上一篇
分布式服务器搭建
分布式服务器搭建需规划架构与技术选型,配置节点,保障通信
分布式服务器搭建核心概念
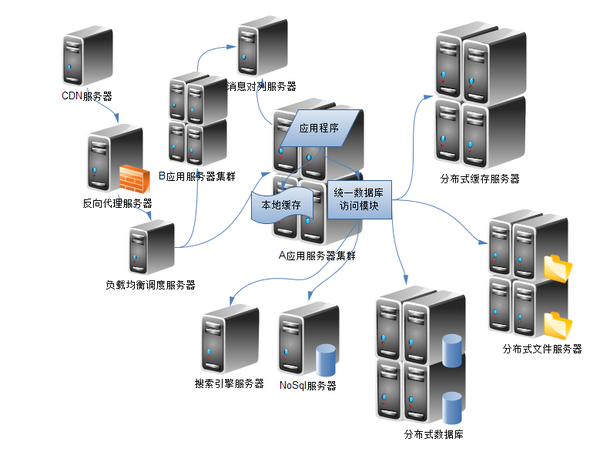
分布式服务器系统通过多台服务器协同工作,实现计算资源、存储资源和网络资源的整合与分配,其核心目标是提升系统可用性(高可用)、扩展性(横向扩展)和性能(负载均衡),与传统单机架构相比,分布式架构需解决数据一致性、服务协调、故障转移等复杂问题。

关键特性对比表
| 特性 | 单机架构 | 分布式架构 |
|---|---|---|
| 可用性 | 依赖单点设备 | 多节点冗余(如主从/集群) |
| 扩展性 | 纵向升级(硬件堆砌) | 横向扩展(增加节点) |
| 性能瓶颈 | CPU/内存/磁盘I/O | 网络延迟、分布式锁竞争 |
| 数据一致性 | 本地事务保证 | 需分布式事务协议(如2PC) |
分布式架构设计要点
核心组件规划
- 负载均衡层:分发请求至后端服务器(如Nginx、HAProxy)
- 应用服务层:无状态服务集群(如Spring Cloud微服务)
- 数据存储层:分片数据库(如MySQL Cluster)或分布式存储(如Ceph)
- 缓存层:Redis/Memcached集群
- 协调服务:ZooKeeper/Etcd(服务注册与发现)
负载均衡策略
| 策略类型 | 适用场景 | 代表工具 |
|---|---|---|
| 轮询 | 请求均匀分布 | Nginx upstream |
| IP哈希 | 用户会话保持 | HAProxy |
| 加权轮询 | 不同服务器性能差异 | LVS(Linux虚拟服务器) |
| 最小连接数 | 长连接场景 | Keepalived |
数据分片与复制
- 分片规则:基于用户ID、时间范围或哈希值(如Consistent Hashing)
- 复制策略:主从复制(MySQL)、多副本同步(MongoDB)
- CAP定理权衡:根据业务选择CP(强一致性)或AP(高可用)
技术选型与工具链
主流分布式框架
| 框架类型 | 代表工具 | 适用场景 |
|---|---|---|
| 服务网格 | Istio/Linkerd | 微服务通信管理 |
| 容器编排 | Kubernetes/Docker Swarm | 自动化部署与扩缩容 |
| 分布式数据库 | CockroachDB/TiDB | 跨区域高可用数据存储 |
| 消息队列 | Kafka/RabbitMQ | 异步任务处理与流量削峰 |
高可用设计模式
- 主备模式:Active-Standby(如数据库主从)
- 多活模式:Multi-Active(如全球多数据中心)
- 自愈机制:健康检查(Health Check)+ 自动重启(Systemd/Supervisor)
部署实施步骤
环境准备
- 网络规划:划分内网(RPC通信)、公网(用户访问)、心跳检测网络
- 系统配置:关闭防火墙(或开放必要端口)、NTP时间同步、SSH密钥认证
- 依赖安装:JDK/Python环境、Docker/Podman、Ansible/Terraform
核心服务部署流程
- 负载均衡器:配置Nginx Upstream模块,定义后端服务器组
upstream backend { server 192.168.1.101:8080 weight=3; server 192.168.1.102:8080 backup; } - 应用服务集群:通过Docker Compose启动多实例
version: '3' services: app: image: myapp:latest deploy: replicas: 3 update_delay: 30s - 数据库分片:使用ShardingSphere进行逻辑分库分表
dataSources: ds_0: url: jdbc:mysql://192.168.1.201:3306/db_0?serverTimezone=UTC ds_1: url: jdbc:mysql://192.168.1.202:3306/db_1?serverTimezone=UTC
监控与日志系统
- 监控工具:Prometheus(指标采集)+ Grafana(可视化)
- 日志聚合:ELK Stack(Elasticsearch/Logstash/Kibana)
- 告警规则:CPU使用率>80%触发邮件/钉钉通知
性能优化策略
缓存穿透防护
- 布隆过滤器:拦截不存在的Key请求(如Redis+BloomFilter)
- 空值缓存:对查询结果为空的数据设置短时效缓存
分布式锁优化
- Redlock算法:基于Redis的分布式锁实现(需5个实例多数决)
- 锁粒度控制:按业务维度拆分锁(如订单锁、库存锁分离)
流量控制
- 漏桶算法:平滑处理突发流量(如Nginx限流模块)
- 熔断机制:Hystrix/Resilience4j实现服务降级
典型故障处理方案
| 故障类型 | 现象 | 解决方案 |
|---|---|---|
| 脑裂问题 | 主备节点同时对外服务 | 添加仲裁机制(如ZooKeeper选举) |
| 数据不一致 | 读写分离导致新旧数据冲突 | 强制读主库或开启GTID复制 |
| 雪崩效应 | 服务级联崩溃 | 限流+熔断+异步重试机制 |
实战案例:电商瞬秒系统架构
业务需求
- 峰值TPS:10万/秒
- 数据一致性:库存扣减需原子性
- 成本控制:资源弹性伸缩
架构设计
- 前置层:CDN缓存静态资源,Nginx作为SLB
- 逻辑层:Sentinel限流+DubboRPC调用
- 数据层:Redis集群处理热点数据,MySQL分库分表
- 异步处理:Kafka削峰填谷,处理订单日志
FAQs
Q1:如何选择分布式事务解决方案?
A:优先采用业务层面的最终一致性方案(如补偿机制),若必须强一致则选用TCC(Try-Confirm-Cancel)模式,避免使用XA协议因其性能损耗较大。
Q2:如何排查分布式系统慢请求?
A:1. 通过Zipkin/Jaeger追踪请求链路;2. 检查各节点监控指标(如JVMGC频率);3. 分析慢日志定位数据库/