
上一篇
分布式数据库 pdf
分布式数据库通过数据分片与多节点协同实现数据存储与管理,具备高可用、可扩展
分布式数据库核心解析与实践指南
基础概念与核心特征
分布式数据库(Distributed Database)是一种通过计算机网络将物理上分散的数据库节点连接成逻辑整体的数据管理系统,其核心目标是实现数据的高可用性、水平扩展能力和地理分布适应性,与传统集中式数据库相比,分布式数据库通过数据分片(Sharding)、多副本冗余、分布式事务管理等技术,突破单点性能瓶颈。
| 核心特征 | 具体表现 |
|---|---|
| 高可用性 | 通过多副本机制(如Raft/Paxos协议)实现节点故障自动切换 |
| 弹性扩展 | 支持在线横向扩展(Add Node),无需停机即可增加计算/存储资源 |
| 透明性 | 对应用程序屏蔽数据分布细节,提供类似单机数据库的SQL接口 |
| 地理分布支持 | 数据可部署在多个数据中心,满足低延迟访问和灾备需求 |
架构设计关键要素
CAP定理的权衡
分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance),典型策略:- CP优先(如HBase):强一致性但牺牲部分可用性
- AP优先(如Cassandra):高可用但允许临时不一致
- BASE理论:通过最终一致性(Eventual Consistency)平衡性能与可靠性
数据分片策略
| 分片类型 | 适用场景 | 示例 |
|—————-|———————————-|——————————-|
| 哈希分片 | 均匀分布负载 | 订单ID取模分配到不同节点 |
| 范围分片 | 连续查询优化 | 时间序列数据按日期范围划分 |
| 目录分片 | 多维度查询需求 | 用户画像按地域+年龄组合分片 |副本管理机制

- 同步复制:强一致性保障(如MySQL Group Replication)
- 异步复制:高吞吐量但存在数据丢失风险(如MongoDB默认配置)
- 多数派协议:通过Quorum机制平衡性能与一致性(如DynamoDB)
核心技术实现
分布式事务管理
- 两阶段提交(2PC):阻塞式强一致性协议,存在性能瓶颈
- TCC(Try-Confirm-Cancel):补偿机制降低锁竞争
- 基于时间戳的多版本控制:通过MVCC实现读写分离(如CockroachDB)
共识算法演进
| 算法 | 通信复杂度 | 容错性 | 典型应用 |
|—————|————|——–|—————————|
| Paxos | 3轮 | 半数 | etcd/Consul |
| Raft | 2轮 | 半数 | TiKV/etcd |
| Zab(ZooKeeper)| 广播 | 半数 | Kafka/HBase |负载均衡策略
- 静态分片:预先规划分片规则,适用于稳定负载场景
- 动态迁移:基于实时负载的Hotspot迁移(如ShardingSphere)
- 代理层路由:通过DNS/硬件负载均衡器实现请求分发
典型应用场景对比
| 场景 | 关键需求 | 推荐方案 | 配置要点 |
|---|---|---|---|
| 电商平台订单系统 | 高并发写入、强一致性 | TiDB/CockroachDB | 采用Raft协议+多副本部署 |
| 社交网络Feed流 | 低延迟读取、海量数据 | Cassandra/MongoDB | 异步复制+LSM树存储优化写入性能 |
| 金融交易系统 | ACID事务、监管合规 | PostgreSQL XC/Google Spanner | 同步复制+全局时钟保证顺序性 |
| 物联网设备数据 | 高吞吐写入、离线处理 | TimescaleDB/InfluxDB | 列式存储+数据降采样策略 |
运维挑战与解决方案
数据倾斜问题
- 现象:热点分片成为性能瓶颈
- 解决:虚拟分片(Virtual Sharding)+ 自动Rebalance机制
跨节点查询优化
- 代价:分布式SQL执行涉及多节点数据传输
- 方案:智能路由+本地化计算(如Greenplum的MPP架构)
故障检测与恢复
- 心跳机制:每秒检测节点状态
- 自动Failover:基于Raft选举新主节点(<5秒切换)
- 数据修复:后台增量校验+差异同步
与传统数据库对比分析
| 维度 | 分布式数据库 | 传统关系型数据库 |
|---|---|---|
| 扩展性 | 线性水平扩展(每新增节点提升性能) | 垂直扩展受限于硬件天花板 |
| 成本模型 | 按需扩展,长期成本低 | 初期成本低,扩容成本陡峭 |
| 地理部署 | 支持多活数据中心 | 通常单中心部署 |
| 开发复杂度 | 需处理分布式事务/数据一致性 | SQL标准接口,开发简单 |
前沿发展趋势
- 云原生化:与Kubernetes深度集成,实现存储计算分离(如AWS Aurora)
- AI驱动优化:基于机器学习预测负载,动态调整分片策略
- 多模数据处理:支持JSON/XML/时序等多种数据类型混合存储
- 边缘协同:在IoT场景中实现云端-边缘端数据分级处理
FAQs
Q1:如何选择分布式数据库的分片键?
A1:需满足三个原则:①高频查询条件字段(如用户ID);②均匀分布性(避免热点);③业务语义完整性(如订单按用户分片便于查询历史记录),建议通过采样数据分析基尼系数评估分布均匀度。
Q2:分布式数据库的读写性能如何优化?
A2:关键措施包括:①读写分离架构(一主多从);②向量化执行引擎;③索引预建策略;④内存计算缓存(如Redis旁路加速);⑤批量写入优化(如Sink并行处理),实测表明,TiDB在SYSBENCH测试中通过向量化优化可使
相关文章

PDFFactory Pro服务器版:更快,更高效的PDF打印解决方案 (pdffactory pro服务器版)
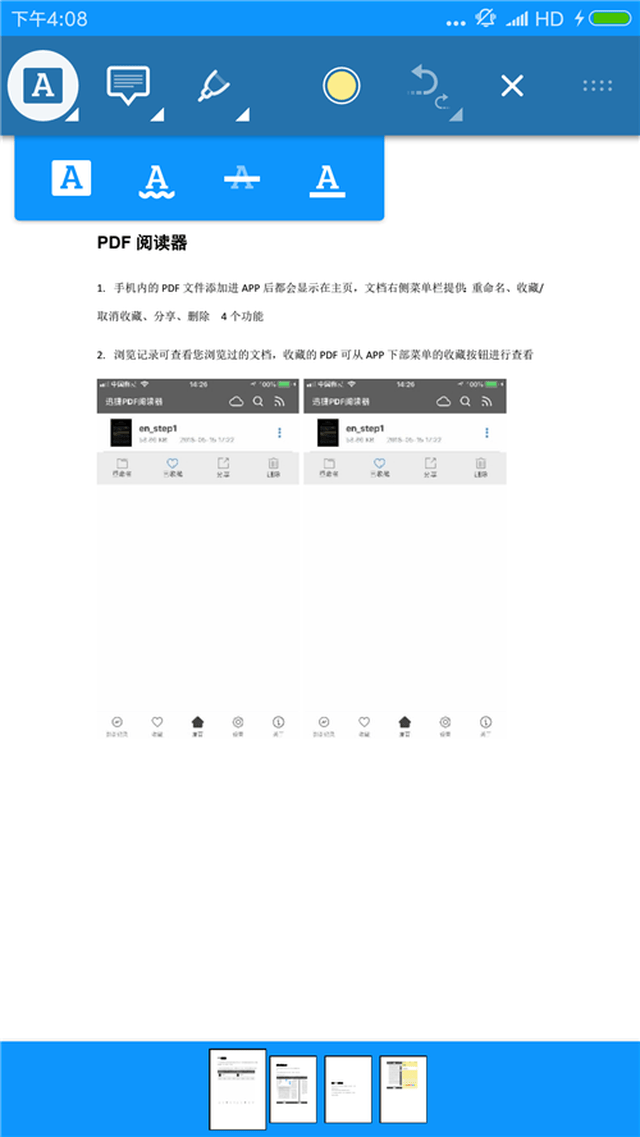
pdfbox操作pdf文件 _下载报告PDF
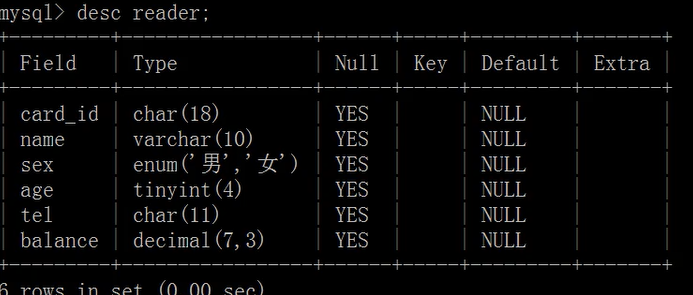
如何高效下载并使用MySQL数据库管理实战PDF,实战报告PDF获取指南?

大数据解决方案pdf_下载报告PDF

离散傅里叶变换(DFT)是一种将时域信号转换为频域信号的数学工具。它通过傅里叶分析,把时间或空间域中的信号转换到频率域,从而揭示信号的频谱结构和变化规律。,基于DFT的原理和特性,我们可以提出以下疑问,,如何优化DFT算法以减少计算复杂度?,要学以致用,您可以思考如何运用快速傅里叶变换(FFT)算法来降低离散傅里叶变换(DFT)的计算复杂度。FFT通过递归分治策略将长序列分解为更短的序列,从而显著减少了乘法运算的次数。探索如何实现这一优化,并考虑其在实际信号处理中的应用。
cloudflare加速(Cloudflare加速)(cloudflare加速器)「cloudflare加速国内网站」
pdflib与其他PDF库相比有何独特之处?
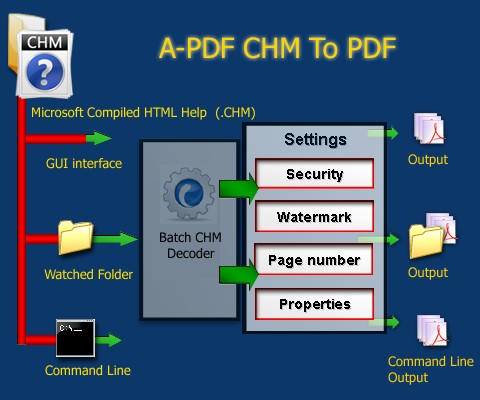
如何在Linux系统下使用chm2pdf工具将CHM文件转换为PDF?








