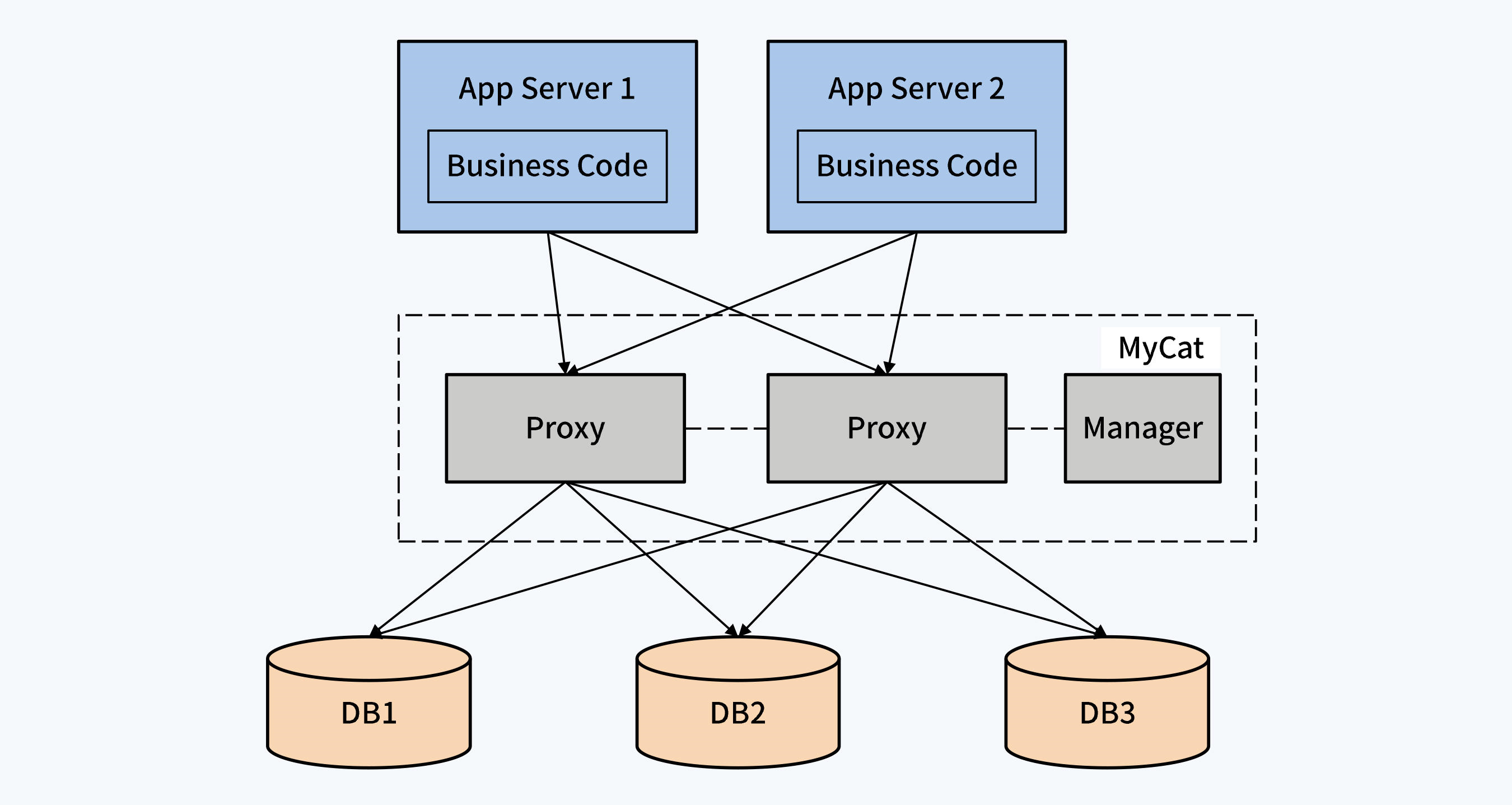
上一篇
分布式数据库选型
分布式数据库选型需综合评估数据一致性、扩展性、容错性、性能及成本,结合业务场景需求与技术生态,选择最优平衡
分布式数据库选型核心要素与主流产品对比分析
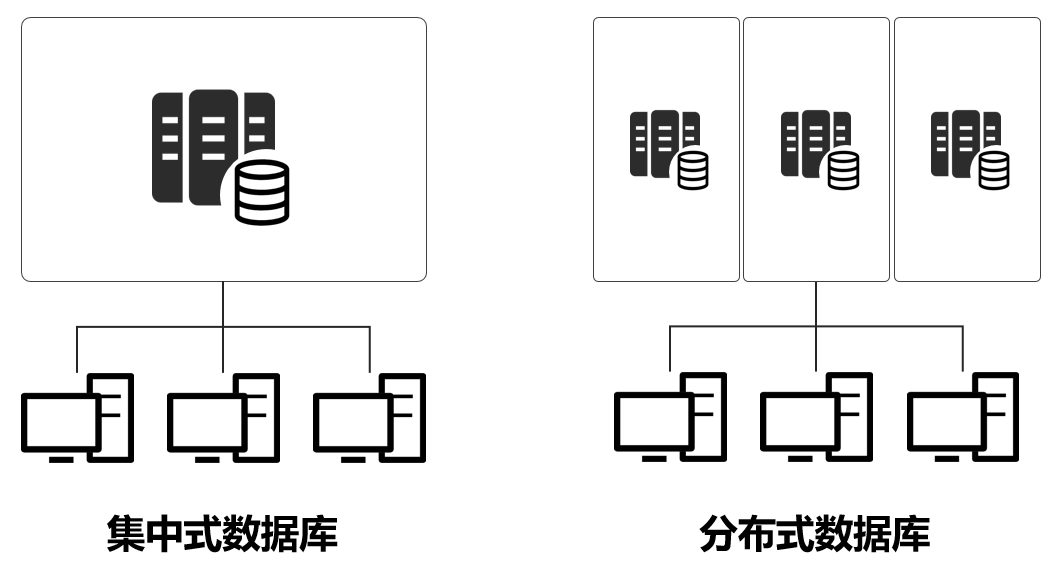
分布式数据库的核心特征与适用场景
分布式数据库通过多节点协同实现数据存储与计算,其核心价值在于解决传统单机数据库的容量瓶颈、性能天花板和单点故障风险,根据Gartner定义,现代分布式数据库需满足以下技术特征:
| 技术维度 | 具体要求 |
|---|---|
| 扩展性 | 支持水平扩展(Scale-out),可线性扩展至百/千节点 |
| 高可用性 | 具备自动故障转移机制,数据副本数可配置(3个) |
| 一致性模型 | 支持强一致性(如2PC)、最终一致性等多种模式 |
| 数据分片 | 支持哈希分片、范围分片、目录分片等策略,支持动态分片调整 |
| 事务处理 | 支持ACID事务(OLTP场景)或最终一致性(高并发场景) |
| SQL兼容性 | 兼容标准SQL(ANSI SQL)或特定数据库方言(如MySQL/PostgreSQL协议) |
典型应用场景包括:大规模电商平台订单处理、金融级交易系统、物联网设备数据存储、实时数据分析等需要高并发、低延迟和弹性扩展的场景。
分布式数据库选型关键评估维度
数据模型适配性
- 关系型(如CockroachDB、TiDB):适合结构化数据和复杂事务
- NoSQL(如Cassandra、HBase):适合非结构化/半结构化数据
- NewSQL(如Google Spanner、PolarDB):融合关系模型与分布式能力
- 时序数据库(如TimescaleDB):专为时间序列数据优化
CAP定理权衡
| 数据库类型 | 一致性 | 可用性 | 分区容错性 | 典型场景 |
|——————|————|————|————|————————–|
| 强一致性数据库 | AP优先 | CP优先 | 高 | 金融交易、订单系统 |
| 最终一致性数据库 | CP优先 | AP优先 | 高 | 社交Feed、日志收集 |性能指标对比
- 吞吐量:Cassandra(万级QPS)> TiDB(千级QPS)> CockroachDB(百级QPS)
- 延迟:内存数据库(Redis Cluster)< NewSQL(<10ms)< 传统分布式(10-50ms)
- 扩展比:VoltDB(线性扩展)> Greenplum(接近线性)> 传统分库分表(非线性)
运维复杂度矩阵

- 自动化程度:云原生数据库(Aurora、PolarDB)> 开源数据库(TiDB)> 传统DB(Oracle RAC)
- 监控体系:商业版(含完整Dashboard)> 云服务(基础监控)> 开源方案(需自建)
- 备份恢复:支持增量备份、PITR(Point-in-Time Recovery)为佳
成本考量
- 授权费用:开源(如Cassandra)< 社区版(如CockroachDB)< 商业版(如DB2)
- 硬件成本:计算存储分离架构(如TiDB+TiKV)> 共享存储架构(如Greenplum)
- 运维成本:托管云服务(AWS Aurora)< 自建集群(需DBA团队)
主流分布式数据库横向对比
| 产品 | 架构类型 | 数据模型 | 强一致性 | 扩展方式 | 最佳场景 |
|---|---|---|---|---|---|
| TiDB | NewSQL | 关系型 | 可配置RC | 水平扩展 | 互联网业务、混合负载 |
| CockroachDB | NewSQL | 关系型 | 强线性iz | 自动分片 | 金融级应用、多活数据中心 |
| Cassandra | NoSQL(宽列) | 键值+列族 | 最终一致 | 节点追加 | 大规模写操作、时序数据 |
| HBase | NoSQL(列式) | 键值+列式 | 强一致性 | 区域服务器 | 离线分析、海量存储 |
| Spanner | NewSQL(全球分布) | 关系型 | 强同步 | 多维度分片 | 跨国企业、低延迟全球访问 |
| PolarDB | NewSQL(云原生) | 关系型 | 强一致 | 存储计算分离 | 电商峰值、弹性扩展 |
| Greenplum | MPP数据仓库 | 关系型 | 最终一致 | 纵向扩展 | PB级数据分析、BI报表 |
典型选型案例:
- 某电商平台:采用PolarDB实现秒级弹性扩容,支撑双11百万TPS峰值
- 金融机构:使用CockroachDB构建跨AZ多活集群,满足PCI DSS合规要求
- 物联网平台:部署Cassandra集群处理千万级设备心跳数据,存储成本降低40%
选型决策树建议
业务需求优先级排序:
- 首要保障数据一致性 → 选择Spanner/CockroachDB
- 追求极致写入性能 → Cassandra/HBase
- 现有MySQL生态迁移 → TiDB/PolarDB
- 混合OLAP分析需求 → Greenplum/ClickHouse
技术成熟度评估:
生产环境推荐:云厂商托管服务(Aurora/Azure Cosmos DB)> 社区稳定版(TiDB 5.x)> 测试阶段新技术
渐进式演进路径:
- 初期:分库分表中间件(如ShardingSphere)过渡
- 中期:引入NewSQL替代传统分片
- 长期:混合存储架构(OLTP+OLAP一体化)
常见误区规避
误区1:”所有业务都需要分布式”
纠正:仅当单节点瓶颈(QPS>2k/存储TB级)或高可用要求(SLA>99.99%)时才需分布式误区2:”开源数据库等于免费”
纠正:需考虑运维成本(如Cassandra需自建监控)、硬件成本(如分片导致资源碎片)误区3:”云数据库无厂商锁定”
注意:需评估数据导出难度(如DynamoDB需自定义工具)、API兼容性、生态工具链
FAQs
Q1:如何判断业务是否需要分布式数据库?
A1:当出现以下任一情况时需考虑分布式:
- 单表数据量超过亿级且查询性能下降
- 写QPS持续超过单机承载能力(如MySQL约5k)
- 需要跨地域多活部署
- 业务存在明显波峰波谷(如电商大促)
Q2:从传统数据库迁移到分布式数据库的最大挑战是什么?
A2:主要挑战包括:
- 数据分片策略设计:需重新规划主键、索引和分片键
- 事务一致性保障:跨分片事务需处理分布式锁和协调协议
- 运维复杂度提升:需掌握分片管理、负载均衡、故障诊断等新技能
- 生态工具链适配:部分分布式数据库暂不支持传统ORM框架或监控工具