上一篇
互联网bi分析系统软件
互联网BI分析系统软件整合多源数据,实现可视化分析,助力
核心功能模块
| 模块分类 | 功能描述 |
|---|---|
| 数据集成 | 支持多源数据接入(数据库、API、文件、爬虫数据),具备ETL(抽取-转换-加载)能力 |
| 分析处理 | 提供OLAP(联机分析处理)、数据挖掘、预警规则配置、智能诊断等核心功能 |
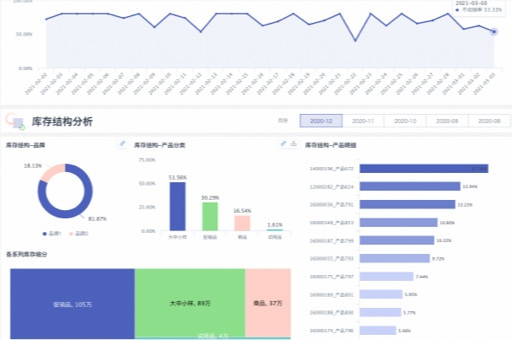
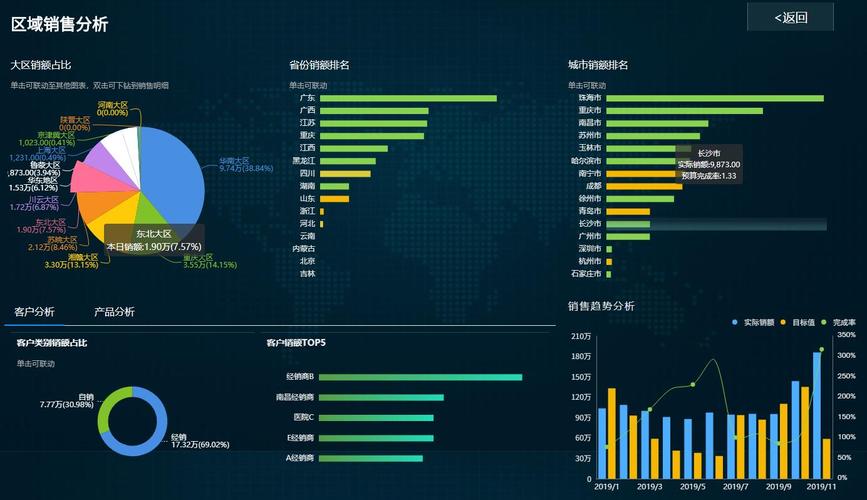
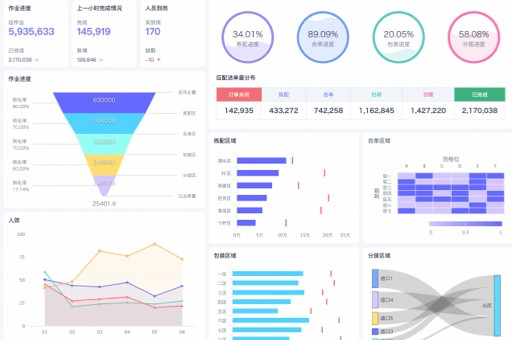
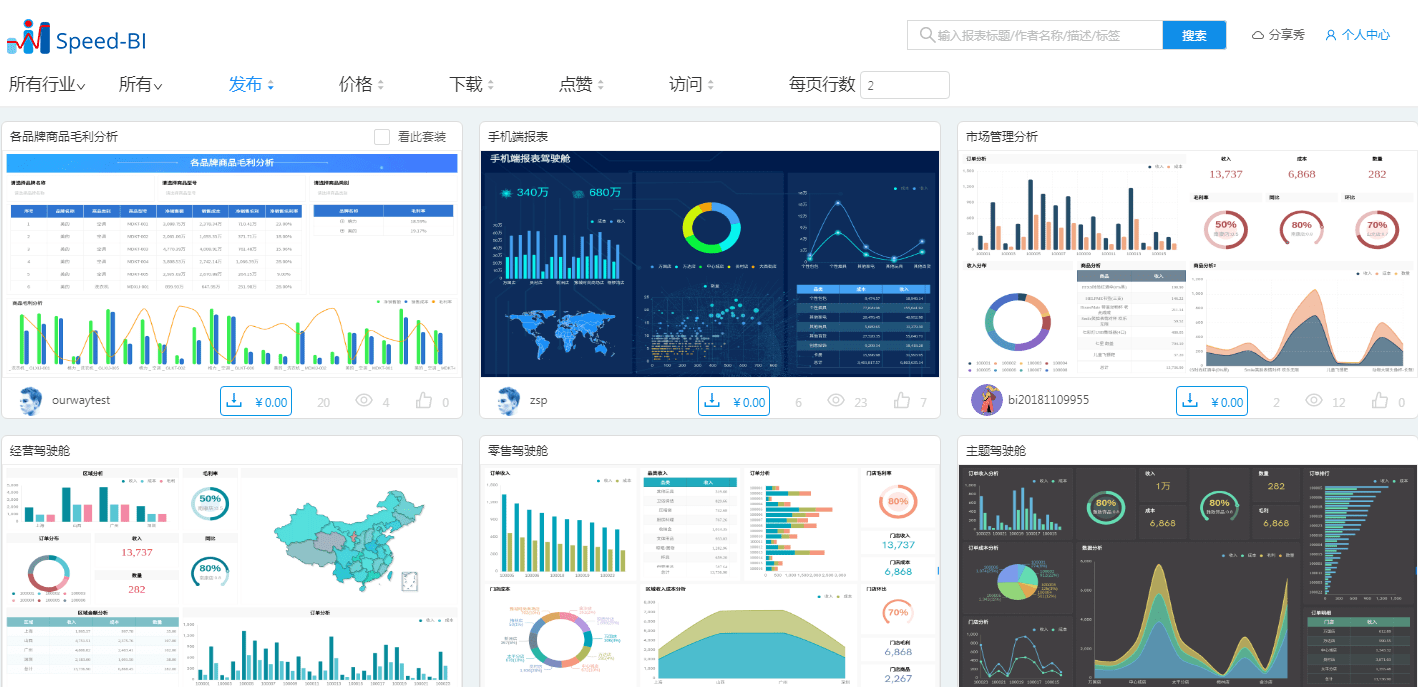
| 可视化 | 支持表格、图表(柱状图/折线图/饼图等)、地理地图、仪表盘、自定义组件开发 |
| 权限管理 | 细粒度权限控制(行级/列级权限)、角色分级、数据脱敏、审计日志 |
| 协作共享 | 报告分享、定时调度邮件推送、多终端访问(PC/移动端)、评论标注功能 |
技术架构解析
| 层级 | 技术组件示例 | 功能说明 |
|---|---|---|
| 数据层 | Kafka/Flume、Hadoop HDFS、MySQL/Oracle | 数据采集与存储,支持批处理(HDFS)和流处理(Kafka) |
| 计算层 | Spark、Flink、ClickHouse | 分布式计算引擎,处理TB/PB级数据,支持实时/离线分析 |
| 服务层 | Spring Boot微服务框架、RESTful API | 提供数据接口、任务调度、权限校验等后端服务 |
| 展示层 | React/Vue前端框架、ECharts/AntV可视化库 | 交互式界面开发,支持响应式布局和组件化开发 |
典型应用场景
电商领域
- 用户行为分析:通过漏斗模型优化转化路径
- 库存预警:结合销售预测与库存阈值动态提醒
- 竞品监测:爬取对手价格数据生成比价看板
金融行业
- 风控建模:基于历史交易数据的欺诈检测模型训练
- 实时监控:交易异常波动触发熔断机制
- 监管报表:自动生成符合银监会要求的统计报表
互联网运营

- 流量分析:UV/PV/DAU多维度拆解,渠道效果归因
- A/B测试:多版本页面转化率对比分析
- 用户画像:整合行为数据构建RFM分层模型
系统选型关键指标
| 评估维度 | 重要性权重 | 考察要点 |
|---|---|---|
| 功能覆盖度 | 30% | 是否支持复杂事件处理、预测性分析等进阶功能 |
| 性能表现 | 25% | 亿级数据查询响应时间(<3s为佳)、并发用户数支撑能力 |
| 可扩展性 | 20% | 横向扩展能力(节点扩容)、纵向功能拓展(插件生态) |
| 实施成本 | 15% | 授权费用(开源/闭源)、硬件投入、定制化开发人天成本 |
| 厂商服务 | 10% | 技术支持响应速度、培训体系完善度、行业案例经验 |
部署与运维要点
本地化部署
- 硬件配置:建议采用分布式集群(至少3个DataNode+2个NameNode)
- 网络规划:独立部署报表服务器与数据仓库,设置防火墙隔离
- 灾备方案:每日增量备份+每周全量备份,异地容灾中心建设
云服务模式
- 优势:弹性扩容、按需付费、免去硬件运维
- 主流选择:阿里云BI(Quick BI)、AWS QuickSight、Azure Power BI
- 注意点:需评估数据出境合规性及长期使用成本
数据治理体系
- 元数据管理:建立全局数据字典,记录字段血缘关系
- 质量监控:设置完整性校验规则(如主键唯一性检查)
- 生命周期管理:冷热数据分层存储策略(热数据SSD/冷数据HDD)
问题与解答
Q1:如何处理实时性要求高的业务场景?
A:需采用流式计算架构,通过Kafka进行数据管道传输,结合Flink实现窗口计算(如5分钟滚动窗口),建议部署边缘计算节点就近处理数据,核心系统负责聚合分析,可达到亚秒级延迟。
Q2:系统扩展时如何保证兼容性?
A:优先选择支持混合部署模式的系统,通过容器化(Docker/K8s)实现平滑扩容,需验证新版本对现有自定义报表/数据接口的兼容情况,建议建立版本管理机制和灰度发布