上一篇
怎样高效完成服务器与存储的检查与巡检?
服务器和存储巡检需定期检查硬件状态(如电源、风扇、磁盘)、系统性能指标(CPU、内存、磁盘I/O)、日志报错及告警信息,验证备份完整性,更新安全补丁,核对配置合规性,并通过自动化工具生成报告,记录异常并跟踪处理,确保系统稳定性和数据安全。
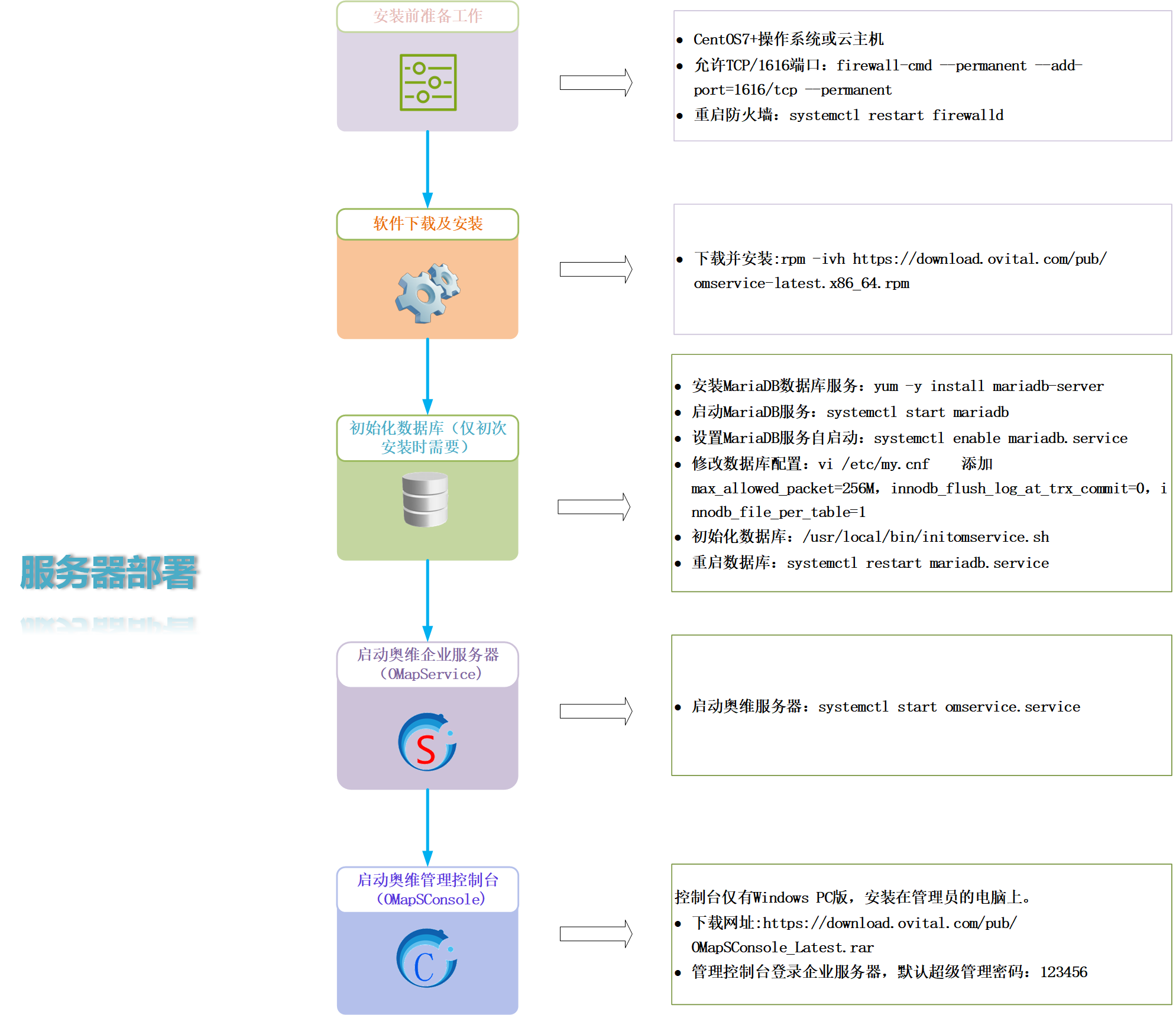
服务器和存储检查巡检方法
在数字化时代,服务器和存储设备是企业和机构的核心基础设施,定期检查与巡检不仅能保障业务连续性和数据安全,还能提前发现潜在风险,避免重大损失,以下是一套详细的服务器和存储巡检方法,适用于IT运维人员或技术管理者参考。

巡检的重要性
- 预防故障:通过定期检查硬件状态、系统日志等,提前发现潜在问题。
- 优化性能:监控资源使用率(如CPU、内存、磁盘I/O),避免性能瓶颈。
- 保障数据安全:存储设备的健康状态直接影响数据完整性,巡检可降低数据丢失风险。
- 合规要求:满足行业或法规对IT基础设施的运维要求(如等保2.0、GDPR)。
服务器检查巡检方法
硬件状态检查
- 物理环境:确认机房温湿度(推荐温度22-24℃、湿度40-60%)、电源稳定性(UPS状态)。
- 硬件组件:
- 检查服务器风扇、电源模块是否正常运转。
- 使用工具(如Dell OpenManage、HP iLO)查看硬盘SMART状态、内存ECC错误记录。
- 记录硬件序列号及保修期限。
系统性能监控
- 资源使用率:
- CPU:持续高于80%需排查进程占用(工具:
top(Linux)、任务管理器(Windows))。 - 内存:检查可用内存是否低于20%,警惕内存泄漏。
- 磁盘I/O:使用
iostat(Linux)或性能监视器(Windows)监控读写延迟。
- CPU:持续高于80%需排查进程占用(工具:
- 网络性能:通过
ping、traceroute检测丢包率与延迟。
日志与告警分析
- 系统日志:重点排查
/var/log/messages(Linux)、事件查看器(Windows)中的Critical或Error级别日志。 - 应用日志:检查数据库(如MySQL慢查询日志)、Web服务(如Nginx/Apache访问日志)异常记录。
- 告警通知:确保监控系统(如Zabbix、Nagios)的告警阈值合理,通知渠道有效。
备份与恢复验证
- 备份完整性:定期测试备份文件是否可恢复(如通过虚拟机快照还原)。
- 灾备演练:模拟单点故障,验证高可用架构(如集群切换、存储双活)是否生效。
安全更新与破绽修复
- 系统补丁:每月检查操作系统(如Windows Update、
yum update)和固件更新。 - 破绽扫描:使用Nessus、OpenVAS扫描已知破绽,及时修复高风险项。
存储设备检查巡检方法
磁盘健康检查
- SMART状态:通过工具(如
smartctl)查看硬盘的读写错误率、坏道数量。 - RAID状态:确认RAID阵列冗余正常(如无降级或失效成员盘)。
- 存储容量:监控存储池使用率(建议保留20%空闲空间,避免性能下降)。
存储性能监控
- 吞吐量:检查每秒读写操作(IOPS)和带宽(MB/s)是否在预期范围内。
- 延迟:重点关注SSD(应低于1ms)和HDD(低于20ms)的响应时间。
链路与连接状态
- 光纤通道/SAN:检查HBA卡端口状态、交换机Zone配置是否正常。
- 网络存储(NAS):验证NFS/CIFS共享的挂载状态和权限设置。
数据一致性校验
- 文件系统:定期运行
fsck(Linux)或chkdsk(Windows)修复错误。 - 快照与克隆:确保存储快照可正常挂载,并测试克隆卷的可用性。
存储策略优化
- 冷热数据分层:将低频访问数据迁移至低成本存储(如对象存储)。
- 去重与压缩:启用存储去重功能(如ZFS或Dell EMC PowerStore)节省空间。
常见问题与处理方法
硬件故障预警
- 现象:硬盘SMART报错、内存ECC错误激增。
- 处理:立即备份数据并更换故障部件,避免影响生产环境。
性能瓶颈
- 现象:CPU/磁盘长期高负载。
- 处理:优化SQL查询、升级硬件或横向扩展集群节点。
存储容量不足
- 现象:存储池使用率超过90%。
- 处理:清理冗余数据、扩容存储或启用自动扩容策略。
推荐工具与平台
- 监控工具:Prometheus(开源)、SolarWinds(商业)、Grafana(可视化)。
- 日志分析:ELK Stack(Elasticsearch、Logstash、Kibana)。
- 存储管理:NetApp ONTAP Tools、IBM Spectrum Control。
最佳实践建议
- 制定巡检计划:按周/月/季度分级别检查,关键系统每日监控。
- 记录巡检结果:使用表格或运维管理系统(如Jira、ServiceNow)留存历史数据。
- 团队协作:明确责任人,定期组织跨部门演练(如容灾切换)。
- 自动化巡检:通过脚本(Python/Shell)或Ansible批量执行常规检查。
引用说明
本文参考了戴尔服务器硬件手册、华为存储技术白皮书、微软Windows Server文档及红帽Linux官方运维指南,具体数据指标基于行业通用标准,实际参数需结合设备厂商建议调整。