上一篇
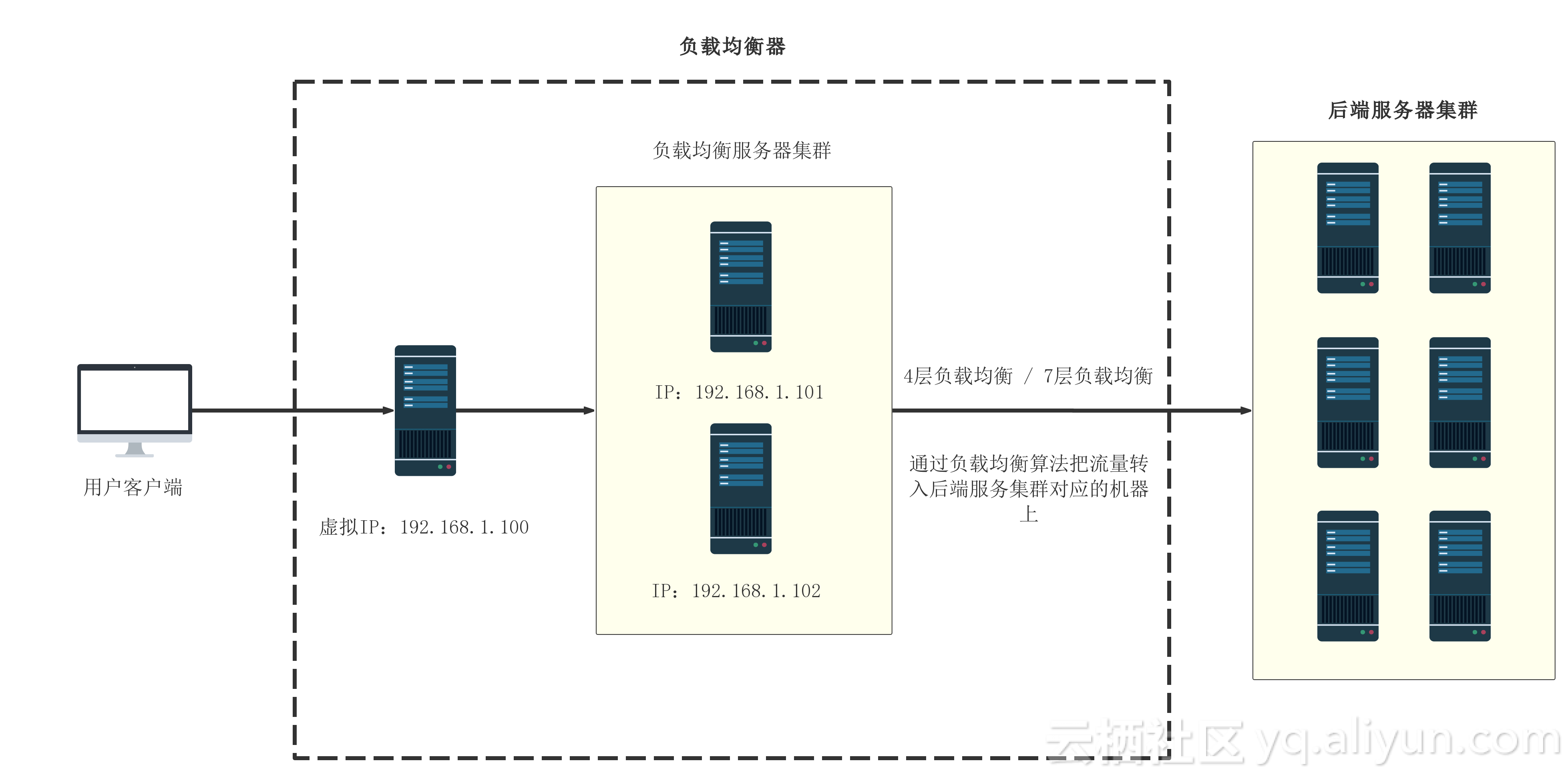
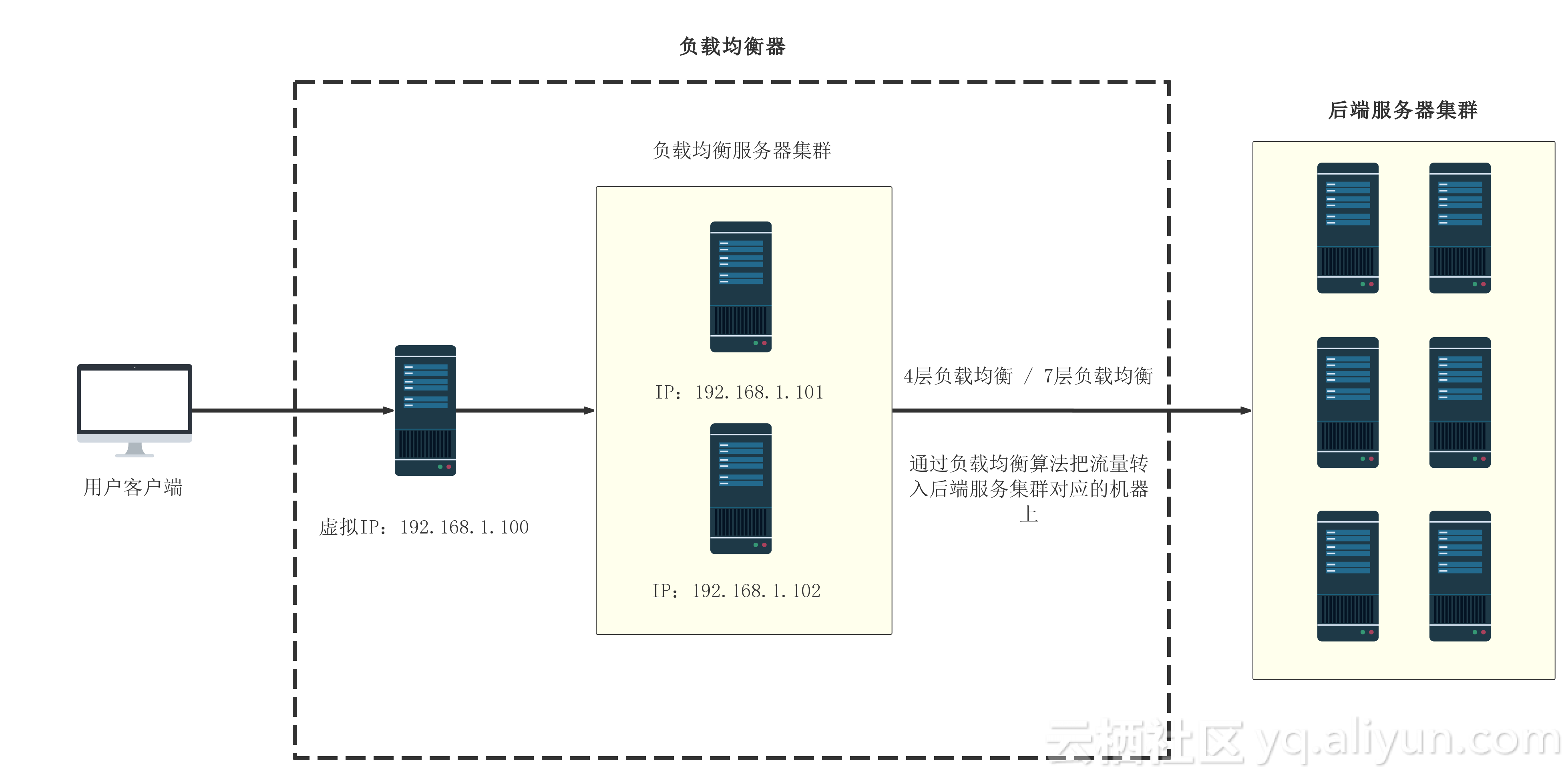
ha负载均衡剔除异常
HA负载均衡通过健康检查实时监测节点状态,自动剔除响应超时、错误率过高的异常节点,结合故障转移机制将流量分配至健康节点,确保服务连续性,待异常恢复后动态调整回
HA负载均衡剔除异常节点的机制与实践
在高可用(High Availability,简称HA)集群架构中,负载均衡器的核心任务之一是动态识别并剔除异常节点,以确保流量仅分配到健康节点,这一过程涉及异常检测、状态同步、流量切换等多个环节,以下从技术原理、实现方式、常见问题等角度展开详细分析。
HA负载均衡剔除异常的核心逻辑
| 核心环节 | 说明 |
|---|---|
| 健康检查 | 通过主动探测(如TCP连接、HTTP请求)或被动监控(如应用层反馈)判断节点状态 |
| 状态同步 | 将节点健康状态同步到所有负载均衡实例,确保决策一致性 |
| 动态剔除与恢复 | 异常节点被移出可用池,恢复后重新加入并触发流量分配 |
| 会话保持 | 避免因节点切换导致用户会话中断(如IP哈希、Cookie持久化等) |
异常检测的常见方法
主动健康检查
- TCP/UDP端口检查:定期尝试建立连接(如每秒1次),超时或失败则标记异常。
示例:Nginx配置tcp_health_check,探测目标端口是否响应。 - HTTP/HTTPS深度检查:发送GET请求并验证返回状态码(如200)或内容关键字。
示例:HAProxy配置http-check send meso,要求返回内容包含meso。 - 自定义脚本检查:通过外部脚本执行复杂逻辑(如数据库查询、业务接口调用)。
- TCP/UDP端口检查:定期尝试建立连接(如每秒1次),超时或失败则标记异常。
被动健康检查
- 应用层反馈:节点主动上报健康状态(如Consul的Health API)。
- 流量统计分析:根据失败率、延迟等指标动态调整权重(如Envoy的自适应负载均衡)。
混合模式
结合主动与被动检查,
- 主用TCP检查快速失败切换,备用HTTP检查防止误判。
- 流量统计作为辅助验证,避免因短暂网络抖动误剔除节点。
剔除异常的触发条件与策略
| 触发条件 | 典型阈值 | 说明 |
|---|---|---|
| 连续失败次数 | 3-5次(可配置) | 避免单次偶发错误导致误剔除 |
| 超时时间 | 2-10秒(依业务容忍度) | 长时间无响应判定为不可用 |
| 自定义检查失败 | 如脚本返回非0状态码 | 适用于业务逻辑相关的健康标准 |
策略分类:
- 立即剔除:适用于明确故障(如端口关闭、进程崩溃)。
- 软剔除(降级):临时降低权重而非完全移除,适用于性能下降但未完全失效的节点。
- 延迟剔除:多次检查失败后触发,避免网络抖动或瞬时过载导致误判。
主流负载均衡工具的实现对比
| 工具 | 健康检查方式 | 剔除策略 | 会话保持 |
|---|---|---|---|
| HAProxy | TCP/HTTP/自定义脚本 | 基于权重动态调整,支持备份服务器 | Cookie插入、源IP哈希 |
| Nginx | TCP/HTTP/自定义脚本 | 最大失败次数后标记不可用 | IP哈希、第三方模块(如Redis) |
| Keepalived | VRRP虚拟IP抢占 | 主备模式,优先级切换 | 无内置会话保持,需依赖外部 |
| Kubernetes CLB | HTTP/GRPC探针 | 结合Readiness/Liveness Probe | Service Load Balancer策略 |
典型场景与配置示例
场景1:Web服务集群健康检查
# Nginx upstream健康检查配置
upstream backend {
server 192.168.1.10 max_fails=3 fail_timeout=10s;
server 192.168.1.11 max_fails=3 fail_timeout=10s;
}
server {
location / {
proxy_pass http://backend;
}
}场景2:数据库主从节点检测
# Kubernetes Deployment探针配置
apiVersion: v1
spec:
containers:
name: db
livenessProbe:
exec:
command: ["mysqladmin", "ping", "-h", "localhost"]
initialDelaySeconds: 15
timeoutSeconds: 5常见问题与优化建议
误判正常节点为异常
- 原因:网络抖动、短暂过载、检查频率过高。
- 优化:
- 增加
fail_timeout参数(如Nginx的fail_timeout=30s)。 - 启用多路径检查(如同时检查HTTP和TCP)。
- 增加
节点恢复后流量分配不均
- 原因:负载均衡器未及时更新节点状态。
- 优化:
- 使用一致性哈希(如HAProxy的
balance source)。 - 配置健康检查恢复通知(如Keepalived的VRRP广告报文)。
- 使用一致性哈希(如HAProxy的
会话中断问题
- 解决方案:
- 启用持久化Cookie(如
proxy_set_header X-Forwarded-For)。 - 使用外部存储同步会话(如Redis缓存Session)。
- 启用持久化Cookie(如
- 解决方案:
FAQs
Q1:如何调整健康检查频率以平衡性能与准确性?
A:检查频率需根据业务容忍度与节点响应能力权衡,高频检查(如每秒1次)可快速发现故障,但可能增加负载;低频检查(如每30秒1次)减少资源消耗,但故障恢复延迟较长,建议对关键节点采用高频检查,非关键节点适当降低频率。
Q2:节点频繁上下线导致负载均衡震荡怎么办?
A:可启用“抑制抖动”机制,
- 设置最小下线持续时间(如
min_down_time=10s),避免短暂故障触发切换。 - 结合权重调整而非直接剔除,例如故障时将权重降至