上一篇
分布式数据库缓存系统
分布式数据库通过数据分片、多副本机制实现水平扩展,结合缓存系统(如Redis)加速热点数据访问,降低主库负载,提升高并发场景下的数据读写效率与系统可用
分布式数据库缓存系统详解
核心概念与价值
分布式数据库缓存系统是一种通过在分布式数据库与应用层之间引入高速存储层(缓存层),以提升数据访问效率、降低后端数据库负载的技术架构,其核心目标是解决传统集中式缓存在高并发、大规模数据场景下的瓶颈问题,同时保障数据的一致性与可用性。
核心价值:
- 性能加速:通过缓存热点数据,减少数据库直接读写次数,降低延迟。
- 横向扩展:支持动态扩容,适应业务流量的弹性变化。
- 高可用性:通过多副本、故障转移机制,避免单点故障。
- 成本优化:减轻数据库压力,降低硬件资源消耗。
系统架构设计
分布式数据库缓存系统的架构通常分为三层:
| 层级 | 功能描述 | 关键技术 |
|---|---|---|
| 客户端层 | 负责请求分发与路由,支持负载均衡、连接池管理。 | 一致性哈希、服务发现(如DNS) |
| 缓存层 | 存储高频访问数据,支持读写分离与多级缓存(如L1/L2)。 | Redis Cluster、Memcached集群 |
| 存储层 | 分布式数据库(如Cassandra、TiDB)负责持久化存储,同步缓存层的数据更新。 | 主从复制、Paxos/Raft协议 |
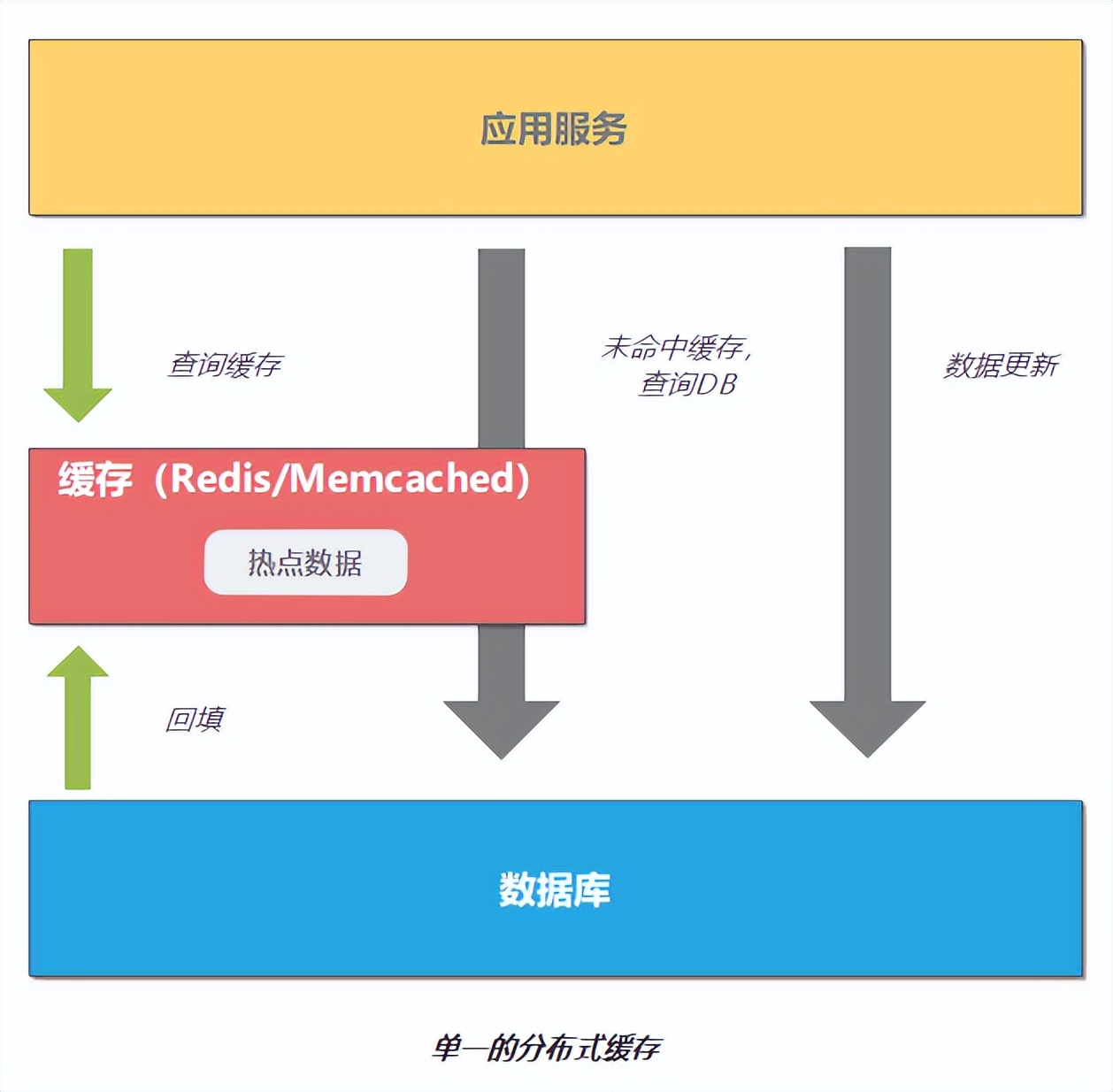
数据流动路径:
- 客户端优先查询缓存层,命中则直接返回。
- 未命中时,缓存层从存储层拉取数据并回填缓存。
- 数据变更时,存储层通过异步/同步机制更新缓存。
关键技术解析
一致性哈希
- 作用:解决分布式缓存中数据倾斜问题,均匀分配数据到不同缓存节点。
- 实现:将缓存节点与数据键映射到哈希环上,顺时针查找最近节点。
- 优化:虚拟节点技术(如每个物理节点拆分为100个虚拟节点)提升负载均衡效果。
数据同步机制
- 强一致性:通过Redis的主从复制+哨兵模式,确保主节点故障时自动切换。
- 最终一致性:采用消息队列(如Kafka)异步同步数据库与缓存的更新操作。
冷热数据分层
- 策略:基于访问频率(如LRU算法)动态划分热数据(存于高速缓存)与冷数据(落盘或降级至二级缓存)。
- 效果:提升缓存命中率,减少无效数据占用。
挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 缓存与数据库一致性 | 采用“读写穿透”策略(如Redisson客户端的Just-In-Time加载)或双写模式。 |
| 缓存雪崩 | 设置热点数据永不过期,结合熔断机制(如Hystrix)防止集中失效。 |
| 缓存击穿 | 使用互斥锁(如Redis的SETNX)保护单一热点Key的重建过程。 |
| 节点故障恢复 | 基于Raft协议实现缓存节点的自动选举与数据恢复。 |
性能优化策略
- 动态扩容:通过Hash槽迁移(如Redis Cluster的Resharding)实现缓存容量的线性扩展。
- 预热机制:在系统启动或峰值前,提前将热点数据加载到缓存层。
- 监控与调优:
- 指标:缓存命中率、延迟、内存使用率、节点负载均衡度。
- 工具:Prometheus+Grafana监控体系,结合自动化脚本(如Python)调整缓存参数。
典型应用场景
- 电商瞬秒:缓存商品库存与价格,抵御高并发冲击。
- 社交Feed流:缓存用户主页的热门内容,减少数据库查询压力。
- 游戏道具系统:通过缓存加速玩家道具数据的读取与更新。
案例分析:Redis Cluster的实践
- 架构:3主3从节点,主节点处理写操作,从节点提供读扩展。
- 问题:写操作集中在主节点,可能成为瓶颈。
- 优化:启用Redis Cluster的哈希槽分片,配合Codis代理实现跨主节点的负载均衡。
FAQs
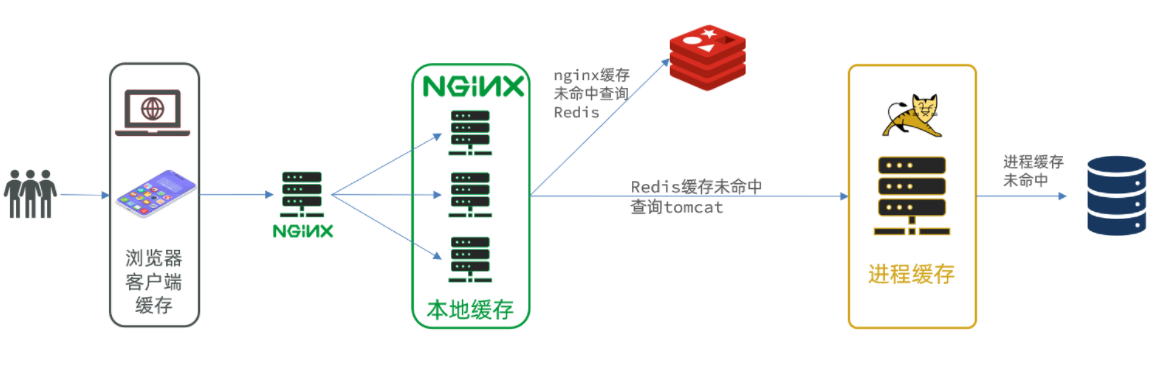
Q1:分布式缓存与本地缓存的区别是什么?
- 本地缓存:仅存在于单一应用进程内(如Guava Cache),生命周期与应用绑定,无法跨实例共享。
- 分布式缓存:部署在独立节点(如Redis集群),支持多应用实例共享数据,具备高可用与扩展性。
Q2:如何选择合适的缓存失效策略?
- LRU(最近最少使用):适合频繁访问的热点数据,如用户Session。
- LFU(最不常用):适用于数据访问频率差异大的场景,如排行榜缓存。
- TTL(固定过期):适用于时效性要求高的数据,如