上一篇
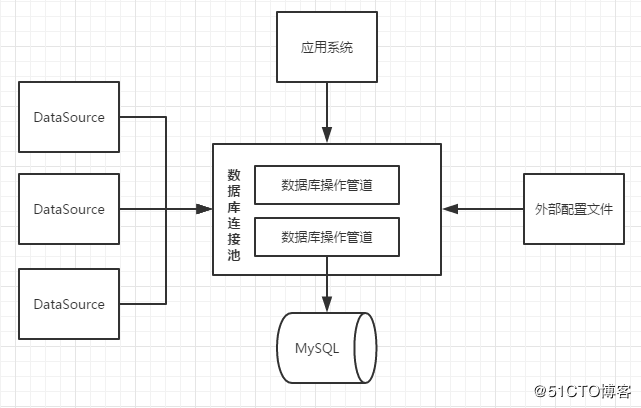
hive链接可视化MySQL
通过数据同步工具将Hive数据导入MySQL,再使用Tableau/Power BI等可视化工具直连MySQL库
Hive链接可视化MySQL的实现方案与操作指南
背景与需求分析
Hive是基于Hadoop的数据仓库工具,擅长处理海量离线数据,而MySQL作为关系型数据库,常用于在线业务系统,在实际场景中,企业可能需要将Hive中的分析结果同步至MySQL,并通过可视化工具(如Tableau、Power BI、Superset等)进行数据展示,本文将从数据导出、转换、导入及可视化连接等环节,详细阐述Hive与MySQL的整合流程。
核心流程与技术选型
| 步骤 | 技术工具 | 说明 |
|---|---|---|
| 数据导出 | Hive SQL、Sqoop | 从Hive提取数据 |
| 数据转换 | 脚本(Python/Shell) | 处理字段映射、类型转换 |
| 数据导入 | MySQL Load、Sqoop | 将数据写入MySQL |
| 可视化连接 | JDBC/ODBC驱动 | 通过可视化工具连接MySQL |
详细实现步骤
从Hive导出数据
Hive支持直接导出数据为CSV、ORC、Parquet等格式,以导出CSV为例:
-示例:导出Hive表数据为CSV INSERT OVERWRITE DIRECTORY '/user/hive/output/' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' SELECT FROM hive_table;
注意事项:
- 若表包含复杂数据类型(如Array、Struct),需先转换为基本类型。
- 分区表需指定分区范围,
WHERE pdate='2023-01-01'。
数据清洗与转换
Hive与MySQL的字段类型可能存在差异(如Hive的DOUBLE对应MySQL的DECIMAL),需通过脚本转换,以下为Python示例:
import pandas as pd
# 读取Hive导出的CSV文件
df = pd.read_csv('hive_output/data.csv')
# 类型转换(示例:将字符串日期转为MySQL的DATE类型)
df['date_field'] = pd.to_datetime(df['date_field']).dt.strftime('%Y-%m-%d')
# 保存为MySQL兼容的CSV
df.to_csv('mysql_input/data.csv', index=False)将数据导入MySQL
可使用LOAD DATA INFILE或Sqoop高效导入,以下是LOAD DATA示例:
-创建目标表
CREATE TABLE mysql_table (
id BIGINT,
name VARCHAR(50),
date_field DATE,
value DECIMAL(10,2)
) ENGINE=InnoDB;
-导入数据
LOAD DATA INFILE '/path/to/mysql_input/data.csv'
INTO TABLE mysql_table
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '
'
IGNORE 1 LINES;优化建议:
- 禁用MySQL索引:
ALTER TABLE mysql_table DISABLE KEYS;(导入前) - 启用索引:
ALTER TABLE mysql_table ENABLE KEYS;(导入后) - 分批次导入(如每次100万行)避免内存溢出。
可视化工具连接MySQL
以Tableau为例:
- 打开Tableau,选择“连接到数据”。
- 选择“MySQL数据库”,输入连接信息(主机、端口、用户名、密码)。
- 选择目标数据库和表(如
mysql_table)。 - 拖拽字段生成图表(如销售额趋势图、用户分布等)。
常见问题与解决方案
数据类型不匹配
| Hive类型 | MySQL类型推荐 | 解决方案 |
|---|---|---|
| STRING/VARCHAR | VARCHAR(n) | 限制长度(如VARCHAR(255)) |
| DOUBLE | DECIMAL(p,s) | 指定精度(如DECIMAL(10,2)) |
| BINARY | BLOB/VARBINARY | 存储二进制数据 |
导入性能优化
- 调整批量大小:使用
Sqoop时设置--split-by参数均匀分配任务。 - 关闭事务:导入前执行
SET autocommit=1;。 - 预分区:按业务维度(如日期)分区导入,减少单次负载。
可视化刷新延迟
- 增量同步:通过
Sqoop或Canal实现Hive→MySQL的增量更新。 - 视图层优化:在MySQL端创建物化视图,聚合常用指标。
相关问答FAQs
Q1:如何验证Hive到MySQL的数据一致性?
A1:可通过以下步骤校验:
- 在Hive和MySQL分别执行
COUNT()对比行数。 - 抽样比对关键字段(如
MD5(CONCAT(field1, field2)))。 - 使用工具(如Apache Griffin)进行数据质量稽核。
Q2:可视化工具连接MySQL时提示“权限不足”?
A2:解决方法:
- 检查MySQL用户权限:确保用户有
SELECT权限。GRANT SELECT ON database. TO 'user'@'host';
- 确认网络连通性:防火墙需开放MySQL端口(默认3306)。
- 测试JDBC连接:通过DBeaver等工具验证连接字符串。