上一篇
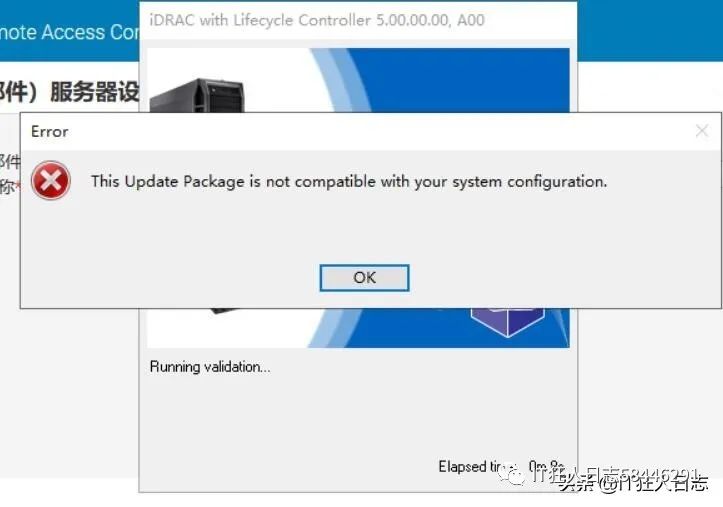
hit所选服务器目前不畅
hit所选服务器目前连接异常,部分功能受影响,技术团队紧急排查修复中,请稍后
问题现象描述与影响范围
当HIT(假设为某系统或平台)所选服务器出现运行不畅时,用户可能遇到以下典型问题:
- 响应延迟:操作卡顿,页面加载时间超过正常值(如超过5秒)。
- 服务中断:部分功能无法使用,如API接口返回错误、网页无法打开。
- 性能下降:系统处理速度骤降,并发请求处理能力减弱。
- 异常报错:出现502 Bad Gateway、504 Gateway Timeout等HTTP错误。
此类问题可能影响用户业务连续性,导致数据同步延迟、交易失败或用户体验下降,需优先排查并恢复。
服务器不畅的核心原因分析
| 问题类别 | 可能原因 | 典型症状 |
|---|---|---|
| 硬件资源瓶颈 | CPU过载(如100%占用) 内存耗尽(如swap交换区频繁触发) 磁盘I/O饱和(读写延迟>10ms) | 系统负载长期高于阈值,进程频繁卡顿 |
| 网络传输问题 | 带宽不足(如出口带宽被占满) 路由抖动(丢包率>1%) DDoS攻击(异常流量涌入) | ping延迟波动大,TCP重传率高 |
| 软件配置缺陷 | 数据库连接池耗尽 线程池溢出 缓存穿透(如Redis未命中) | 应用日志出现大量超时错误,JVM堆内存溢出 |
| 外部依赖故障 | 上游服务宕机(如第三方API不可用) 中间件崩溃(如Kafka队列阻塞) | 调用链追踪显示请求卡在某个节点 |
| 安全攻击风险 | CC攻击(高频无效请求) 反面扫描(暴力破解尝试) | 防火墙日志激增,服务器CPU突增后急剧下降 |
分场景排查与解决方案
硬件资源瓶颈
- 诊断方法:
- 使用
top或htop查看CPU、内存占用率。 - 通过
iostat检测磁盘I/O等待时间。 - 检查
/var/log/syslog中是否有OOM(内存不足)杀进程记录。
- 使用
- 解决措施:
- 紧急:重启消耗资源最高的进程(如
kill -9 PID)。 - 短期:扩容服务器(如增加SWAP分区或临时提升云主机规格)。
- 长期:优化代码(如异步处理非核心任务)、升级硬件(更换SSD硬盘)。
- 紧急:重启消耗资源最高的进程(如
网络传输问题
- 诊断方法:
ping目标IP测试基础延迟。mtr或traceroute定位丢包节点。- 检查防火墙规则(
iptables -L)是否误拦截合法请求。
- 解决措施:
- 启用CDN分流静态资源(如CSS/JS文件)。
- 调整负载均衡策略(如从轮询改为IP哈希)。
- 联系ISP提升带宽或更换BGP多线网络。
软件配置缺陷
- 诊断方法:
- 查看应用日志(如
/var/log/nginx/error.log)中的错误堆栈。 - 使用
jstack生成Java线程快照,分析死锁或热点代码。 - 检查数据库慢查询日志(如MySQL的
slow_query.log)。
- 查看应用日志(如
- 解决措施:
- 调整数据库连接池大小(如从100增至200)。
- 优化SQL语句(添加索引、避免全表扫描)。
- 启用微服务限流(如Nginx的
limit_req模块)。
外部依赖故障
- 诊断方法:
- 使用
curl或Postman测试上下游服务接口响应时间。 - 通过Zipkin/SkyWalking等APM工具追踪调用链。
- 检查消息队列积压情况(如RabbitMQ的
/queues管理界面)。
- 使用
- 解决措施:
- 切换备用服务节点(如DNS解析切换)。
- 清理消息队列堆积(如手动ACK未处理消息)。
- 临时关闭非核心功能以降低负载。
安全攻击风险
- 诊断方法:
- 分析访问日志(如
access.log)中的异常IP(如单IP每秒请求>100次)。 - 使用
netstat -ntu查看SYN_RECEIVED连接数是否异常。 - 检查防火墙规则是否拦截可疑端口(如高危的3389/445端口)。
- 分析访问日志(如
- 解决措施:
- 启用Web应用防火墙(WAF)过滤反面请求。
- 配置IP黑名单(如
iptables -A INPUT -s x.x.x.x -j DROP)。 - 接入DDoS防护服务(如阿里云的Anti-DDoS)。
预防性维护建议
监控体系:
- 部署Zabbix/Prometheus监控硬件指标(CPU/MEM/DISK/NET)。
- 使用ELK(Elasticsearch+Logstash+Kibana)集中管理日志。
- 设置自动化告警(如邮件/短信/微信通知)。
容量规划:
- 根据历史数据预测峰值负载(如双十一前扩容30%)。
- 定期压测(如JMeter模拟1000并发用户)。
- 采用弹性伸缩(如Kubernetes的HPA自动扩缩容)。
灾备方案:
- 数据级:每日增量备份+每周全量备份(如MySQL的binlog同步)。
- 服务级:搭建主从架构或双活数据中心。
- 演练切换:每季度模拟故障切换,验证RTO/RPO达标。
相关FAQs
Q1:如何快速判断服务器是否完全宕机?
- A1:
- 使用
ping命令测试基础连通性。 - 尝试
telnet目标端口(如telnet server_ip 80)。 - 若均无响应,可能为网络中断或服务器彻底死机,需立即重启。
- 使用
Q2:如何减少未来服务器不畅的概率?
- A2:
- 代码优化:禁用不必要的服务(如关闭FTP)、压缩传输数据(如GZIP)。
- 架构升级:拆分单体应用为微服务,避免单点故障。
- 流程规范:禁止未经测试的代码