上一篇
分布式服务器开发经验
具备分布式服务器开发经验,熟悉架构设计、高并发处理及容错机制,掌握负载均衡与微服务拆分,熟练使用Dubbo、Spring
分布式服务器开发经验深度解析
在互联网高速发展的背景下,分布式服务器架构已成为支撑高并发、高可用系统的核心技术,作为一名拥有多年实战经验的开发者,我将从架构设计、技术选型、容错机制、性能优化及监控运维等维度,系统分享分布式服务器开发的关键要点与实践经验。
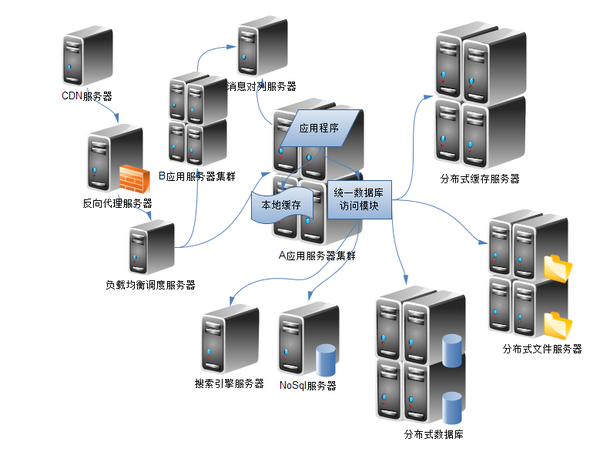
分布式架构设计核心原则
分布式系统的核心目标是解决单机性能瓶颈、提升系统可用性,以下是架构设计的核心原则:
| 原则 | 说明 |
|---|---|
| 无状态设计 | 服务节点应尽量保持无状态,状态数据外部化(如Redis/数据库),便于水平扩展。 |
| 分区容忍性 | 通过数据分片(Sharding)和副本机制,确保部分节点故障时系统仍能正常运行。 |
| 一致性与可用性平衡 | 根据业务场景选择CAP定理中的强一致性(如金融系统)或高可用性(如社交平台)。 |
| 幂等性设计 | 接口需支持重复调用不产生副作用(如支付回调需唯一ID校验)。 |
案例:某电商平台订单系统采用“分库分表+异步最终一致性”方案,将订单数据按用户ID分片存储,通过MQ异步同步库存,既保证写入性能又避免数据冲突。
技术选型与组件整合
分布式系统的实现依赖多种中间件,技术选型需综合考虑性能、生态和团队熟悉度:
| 领域 | 主流技术 | 适用场景 |
|---|---|---|
| RPC框架 | Dubbo、gRPC、Thrift | 微服务间高性能通信 |
| 消息队列 | Kafka、RabbitMQ、RocketMQ | 异步解耦、削峰填谷 |
| 注册中心 | Eureka、Consul、Nacos | 服务发现与健康检查 |
| 配置中心 | Spring Cloud Config、Apollo | 动态配置管理与灰度发布 |
| 数据库 | MySQL(分库分表)、MongoDB(文档存储) | 结构化与非结构化数据混合存储 |
实践技巧:
- RPC框架对比:
- gRPC:基于HTTP/2,支持多语言,适合轻量级服务;
- Dubbo:阿里巴巴开源,生态完善,支持自动负载均衡;
- Thrift:Facebook开源,跨语言能力强,但配置较复杂。
- 消息队列选型:
Kafka适合高吞吐量日志采集,RabbitMQ适合复杂路由场景,RocketMQ兼顾两者优势。

容错与高可用机制
分布式系统需应对网络分区、节点宕机等异常场景,以下机制至关重要:
服务降级与熔断
- 使用Hystrix/Sentinel实现熔断,防止故障扩散,当下游服务响应超时时,直接返回预设的降级数据(如默认商品信息)。
- 示例代码(Sentinel):
// 定义熔断规则 SentinelResourceAspect aspect = new SentinelResourceAspect(); aspect.setBlockHandler((ex, invocation) -> { return "服务临时不可用,请稍后重试"; });
数据副本与一致性
- 通过Raft/Paxos协议实现主从复制(如MySQL主从架构),结合读写分离提升性能。
- 使用ZooKeeper/Etcd管理分布式锁,避免脑裂问题。
自动故障转移
- 注册中心(如Nacos)定期检测服务健康状态,自动剔除故障节点。
- 数据库采用MHA(Master High Availability)实现主库故障自动切换。
性能优化策略
分布式系统的性能瓶颈通常出现在网络IO、数据库读写和线程阻塞环节,优化策略如下:
| 优化方向 | 具体手段 |
|---|---|
| 减少网络调用 | 合并多个RPC请求为批量接口,使用长连接(如Netty)。 |
| 缓存加速 | 热点数据存入Redis/Memcached,设置合理的过期策略。 |
| 异步处理 | 耗时操作(如日志写入、邮件发送)通过线程池或MQ异步化。 |
| 资源池化 | 数据库连接池(HikariCP)、线程池(ForkJoinPool)复用资源。 |
真实案例:某直播平台通过以下组合优化将峰值TPS提升3倍:
- 使用Redis集群缓存用户礼物数据,减少数据库读压力;
- 采用RocketMQ削峰,将弹幕消息异步写入Kafka;
- 数据库分库分表(按房间ID哈希取模)+ 读写分离。
监控与运维实践
分布式系统的复杂性要求全方位的监控体系:
指标监控
- 基础指标:CPU、内存、磁盘IO、网络带宽(Prometheus+Grafana)。
- 业务指标:接口响应时间、错误率、QPS(通过SkyWalking/Pinpoint链路追踪)。
- 自定义指标:如MQ消费延迟、数据库主从同步延迟。
日志管理
- 使用ELK(Elasticsearch+Logstash+Kibana)集中管理日志,设置关键字告警(如“TimeoutException”)。
- 日志分级(INFO/WARN/ERROR)并添加TraceId,便于问题排查。
自动化运维
- 通过Ansible/Terraform实现一键部署,Jenkins完成CI/CD流水线。
- 蓝绿发布或金丝雀发布降低更新风险。
常见问题与解决方案(FAQs)
Q1:分布式系统中如何保证数据一致性?
- 强一致性场景:使用2PC/3PC协议或TCC(Try-Confirm-Cancel)模式,但性能损耗较大。
- 最终一致性场景:通过MQ异步同步数据,结合事务消息(如RocketMQ事务消息)保证可靠性。
- 推荐方案:根据业务优先级选择,例如支付系统采用强一致性,用户画像更新可采用最终一致性。
Q2:如何应对突发流量导致的服务崩溃?
- 限流:使用Sentinel/Hystrix设置每秒请求阈值,超出后快速失败。
- 弹性扩容:结合Kubernetes HPA(Horizontal Pod Autoscaler)自动增加服务实例。
- 缓存预热:提前将热门数据加载到Redis,减少数据库压力。
- 分流策略:通过DNS权重调整或API网关(如Zuul)动态路由流量。