上一篇
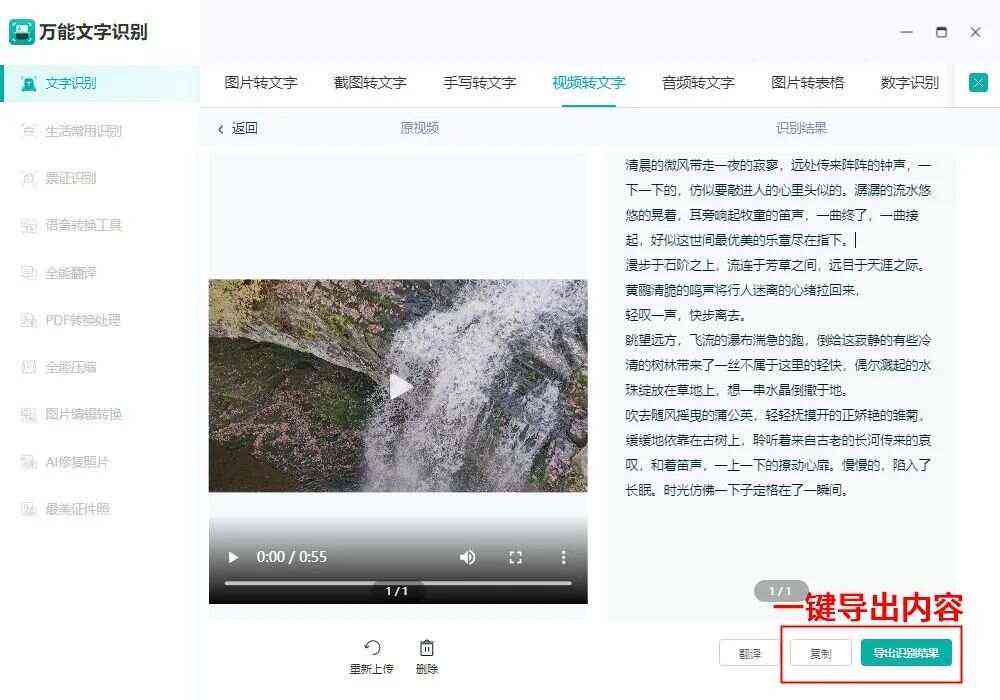
h5识别图片文字
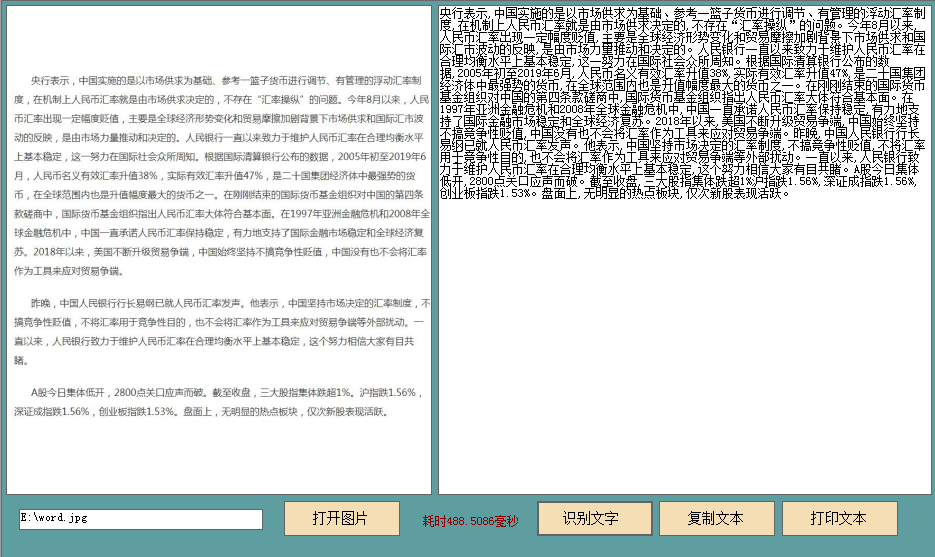
H5可通过调用OCR.js等库或接口,实现图片
H5识别图片文字技术解析与实践指南
技术原理与核心流程
HTML5页面实现图片文字识别主要依赖光学字符识别(OCR)技术,其核心流程分为三个阶段:
- 图像预处理:通过Canvas API调整图片尺寸(建议分辨率300dpi以上)、灰度化、二值化处理
- 文字检测:定位图片中的文字区域,现代算法多采用CTPN(Cascade Text Proposal Network)或EAST(Efficient and Accurate Scene Text Detector)
- 字符识别:将检测到的文字区域转换为计算机可读文本,常用深度学习模型如CRNN(Convolutional Recurrent Neural Network)
主流解决方案对比
| 方案类型 | 代表产品 | 识别精度 | 响应速度 | 免费额度 | SDK体积 | 离线支持 |
|---|---|---|---|---|---|---|
| 浏览器插件 | Tesseract.js | 82% | 3-5秒 | 无限制 | 2MB | |
| 云端API | 百度AI | 97% | 8秒 | 5万次/月 | 5MB | |
| 混合方案 | 酷盾安全+WebAssembly | 95% | 2秒 | 1千次/月 | 1MB |
实现步骤详解
环境准备
<!-引入必要库 --> <script src="https://cdn.jsdelivr.net/npm/tesseract.js@2.1.1/dist/tesseract.min.js"></script> <script src="https://polyfill.io/v3/polyfill.min.js?features=es6"></script>
图像采集与预处理
// 获取用户上传的图片
const inputImage = document.getElementById('upload').files[0];
const reader = new FileReader();
reader.onload = function(e) {
const img = new Image();
img.onload = function() {
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
// 保持原始比例缩放至最大宽度400px
const scale = Math.min(400 / img.width, 300 / img.height);
canvas.width = img.width scale;
canvas.height = img.height scale;
context.drawImage(img, 0, 0, canvas.width, canvas.height);
// 调用OCR识别
recognizeText(canvas);
};
img.src = e.target.result;
};
reader.readAsDataURL(inputImage);OCR核心代码
async function recognizeText(canvas) {
try {
const worker = await Tesseract.createWorker();
const result = await worker.recognize(canvas);
console.log(result.data.text); // 输出识别结果
worker.terminate();
} catch (err) {
console.error('识别失败:', err);
}
}性能优化策略
| 优化方向 | 实施方案 |
|---|---|
| 文件大小控制 | 使用JPEG格式压缩,设置maxWidth/maxHeight参数 |
| 异步处理 | Web Workers分离计算任务,避免阻塞主线程 |
| 缓存机制 | IndexedDB存储已识别结果,设置有效期(如2小时) |
| 网络优化 | 合并API请求,使用HTTP/2协议 |
| 硬件加速 | 启用GPU加速(需检测浏览器支持情况) |
典型应用场景
- 文档数字化:扫描合同/发票自动生成电子版
- 多语言翻译:拍照翻译路牌/菜单(需集成翻译API)
- 表单自动化:识别手写表格数据录入系统
- 辅助阅读:为视障用户提供图片文字转语音服务
注意事项清单
- 跨域问题:配置CORS策略或使用代理服务器
- 隐私保护:敏感信息需本地处理,禁用第三方API
- 版权合规:扫描书籍/文献需遵守著作权法
- 错误处理:设置超时机制(建议5-10秒),提供重试按钮
- 浏览器兼容:IE11+需polyfill,Safari需特殊处理Canvas权限
FAQs
Q1:移动端H5识别出现内存溢出怎么办?
A1:建议采取以下措施:
- 使用
navigator.mediaDevices.getUserMedia代替文件上传 - 设置
canvas.toBlob而非toDataURL减少内存占用 - 启用图片压缩:
context.mozImageSmoothingEnabled = false; - 限制最大处理尺寸(如1920×1080)
Q2:如何提升手写体识别准确率?
A2:优化方案包括:
- 预处理阶段增加去噪算法(如高斯模糊)
- 训练专用手写模型(需收集标注数据集)
- 结合笔画特征分析(如方向梯度直方图)
- 使用Attention机制增强字符关联性识别
- 集成后处理校正(如形近字