上一篇
如何下载HTML文件?
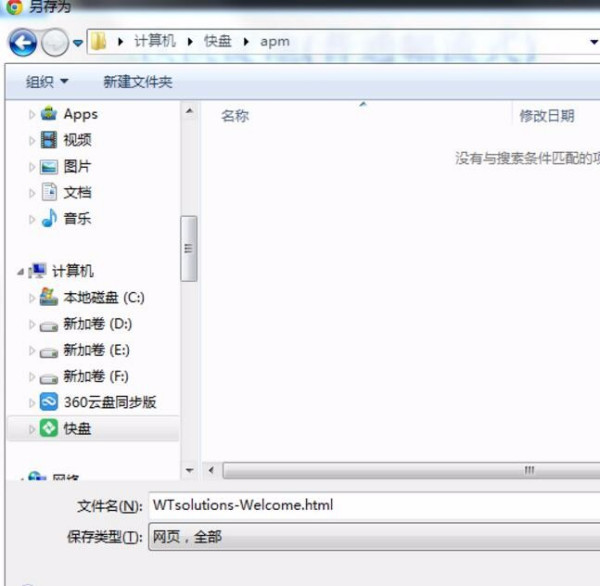
右键点击网页选“另存为”,或按Ctrl+S保存文件;保存时类型选“HTML”可保留基础结构,选“完整网页”将附带图片等资源;也可用开发者工具复制源代码粘贴至文本文件,扩展名改为.html。
如何下载HTML文件?专业指南助你轻松保存网页源码
在浏览网页时,你可能需要保存网页的HTML文件用于离线阅读、学习网页结构或备份重要内容,以下是经过验证的专业方法:
浏览器原生保存方法(推荐初学者)
操作步骤:
- 打开目标网页(如
https://example.com) - 右键页面空白处 → 选择 “另存为…”(Windows/Linux)或 “将页面另存为…”(Mac)
- 选择保存位置:
- 保存类型:“网页,仅HTML”
- 编码建议:UTF-8(兼容特殊字符)
- 点击保存后获得
.html文件
专业提示:
此方法会保留基本结构,但可能丢失动态加载的内容,若需完整资源(图片/CSS/JS),请选择 “网页,全部” 选项
开发者工具导出(适合网页开发者)
进阶操作流程:

- 按
F12或Ctrl+Shift+I打开开发者工具 - 切换到 “Elements” 标签页
- 右键
<html>顶级元素 → 选择 “Copy” → “Copy outerHTML” - 新建文本文件 → 粘贴代码 → 保存为
filename.html
技术优势:
精确获取当前DOM状态
包含动态修改后的代码
避免无关资源干扰分析
命令行高效下载(技术用户首选)
通过终端实现批量下载:
# 使用curl(跨平台) curl -o webpage.html https://example.com # 使用wget(完整资源下载) wget --page-requisites --convert-links https://example.com
参数解析:
--page-requisites:下载图片/CSS等依赖资源--convert-links:自动转换本地链接-o:指定输出文件名
专业工具推荐
| 工具名称 | 适用平台 | 核心功能 |
|---|---|---|
| HTTrack | Win/Mac/Linux | 整站离线镜像 |
| SingleFile | 浏览器扩展 | 单文件保存完整页面 |
| Scrapy | Python环境 | 定制化爬虫框架 |
| SiteSucker | macOS | 可视化站点下载工具 |
重要法律与道德规范
- 版权合规
仅下载授权内容(查看robots.txt文件),如:User-agent: * Allow: /public/ Disallow: /private/ - 隐私保护
禁止下载含个人数据的网页(GDPR/CCPA适用) - 服务器负载
添加下载延迟(如wget的--wait=5),避免高频请求
权威建议:根据W3C规范,商业用途应始终获取内容所有者书面许可
常见问题解决方案
▸ 中文乱码问题
用记事本打开HTML → 点击”文件”→”另存为”→编码选 UTF-8
▸ 缺失
使用Puppeteer等无头浏览器:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com', {waitUntil: 'networkidle2'});
const html = await page.content();
// 将html写入文件
await browser.close();
})();
掌握这些方法后,您将能安全合规地获取所需HTML文件,请始终遵循:
“技术服务于人,尊重是创新基石” 的行业准则
参考来源:
- MDN Web Docs:网页保存规范
- W3C:网页内容可访问性指南
- 互联网工程任务组(IETF)HTTP协议标准