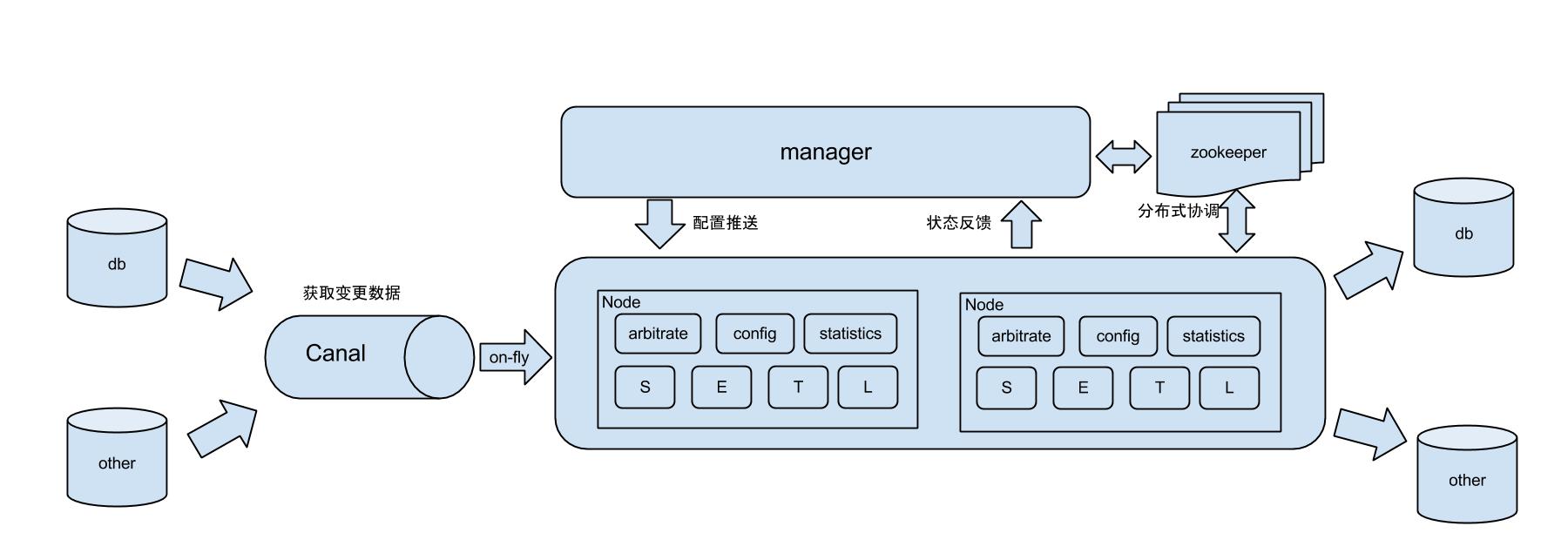
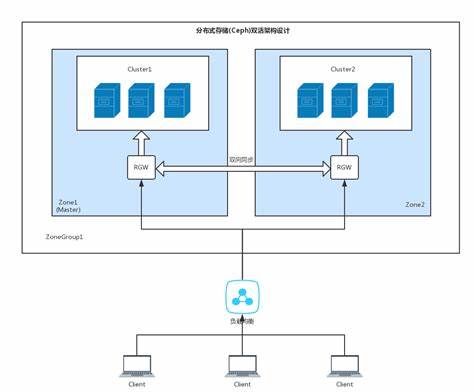
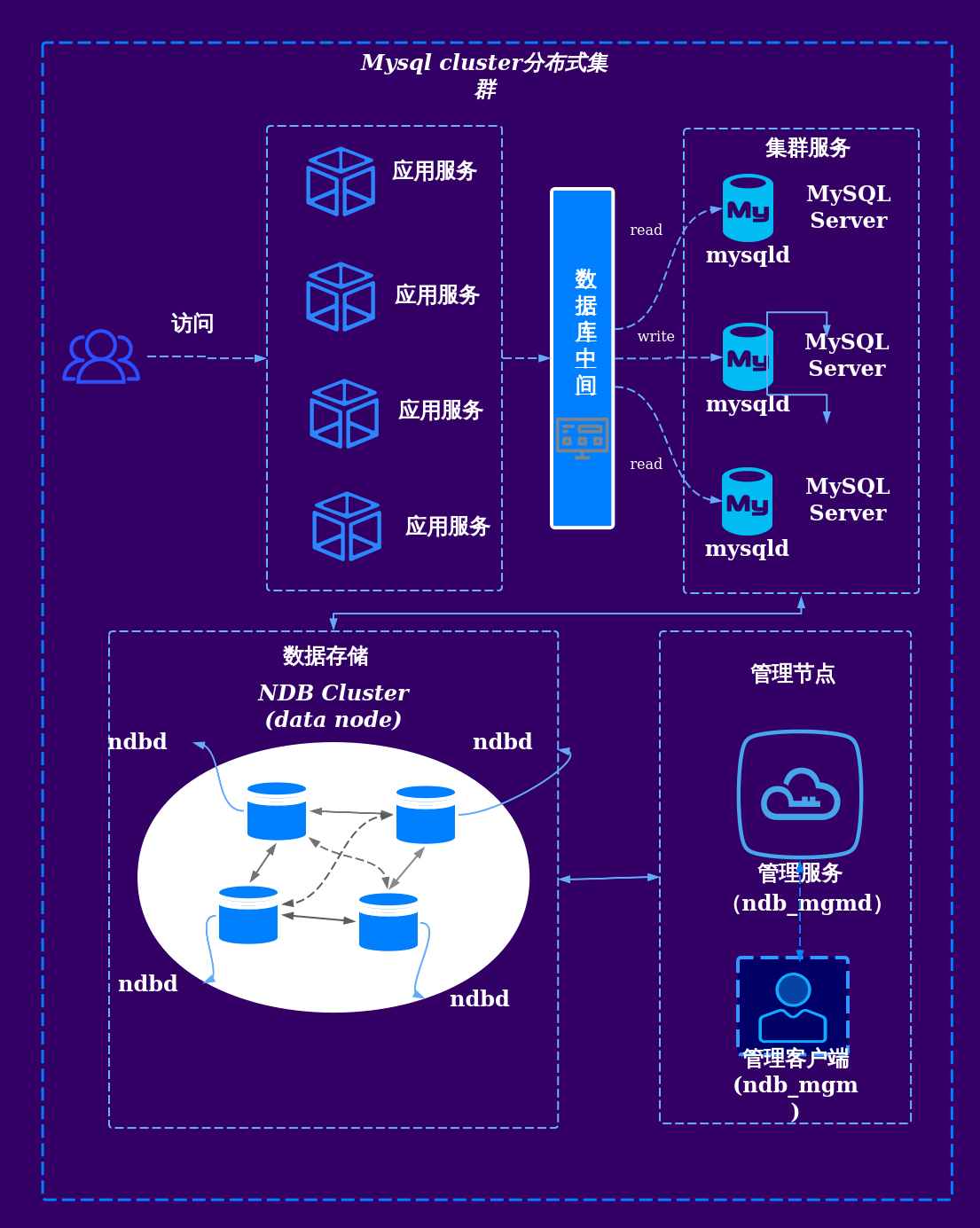
上一篇
分布式数据库系统查询
分布式数据库查询需协调多节点,解析优化后执行,考虑数据分片与
分布式数据库系统查询详解
分布式数据库系统(Distributed Database System, DDS)通过将数据分散存储在多个物理节点上,结合分布式计算框架实现高效查询,其核心目标是在保证数据一致性、可用性和性能的前提下,完成跨节点的数据检索与处理,以下是分布式数据库查询的核心原理、执行流程、优化策略及典型挑战的详细分析。
分布式数据库查询的基本原理
分布式数据库的查询与传统集中式数据库的最大区别在于数据分布性和计算协同性,查询需解决以下关键问题:
- 数据分片(Sharding):数据按规则(如哈希、范围、列表等)划分到不同节点。
- 节点协调:查询任务需分解为子任务,由协调节点(如主节点或调度器)分配至各分片节点。
- 结果合并:各节点返回部分结果后,需进行聚合、排序、去重等操作以生成最终结果。
表1:集中式与分布式查询的对比
| 特性 | 集中式数据库 | 分布式数据库 |
|——————-|—————————-|——————————|
| 数据存储 | 单一节点 | 多节点分片存储 |
| 查询执行 | 单进程顺序执行 | 多节点并行执行 |
| 网络依赖 | 无 | 依赖节点间通信 |
| 容错性 | 单点故障风险高 | 通过冗余设计提升容错性 |
| 延迟来源 | 磁盘I/O、CPU计算 | 网络传输、节点负载不均 |
分布式查询的执行流程
以SQL查询为例,分布式数据库的查询执行通常分为以下阶段:
查询解析与优化

- 语法解析:将SQL语句转换为抽象语法树(AST)。
- 逻辑优化:应用代数法则(如谓词下推、连接重排序)简化执行计划。
- 物理优化:根据数据分布信息(如分片键、节点负载)生成分布式执行计划。
任务分发与执行
- 协调节点:负责解析全局查询计划,将其拆分为针对各分片的子查询。
- 分片执行:各节点独立处理本地数据分片,执行过滤、聚合等操作。
- 中间结果传输:通过RPC(如gRPC)或消息队列(如Kafka)传递中间结果。
结果合并与返回
- 并行聚合:对分布式结果进行排序、去重、分组等操作。
- 全局一致性:通过分布式事务协议(如两阶段提交)确保结果一致性。
图1:分布式查询执行流程示意图
用户 → 协调节点 → 分片节点1/2/3 → 中间结果 → 协调节点 → 最终结果 分布式查询的优化策略
为降低查询延迟并提升吞吐量,分布式数据库采用多种优化技术:
| 优化策略 | 目标 | 实现方式 |
|---|---|---|
| 数据局部性优化 | 减少跨节点数据传输 | 通过分片键设计(如将高频查询字段作为分片键)使查询仅访问相关分片。 |
| 并行度调整 | 提升多节点计算效率 | 动态分配任务粒度(如细粒度分片或粗粒度分片),避免节点成为瓶颈。 |
| 缓存机制 | 加速重复查询 | 在协调节点或分片节点部署查询结果缓存(如Redis),直接返回缓存数据。 |
| 代价模型优化 | 选择最优执行计划 | 基于节点负载、网络带宽、数据分布统计信息,动态生成低成本执行计划。 |
分布式查询的典型挑战与解决方案
挑战1:网络延迟与带宽瓶颈
- 问题:跨节点通信依赖网络,高并发查询可能导致延迟激增。
- 解决方案:
- 数据预分发:将高频访问数据提前复制到就近节点(如CDN思想)。
- 压缩传输:对中间结果进行列式存储压缩(如Protobuf、Snappy)。
挑战2:数据倾斜导致负载不均
- 问题:某些分片数据量过大,导致部分节点成为瓶颈。
- 解决方案:
- 动态分片调整:根据查询频率动态迁移热点数据。
- 哈希分片+范围分片混合:结合两者优势平衡负载。
挑战3:全局事务一致性
- 问题:分布式环境下难以保证ACID特性(如网络分区时)。
- 解决方案:
- BASE理论:通过最终一致性(Eventual Consistency)放宽强一致性要求。
- Paxos/Raft协议:用于元数据管理,确保分片键与事务日志的一致性。
实际应用场景
分布式数据库查询广泛应用于以下场景:
- 互联网服务:如电商订单查询(分片键为
user_id)、社交媒体Feed流(按时间范围分片)。 - 大数据分析:通过MPP(Massively Parallel Processing)架构加速复杂查询。
- 物联网(IoT):设备数据按地理位置分片,支持低延迟区域查询。
FAQs
Q1:分布式数据库查询与单机查询的核心区别是什么?
A1:核心区别在于数据分布性与任务协同性,分布式查询需解决跨节点数据定位、中间结果传输、负载均衡等问题,而单机查询仅需优化本地磁盘与内存访问,分布式系统需额外处理网络延迟和节点故障带来的挑战。
Q2:如何缓解分布式查询中的数据倾斜问题?
A2:可通过以下方法缓解:
- 改进分片策略:例如对热点数据采用哈希分片而非范围分片,或引入虚拟分片(Virtual Sharding)分散负载。
- 动态负载均衡:实时监控节点负载,将查询任务路由至空闲节点。
- 数据预处理:对倾斜数据进行预聚合或冗余存储