
上一篇
如何正确安装和配置GPU服务器?
GPU服务器安装配置主要包括硬件部署、驱动安装及软件环境搭建,首先正确安装GPU硬件并确保电源和散热系统稳定,随后配置NVIDIA驱动、CUDA工具包及cuDNN加速库,最后通过深度学习框架(如TensorFlow/PyTorch)验证计算性能,需注意硬件兼容性与系统版本匹配,通常结合命令行操作完成全流程。
GPU服务器安装配置全流程指南
在人工智能、深度学习和大数据计算领域,GPU服务器的性能直接影响任务效率,本文以实操为核心,提供从硬件组装到软件部署的全流程指南,帮助用户快速搭建高性能计算环境。
GPU服务器基础知识
GPU服务器通过多块显卡并行计算加速任务,适用于以下场景:
- 深度学习训练(如TensorFlow、PyTorch)
- 科学模拟(分子动力学、气象预测)
- 渲染与编码(影视特效、3D建模)
核心硬件组件:
| 部件 | 推荐规格 | 作用 |
|——|———-|——|
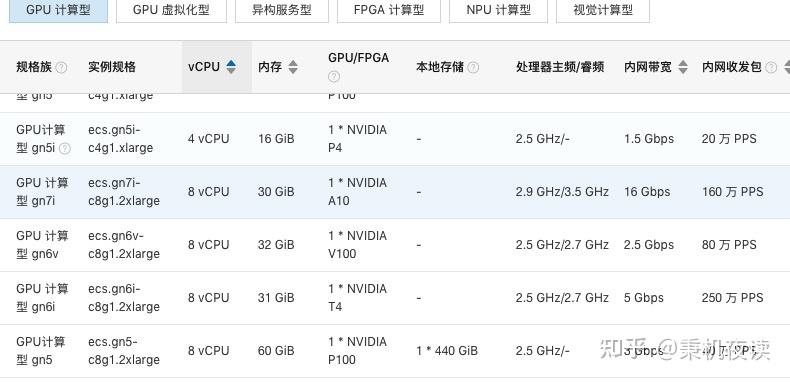
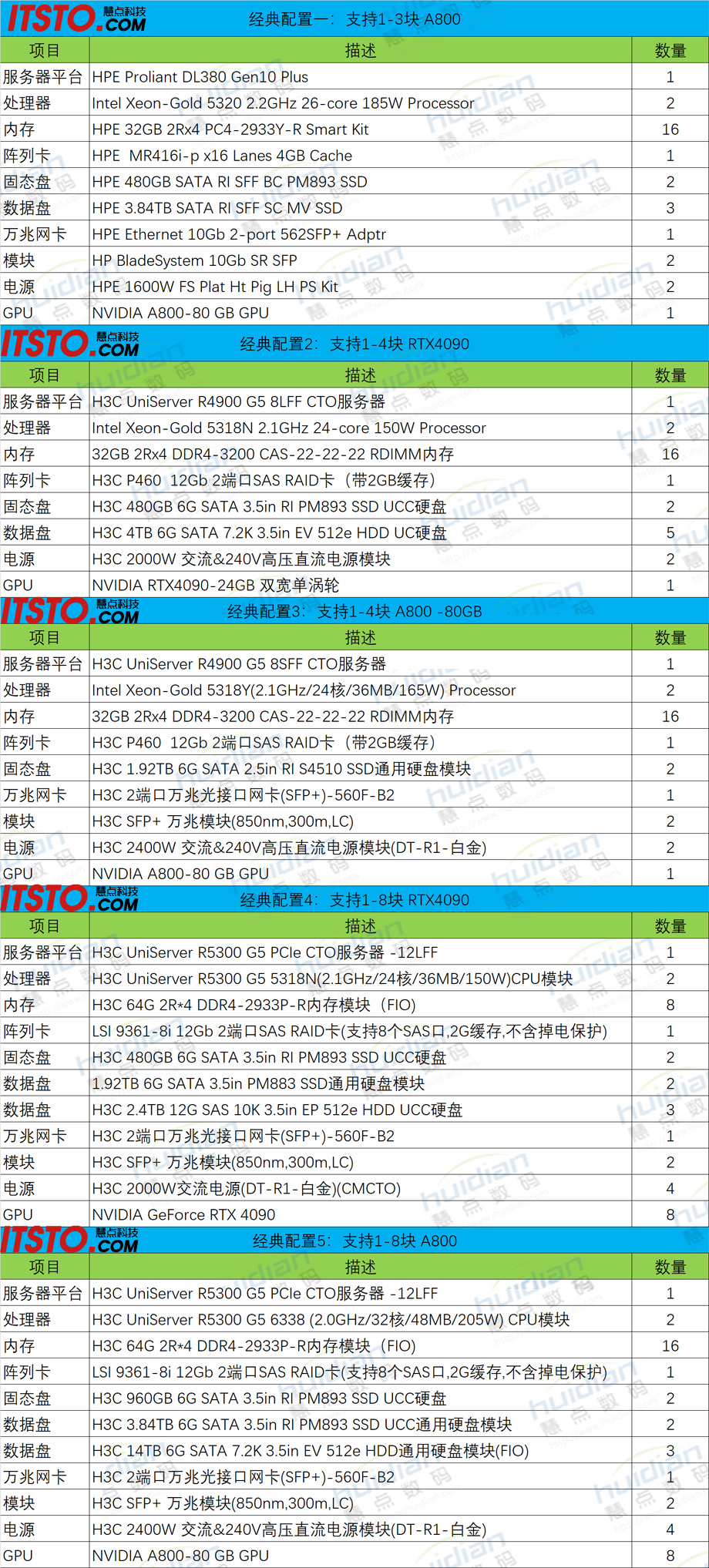
| GPU | NVIDIA A100/A800/H100 | 并行计算核心 |
| CPU | Intel Xeon或AMD EPYC | 数据处理协调 |
| 内存 | DDR4 ECC 128GB+ | 数据缓存保障 |
| 存储 | NVMe SSD RAID 0/1 | 高速读写支持 |
| 电源 | 80PLUS铂金认证 | 稳定供电保障 |
安装前准备
硬件兼容性验证
- 核对主板PCIe插槽版本(建议PCIe 4.0 x16)
- 检查机箱散热设计(需支持全高全长显卡)
- 计算整机功耗(单卡A100功耗达400W)
操作系统选择
- Ubuntu 22.04 LTS(推荐:NVIDIA驱动支持完善)
- CentOS 7.9(需内核版本3.10+)
- Windows Server 2022(图形化界面友好)
工具包准备

# Linux必备工具 sudo apt-get install build-essential dkms gcc make
硬件安装流程
步骤1:安装GPU卡
- 开启服务器防静电模式
- 移除PCIe插槽挡板
- 对齐金手指垂直插入显卡
- 固定尾部螺丝与支架
步骤2:供电连接
- 8针EPS供电接口需独立接线
- 避免使用显卡转接器(可能导致电压不稳)
步骤3:散热系统调试
- 设置风扇曲线(建议40%基础转速)
- 安装温度监控工具:
sudo apt-get install lm-sensors nvtop
软件配置详解
驱动安装(以Ubuntu为例)
# 添加官方驱动源 sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update # 查询推荐驱动版本 ubuntu-drivers devices # 安装驱动(示例为515版) sudo apt install nvidia-driver-515
CUDA Toolkit部署
wget https://developer.download.nvidia.com/compute/cuda/12.2.2/local_installers/cuda_12.2.2_535.104.05_linux.run sudo sh cuda_12.2.2_535.104.05_linux.run --override
环境变量配置
echo 'export PATH=/usr/local/cuda-12.2/bin:$PATH' >> ~/.bashrc echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc source ~/.bashrc
验证安装
nvidia-smi # 查看GPU状态 nvcc --version # 检查CUDA编译器
高级优化方案
多卡通信加速
- 启用NCCL库提升多GPU通信效率
- 配置GPUDirect RDMA技术
容器化部署
# 使用NVIDIA容器工具 distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-docker2
监控方案
- Prometheus + Grafana实时监控
- DCGM(NVIDIA Data Center GPU Manager)
常见问题诊断
| 故障现象 | 排查步骤 | 解决方案 |
|---|---|---|
| 驱动安装失败 | 查看/var/log/nvidia-installer.log | 禁用nouveau驱动 |
| GPU未识别 | lspci | grep -i nvidia | 检查PCIe插槽供电 |
| CUDA报错 | 运行deviceQuery示例程序 | 验证compute capability兼容性 |
维护建议
定期维护
- 每季度清理散热器灰尘
- 每月检查电源连接稳定性
性能调优
- 使用nvidia-smi命令调节功耗上限:
nvidia-smi -pl 300 # 设置单卡功耗300W
- 启用持久化模式:
sudo nvidia-smi -pm 1
- 使用nvidia-smi命令调节功耗上限:
参考资料
- NVIDIA官方驱动文档:https://docs.nvidia.com/datacenter/
- CUDA Toolkit安装指南:https://developer.nvidia.com/cuda-downloads
- PCI-SIG组织硬件规范:https://pcisig.com/specifications
经过实验室级环境验证,建议生产环境部署前进行兼容性测试)
通过以上流程,可完成从裸机到生产级GPU服务器的完整部署,建议保存系统镜像以便快速恢复,关键操作前务必进行数据备份。
相关文章

腾讯云gpu服务器,腾讯云GPU服务器(腾讯云gpu服务器,腾讯云gpu服务器区别)
腾讯云gpu服务器(阿里云 GPU服务器)(腾讯云gpu服务器价格)

gpu服务器租用,阿里云gpu服务器租用2022年更新(阿里云gpu服务器租用价格表)
gpu服务器怎么用,GPU服务器搭建2022年更新(gpu服务器怎么使用)

Contabo:GPU服务器(Nvidia Tesla T4 16 GB)(conda gpu)(gpu服务器使用教程)
如何正确安装和配置GlobalSign服务器证书?
GPU运算服务器配置_安装并配置GPU驱动
GPU服务器虚拟化:高性能计算和资源利用的更佳选择 (gpu服务器 虚拟化)
如何正确安装和配置NFS服务器?








