
上一篇
hdfs读写api
HDFS读写API通过FileSystem类实现,写操作需获取输出流写入数据,读操作通过输入流按块读取,支持追加和完整覆盖,遵循一次写入多次读取模型,依赖分布式存储架构
HDFS(Hadoop Distributed File System)作为Hadoop生态系统的核心存储组件,提供了高容错、可扩展的分布式文件存储能力,其读写API是开发者与HDFS交互的核心接口,支持通过编程方式实现文件的上传、下载、删除等操作,本文将详细解析HDFS读写API的核心功能、使用方法及关键注意事项。
HDFS读写API核心类与接口
HDFS的Java API基于Hadoop的org.apache.hadoop.fs包,核心类包括:
| 类名 | 功能描述 |
|——|———-|
| FileSystem | 抽象文件系统接口,定义通用操作(如打开、删除文件) |
| DistributedFileSystem | HDFS特化实现类,提供HDFS专有功能 |
| Path | 表示HDFS中的文件路径 |
| FSDataInputStream | 用于读取HDFS文件的输入流 |
| FSDataOutputStream | 用于写入HDFS文件的输出流 |
| FileStatus | 存储文件元数据(如大小、权限、块信息) |
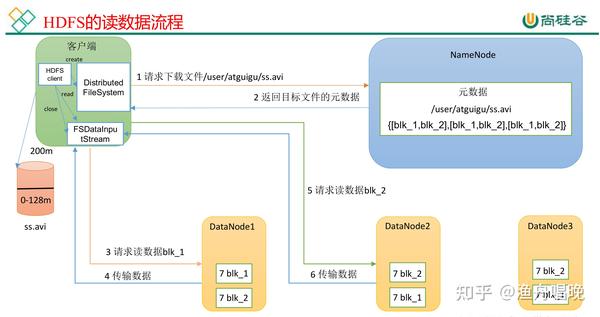
HDFS读操作API详解
获取FileSystem实例
Configuration conf = new Configuration();
// 可选:设置HDFS的NameNode地址
conf.set("fs.defaultFS", "hdfs://namenode:8020");
FileSystem fs = FileSystem.get(conf); // 自动加载配置文件说明:FileSystem.get()方法会读取core-site.xml中的配置,若未显式指定则默认连接fs.defaultFS。
打开文件并读取数据
Path filePath = new Path("/user/data/input.txt");
FSDataInputStream inputStream = fs.open(filePath);
try {
byte[] buffer = new byte[4096]; // 4KB缓冲区
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) > 0) {
// 处理读取到的数据(如转换为字符串)
String data = new String(buffer, 0, bytesRead);
System.out.print(data);
}
} finally {
inputStream.close(); // 必须关闭流以释放资源
}关键点:
fs.open()返回的FSDataInputStream支持随机访问(如seek()方法)。- 建议使用缓冲区(如4096字节)提高读取效率。
- 需处理
IOException,例如文件不存在或网络中断。
获取文件元数据
FileStatus fileStatus = fs.getFileStatus(filePath); long length = fileStatus.getLen(); // 文件长度(字节) short replication = fileStatus.getReplication(); // 副本数 String owner = fileStatus.getOwner(); // 文件所有者
扩展:可通过fileStatus.isDirectory()判断路径是否为目录。
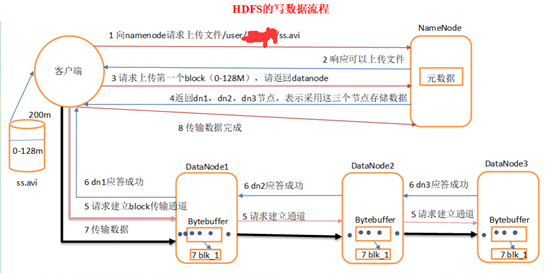
HDFS写操作API详解
创建文件并写入数据
Path outputPath = new Path("/user/data/output.txt");
// 创建输出流(会自动覆盖同名文件)
FSDataOutputStream outputStream = fs.create(outputPath, true);
try {
outputStream.writeBytes("Hello HDFS!
"); // 写入字符串
outputStream.write(123456789L); // 写入长整型(自动转为字节数组)
} finally {
outputStream.close(); // 关闭流以完成写入
}关键参数:
fs.create(Path, boolean):第二个参数表示是否允许覆盖已存在文件。- 块大小:默认128MB,可通过
conf.set("dfs.blocksize", "64m")调整。 - 副本因子:默认3,可通过
conf.set("dfs.replication", "2")修改。
追加写入(Hadoop 3.x+)
Path appendPath = new Path("/user/data/append.txt");
FSDataOutputStream appendStream = fs.append(appendPath);
try {
appendStream.writeBytes("Appending new data...
");
} finally {
appendStream.close();
}注意:追加写入仅支持已存在的文件,且要求HDFS集群启用hdfs.support.append(默认开启)。
高级功能与最佳实践
权限管理
HDFS支持基于Unix风格的权限模型,可通过API设置:
fs.setOwner(filePath, "userA", "groupA"); // 设置所有者和组
fs.setPermission(filePath, new FsPermission("755")); // 设置权限(八进制)验证权限:调用fs.getFileStatus()后检查FileStatus中的owner、group和permission字段。
性能优化
| 优化项 | 说明 |
|---|---|
| 缓冲区调优 | 增大FSDataInputStream/OutputStream的缓冲区(如64KB)以减少IO次数。 |
| 并行上传 | 对大文件分块后并行上传,利用HDFS多副本特性加速写入。 |
| 压缩传输 | 启用dfs.compress.type(如bzip2)减少网络传输数据量。 |
异常处理
常见异常及应对策略:
| 异常类型 | 场景 | 解决方案 |
|———-|——|———-|
| FileNotFoundException | 文件不存在 | 提前调用fs.exists()检查路径。 |
| AccessControlException | 权限不足 | 调整文件权限或切换用户(如UserGroupInformation.setLoginUser())。 |
| UnsupportedFileSystemException | 协议不匹配(如尝试用S3 API操作HDFS) | 确认fs.defaultFS配置正确。 |
配置参数与调试
关键配置项
| 参数 | 默认值 | 作用 |
|---|---|---|
dfs.replication | 3 | 数据块副本数 |
dfs.blocksize | 134217728(128MB) | 单个数据块大小 |
dfs.client.block.write.locations | 1 | 客户端写入时选择DataNode的策略(如3表示优先选择3个节点) |
调试工具
- Web UI:通过NameNode的50070端口查看文件系统状态。
- 日志分析:检查DataNode和NameNode日志(通常位于
$HADOOP_HOME/logs/)。 - API级调试:启用
fs.hdfs.impl.disable.cache可强制刷新缓存,观察实时状态。
FAQs
Q1:如何设置HDFS文件的块大小?
A:在创建文件前,通过Configuration对象设置dfs.blocksize参数。
Configuration conf = new Configuration();
conf.set("dfs.blocksize", "64m"); // 设置为64MB
FileSystem fs = FileSystem.get(conf);新创建的文件将使用该块大小,但已存在文件的块大小无法更改。
Q2:写入大文件时如何监控进度?
A:可通过自定义Progressable接口实现进度监控。
Progressable progress = new Progressable() {
@Override
public void progress(long bytes) {
System.out.println("Written " + bytes + " bytes");
}
};
FSDataOutputStream stream = fs.create(path, progress); // 传入进度监听器此方法需Hadoop 3.x
相关文章
爬虫数据存储hdfs_HDFS数据
DFS挂载文件存储HDFS

为何对象存储不适用于随机读写操作?HDFS应用开发中应如何应对?
SVN服务器更新:取消FSFS文件系统 (svn服务器取消fsfs)
一个关于MySQL数据库中LIMIT和OFFSET用法的疑问句标题可以这样写,,MySQL查询优化,LIMIT 2、LIMIT 2,3与LIMIT 2 OFFSET 3有何区别?,清晰地表达了文章的核心主题,即探讨MySQL中LIMIT和OFFSET的不同用法及其对查询结果的影响。同时,它遵循了SEO原则,包含了关键词MySQL、LIMIT和OFFSET,有助于搜索引擎更好地理解和索引文章内容。此外,通过使用疑问句形式,标题还吸引了读者的注意力,激发了他们点击阅读的兴趣。
关于HDFS API的疑问,如何有效使用其功能和优化性能?
hdfs设置权限api
如何优化MapReduce作业中Map输出到HDFS的性能?








