上一篇
GPU服务器内存类型对性能影响有多大?
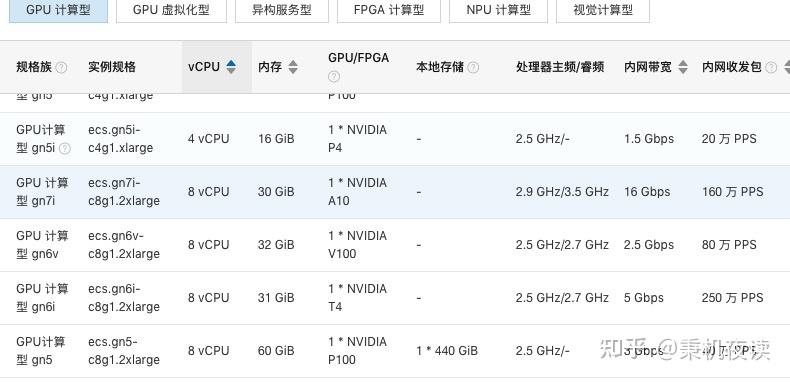
GPU服务器通常配备GDDR或HBM类型显存,用于加速图形和计算任务,GDDR(如GDDR6)提供高带宽,适合通用计算;HBM(如HBM2/HBM3)通过堆叠设计实现更高带宽和能效,多用于AI及高性能计算,系统内存则多为DDR4/DDR5,支持CPU通用数据处理,与显存分工协作。
在深度学习、人工智能和高性能计算(HPC)领域,GPU服务器的性能表现与内存类型密切相关,内存的带宽、容量和延迟直接影响计算任务的效率,以下从技术原理、类型对比、选型建议等维度详细解析GPU服务器内存的核心知识,帮助用户做出科学决策。
GPU显存:加速计算的核心载体
GPU显存(Video RAM)是显卡专用的高速内存,负责存储渲染数据、计算中间结果和模型参数,其类型直接决定并行计算能力。
GDDR系列:平衡成本与性能
- GDDR6/GDDR6X
当前主流显存类型,带宽达600-1000 GB/s,单颗粒容量8-16Gb,采用PAM4信号调制技术,在相同频率下实现双倍数据传输,NVIDIA RTX 3090/4090、AMD Radeon RX 6000系列均采用此技术。 - GDDR5/GDDR5X
逐步被淘汰,但仍用于中低端显卡,带宽约200-400 GB/s,成本较低。
HBM(高带宽内存):高性能计算的标杆
- HBM2/HBM2E
通过3D堆叠技术将DRAM芯片垂直堆叠,带宽达1.2-1.6 TB/s,功耗比GDDR低30%,NVIDIA A100、AMD Instinct MI200系列搭载HBM2E,适合大规模矩阵运算。 - HBM3
最新一代技术,带宽突破2 TB/s,单堆栈容量提升至24GB,NVIDIA H100及Intel Ponte Vecchio已采用,适用于超算场景。
显存技术对比表
| 类型 | 带宽范围 | 容量优势 | 典型应用场景 |
|---|---|---|---|
| GDDR6X | 600-1000 GB/s | 中等 | 游戏、轻量级AI推理 |
| HBM2E | 2-1.6 TB/s | 高 | 深度学习训练、HPC |
| HBM3 | >2 TB/s | 极高 | 超算、量子模拟 |
系统内存:CPU与GPU的协作枢纽
系统内存(主内存)为CPU提供数据缓存,并通过PCIe通道与GPU交互,其性能影响整体数据吞吐效率。
DDR4/DDR5:通用型内存
- DDR4
主流服务器配置,频率3200-4800 MHz,带宽25.6-38.4 GB/s(单通道),优势在于高兼容性和成熟生态。 - DDR5
新一代标准,频率4800-7200 MHz,带宽提升至38.4-67.2 GB/s,支持ECC纠错,Intel Xeon Scalable第四代及AMD EPYC 9004系列已全面支持。
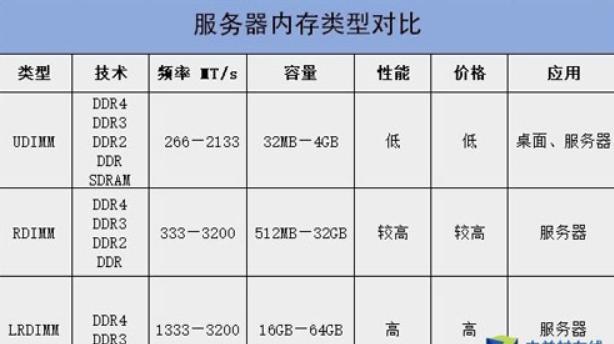
LRDIMM(低负载内存)
通过缓冲器减少信号负载,支持单条256GB容量,适用于高密度数据存储场景,如分布式训练集群。

关键技术:释放内存潜力的核心
NVLink/InfiniBand
NVIDIA的NVLink 4.0提供900 GB/s的GPU间直连带宽,避免通过PCIe总线造成的延迟,IBM Power10和AMD CDNA2架构均支持类似技术。
统一内存架构(UMA)
AMD MI300等APU允许CPU和GPU共享物理内存,减少数据复制开销,特别适合异构计算任务。
显存虚拟化
NVIDIA MIG(多实例GPU)技术将单GPU显存划分为多个独立实例,提升资源利用率。
选型指南:按场景匹配内存类型
AI训练与推理
- 推荐HBM3显存+DDR5系统内存,确保大规模参数的高效加载。
- 带宽需求:≥1 TB/s(显存),≥50 GB/s(系统内存)。
科学计算(CFD/分子动力学)
选择HBM2E显存+LRDIMM系统内存,平衡带宽与容量。
图形渲染与实时仿真
GDDR6X显存+DDR5内存组合,性价比最优。
未来趋势
- CXL(Compute Express Link)协议
实现CPU、GPU和内存池化,打破传统内存访问瓶颈。 - 3D堆叠DRAM
Samsung的HBM-PIM将处理单元嵌入内存层,减少数据搬运能耗。
参考资料
- NVIDIA H100架构白皮书, 2025
- JEDEC DDR5标准文档, JESD79-5B
- AMD Instinct MI300技术简报, 2025
- ISSCC 2025内存技术专题报告