VARCHAR2(50), join_date DATE, salary NUMBER(10,2) ); INSERT INTO employees VALUES (1, '张三', TO_DATE('2023-01-15', 'YYYY-MM-DD'), 8500.00); INSERT INTO employees VALUES (2, '李四', TO_DATE('2024-03-20', 'YYYY-MM-DD'), 9200.50); COMMIT; -确保事务提交以生效更改 -
高亮选中全部代码后按F5执行,或右键选择“运行”,若报错需检查语法错误(如类型不匹配)、约束冲突等问题。

方法2:使用工具菜单导出功能反向生成结构
如果已有现成数据库中的某张表需要复制到当前库:右击目标表名→“导出”→生成包含完整DDL的脚本,修改存储路径后加载到新环境中执行,此方法适用于同构迁移场景。
命令行方式实现动态导入
对于复杂逻辑或大数据量的情况,推荐编写存储过程配合外部程序调用:
-示例:通过UTL_FILE包读取文本文件中的数据逐行加载
CREATE OR REPLACE PROCEDURE load_from_txt IS
v_line VARCHAR2(4000);
v_col1 employees.id%TYPE;
v_col2 employees.name%TYPE;
... -根据实际字段定义变量
BEGIN
FOR rec IN (SELECT FROM employees WHERE rownum=0) LOOP -伪循环占位符
BEGIN
-解析每行内容并赋值给变量(此处简化处理)
DBMS_OUTPUT.PUT_LINE('Processing line: ' || v_line);
-执行插入操作
INSERT INTO employees(id, name, join_date, salary) VALUES (v_col1, v_col2, ...);
EXCEPTION WHEN OTHERS THEN
ROLLBACK;
DBMS_OUTPUT.PUT_LINE('Error occurred: ' || SQLERRM);
END;
END LOOP;
COMMIT;
END;
/
️ 注意:直接操作文件系统存在安全风险,生产环境建议改用DIRECT_PATH API或外部表空间方案提升性能。
不同格式数据处理对比表
| 数据类型 | 适用场景 | 优点 | 缺点 | 推荐工具 |
|---|---|---|---|---|
| SQL脚本 | 小规模结构化数据 | 可控性强,支持事务回滚 | 手工编写耗时 | 记事本/Notepad++ |
| CSV/TXT文本 | 中等体量扁平化记录 | 易生成,通用性强 | 需处理特殊字符转义 | Excel另存为CSV格式 |
| DMP备份文件 | 全库级灾难恢复 | 包含索引/权限元信息 | 依赖Oracle客户端工具 | RMAN命令行工具 |
| Excel电子表格 | 交互式编辑复杂关系网 | 可视化友好,公式辅助清洗 | 大数据时响应缓慢 | SQL Developer Data Modeler |
高级技巧与优化建议
- 禁用索引加速批量插入
大批量导入前执行ALTER INDEX idx_name UNUSABLE;暂时失效索引,完成后重建可减少I/O消耗。ALTER INDEX emp_pk UNUSABLE; -执行大量INSERT后... ALTER INDEX emp_pk REBUILD ONLINE;
- 绑定变量替代字面量
使用占位符参数化SQL语句能显著降低解析开销:DECLARE TYPE t_arr IS VARRAY(100) OF employees%ROWTYPE; l_data t_arr := t_arr(); BEGIN FOR i IN 1..l_data.COUNT LOOP EXECUTE IMMEDIATE 'INSERT INTO employees VALUES (:1, :2, :3, :4)' USING l_data(i); END LOOP; END; - 并行加载机制
启用多线程处理可通过以下设置实现:ALTER SESSION ENABLE PARALLEL DML; INSERT /+ PARALLEL(employees, 4) / INTO employees ...;
需注意锁竞争问题,适合读多写少的业务场景。
FAQs
Q1: 执行导入时遇到ORA-00984错误怎么办?
A: 这是典型的列数不匹配错误,请逐一核对INSERT语句中的值数量是否与表定义一致,特别注意DEFAULT值未显式声明的情况,例如当表有NOT NULL约束但插入语句遗漏对应列时就会触发该错误。
Q2: 如何快速清空旧数据重新导入?
A: 根据业务需求选择合适策略:①TRUNCATE TABLE(速度快但不可回滚);②带条件的DELETE(事务安全);③交换分区法(适用于超大型表),推荐组合使用闪回查询验证删除