
上一篇
GPU服务器无法登录如何紧急解决与快速修复?
GPU服务器无法登录时,首先检查网络连接、防火墙及SSH端口状态,确认IP和权限无误;若使用密钥登录,需验证密钥文件权限,其次检查服务器负载,GPU资源是否过载导致响应停滞,尝试重启服务或联系管理员排查系统日志及硬件故障。
GPU服务器登录失败?详细排查指南助你快速恢复访问
当GPU服务器无法登录时,可能由网络配置、权限问题或系统故障等多种原因导致,本文提供一套系统化排查流程,涵盖常见原因与解决方案,帮助用户高效定位问题。
检查基础网络连接
确认IP与端口状态
- 执行
ping <服务器IP>检查网络是否可达,若超时,需排查本地网络或联系机房/云服务商。 - 使用
telnet <IP> <端口>或nc -zv <IP> <端口>测试SSH端口(默认22)是否开放,若端口不通,可能被防火墙拦截。telnet 192.168.1.100 22 # 示例:测试22端口连通性
- 执行
验证云服务商控制台状态
登录云平台(如AWS、阿里云)查看实例运行状态,确认未因欠费或异常操作被暂停。
SSH服务与配置排查
检查SSH服务是否运行

- 若服务器已连接,通过控制台执行
systemctl status sshd(Linux)查看SSH服务状态,若未启动,运行systemctl start sshd。 - 查看SSH配置文件
/etc/ssh/sshd_config,确认PermitRootLogin是否允许root登录,PasswordAuthentication是否开启密码验证。
- 若服务器已连接,通过控制台执行
排查密钥登录问题
- 权限错误:确保本地私钥文件权限为
600(命令:chmod 600 ~/.ssh/id_rsa)。 - 密钥未绑定:云服务器需在控制台绑定密钥对,重启实例后生效。
- 权限错误:确保本地私钥文件权限为
系统资源与安全策略
服务器负载过高
- 通过云控制台重启进入救援模式,使用
top或htop查看CPU/内存使用率,若资源耗尽,需结束异常进程或升级配置。
- 通过云控制台重启进入救援模式,使用
防火墙与安全组限制
- 本地防火墙:检查
iptables或firewalld是否放行SSH端口。 - 云平台安全组:确保入方向规则允许来自当前IP的SSH访问(如临时调整可设置为
0.0.0/0测试)。
- 本地防火墙:检查
IP黑名单与登录限制
- 检查
/etc/hosts.deny是否误封IP;查看/var/log/auth.log或/var/log/secure日志,确认是否因多次失败登录触发fail2ban封禁。
- 检查
账户与文件系统问题
用户权限与密码错误
- 通过控制台重置密码(适用于云服务器);检查
/etc/passwd和/etc/shadow文件是否损坏。 - 确认账户未被锁定:执行
passwd -S <用户名>查看账户状态。
- 通过控制台重置密码(适用于云服务器);检查
磁盘空间不足
- 若根分区满载,SSH服务可能无法响应,进入救援模式,使用
df -h查看磁盘使用,清理日志(/var/log)或临时文件。
- 若根分区满载,SSH服务可能无法响应,进入救援模式,使用
硬件与系统级故障
GPU驱动冲突
部分GPU驱动异常可能导致系统卡死,通过控制台重启服务器,进入单用户模式卸载驱动后重装。
系统崩溃或内核错误
- 查看内核日志
dmesg或journalctl -k,确认是否存在硬件报错(如CPU、内存故障),联系运维团队更换硬件。
- 查看内核日志
高级故障排除工具
- SSH调试模式:添加
-v参数输出详细连接日志(如ssh -v user@ip),根据错误提示定位问题。 - tcpdump抓包分析:在服务器端执行
tcpdump port 22 -i eth0 -w ssh.pcap,分析SSH握手过程是否异常。
预防与最佳实践
- 启用双因素认证(2FA)提升账户安全性。
- 定期备份
sshd_config等关键配置文件。 - 使用监控工具(如Prometheus)实时检测服务器资源与服务状态。
引用来源
- Linux系统日志分析 – Red Hat Documentation
- SSH故障排查指南 – OpenSSH官方手册
- 云服务器安全组配置 – 阿里云帮助中心
提示:若问题仍未解决,建议联系服务器提供商或运维团队,提供完整的错误日志以加速处理。
相关文章

腾讯云gpu服务器,腾讯云GPU服务器(腾讯云gpu服务器,腾讯云gpu服务器区别)
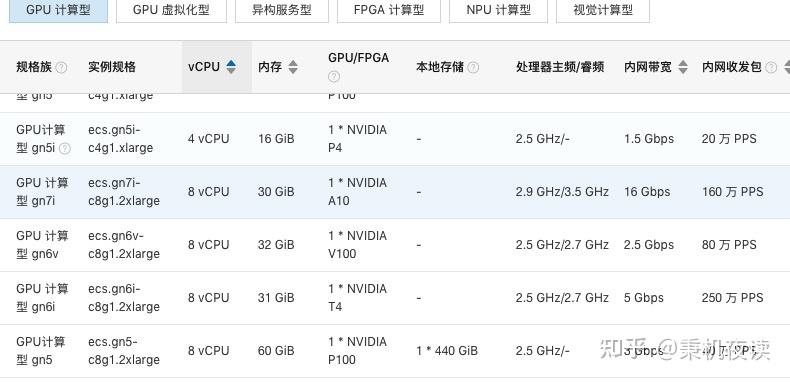
腾讯云gpu服务器(阿里云 GPU服务器)(腾讯云gpu服务器价格)

gpu服务器租用,阿里云gpu服务器租用2022年更新(阿里云gpu服务器租用价格表)
gpu服务器怎么用,GPU服务器搭建2022年更新(gpu服务器怎么使用)

Contabo:GPU服务器(Nvidia Tesla T4 16 GB)(conda gpu)(gpu服务器使用教程)
GPU服务器到期如何紧急导出数据?
GPU服务器密码忘记如何紧急处理?

【问题解决】服务器demo登录异常,无法登录如何解决? (不能登录到服务器demo)
笔记本电脑文件突然无法打开如何紧急恢复?








