上一篇
hadoop分布式存储方案
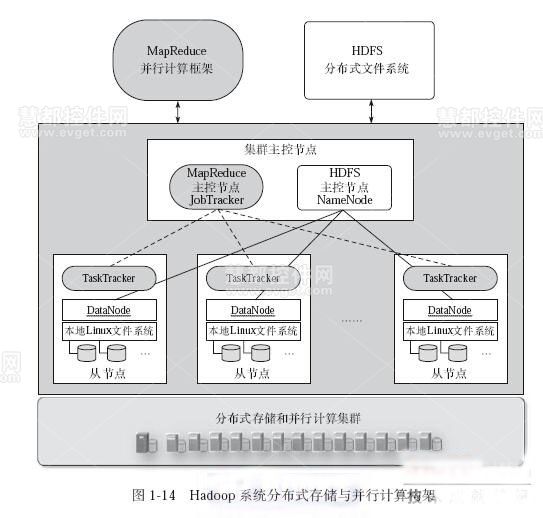
Hadoop采用HDFS分布式存储,将数据分块,以主从架构管理,通过副本机制保证冗余,实现高可靠与可
Hadoop分布式存储方案是一种基于分布式文件系统(HDFS)的大数据存储架构,通过多节点协同工作实现海量数据的可靠存储与高效访问,其核心设计目标为高容错性、可扩展性和低成本硬件适配能力,以下是该方案的详细解析:
核心组件与架构
| 组件 | 功能定位 | 部署特点 |
|---|---|---|
| NameNode | 元数据管理(文件目录结构、块位置、权限) | 单点或HA集群 |
| DataNode | 实际数据存储与读写服务 | 多节点分布式部署 |
| SecondaryNameNode | 辅助元数据checkpoint(非实时同步) | 独立节点(已逐步淘汰) |
| HDFS Client | 用户接口,处理文件切分、与NameNode/DataNode通信 | 客户端程序 |
| Block | 数据存储单元(默认128MB,可配置) | 多副本分布在不同机架 |
数据存储流程:
- 文件切分:客户端将大文件拆分为固定大小的数据块(Block)
- 元数据记录:NameNode记录文件到数据块的映射关系及块存储位置
- 三副本存储:每个数据块默认存储3个副本,分布在不同机架的DataNode上
- 心跳检测:DataNode每3秒向NameNode发送心跳,报告存储状态和块完整性
高可用性设计方案
Hadoop 2.x后引入HA(High Availability)模式解决NameNode单点故障问题:

- 双NameNode架构:
- Active NameNode:处理客户端请求
- Standby NameNode:实时同步元数据(通过JournalNode集群)
- 故障切换:ZooKeeper监控Active节点状态,自动切换Standby为Active
- 数据一致性:采用Quorum Journal Manager(QJM)保证元数据写入一致性
| 传统单NameNode | HA模式 |
|---|---|
| 单点故障风险 | 自动故障转移(<2秒中断) |
| 元数据单副本 | 多JournalNode共享写入日志 |
| 维护需停机 | 滚动升级(不影响业务) |
数据一致性保障机制
写操作传播:
- 客户端写入时,NameNode先记录元数据变更
- 数据块需被多数(>50%)DataNode确认后才返回成功
- 通过Pipeline机制优化写入性能(顺序写入多个副本)
副本同步策略:
- 主副本负责协调次级副本同步
- 支持两种模式:
- Write Once Read Many:写入时仅更新主副本,读取时从最近副本获取
- Eager Sync:写入时同步更新所有副本(牺牲性能换强一致性)
数据修复机制:
- DataNode检测到坏块时通知NameNode
- 自动从其他副本重建损坏数据块
- 支持离线修复(使用hdfs fsck命令)
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 存储效率 | 启用HDFS Erasure Coding(EC)替代三副本,降低50%存储成本 |
| 访问延迟 | 短路径优化:客户端直连DataNode读取本地副本 |
| 吞吐量提升 | 数据本地性调度:计算任务优先分配到存储数据的节点 |
| 小文件问题 | 使用Hadoop Archive(HAR)合并小文件,或集成HBase管理小文件 |
典型应用场景
- 冷数据存储:历史日志、归档数据等低频访问场景
- 批处理计算:MapReduce任务直接访问HDFS数据
- 实时分析基座:与Kafka、HBase结合构建混合存储架构
- 云存储替代方案:企业私有云环境下的低成本对象存储(通过Compatible API)
与其他存储方案对比
| 特性 | HDFS | Ceph/GlusterFS | AWS S3 |
|---|---|---|---|
| 扩展性 | 横向线性扩展 | 动态扩展 | 无限扩展 |
| 数据一致性 | 最终一致性 | 强一致性可选 | 读后写一致性 |
| 硬件要求 | 廉价PC服务器 | 需共享存储设备 | 虚拟化资源 |
| 延迟表现 | 高延迟(ms级) | 低延迟(μs级) | 低延迟 |
| 适用场景 | 大批量数据处理 | 混合工作负载 | 互联网应用 |
FAQs
Q1:HDFS如何处理小文件存储性能差的问题?
A1:可通过以下方案优化:
- 使用SequenceFile/Avro合并小文件
- 启用Hadoop Archive(HAR)打包存储
- 集成HBase实现键值对存储
- 调整HDFS块大小(如1MB)但需权衡内存消耗
Q2:NameNode元数据存储容量上限如何突破?
A2:在Hadoop 3.x中,通过以下技术扩展元数据容量:
- 支持亿级文件存储(改进内存管理算法)
- 使用Netty重构RPC通信提升并发能力
- 部署联邦HDFS(多个NameNode管理不同命名空间)
- 采用Era