上一篇
hive网络教程
Hive是Hadoop数据仓库工具,支持SQL查询与数据分析,适用于ETL处理,学习需掌握DDL/DML语法、函数及调优,推荐官方文档与实战案例结合
Hive网络教程:从入门到实战的完整指南
Hive是基于Hadoop的数据仓库工具,专为大规模数据存储和分析设计,它通过类SQL语法(HiveQL)简化了对分布式数据的查询操作,广泛应用于数据分析、ETL流程和机器学习等领域,本文将从基础概念到实战应用,系统讲解Hive的核心功能与网络相关操作。
Hive核心概念与架构
| 特性 | 说明 |
|---|---|
| 数据存储 | 依赖HDFS存储数据,支持文本、ORC、Parquet等格式 |
| 计算模型 | 基于MapReduce或Tez/Spark引擎执行查询 |
| Schema on Read | 数据写入时无严格模式,读取时按需求定义表结构 |
| 分区与桶 | 分区(Partition)按字段划分数据目录,桶(Bucket)哈希分片提升查询效率 |
架构组成:
- Metastore:元数据服务,存储表结构、分区信息(通常用MySQL/PostgreSQL)。
- Driver:解析HiveQL,生成执行计划。
- Execution Engine:调用MapReduce/Tez/Spark执行任务。
- Client:Beeline、Hive CLI或JDBC/ODBC接口。
Hive环境搭建与配置
前置条件
- Hadoop集群(HDFS + YARN)
- Java 8+、Maven(可选)
- MySQL(用于Metastore)
安装步骤
# 1. 下载Hive二进制包 wget https://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz tar -xzf apache-hive-3.1.2-bin.tar.gz cd apache-hive-3.1.2-bin # 2. 配置环境变量 export HIVE_HOME=/path/to/hive export PATH=$PATH:$HIVE_HOME/bin # 3. 初始化Metastore数据库 mysql -u root -p -e "CREATE DATABASE hive;" # 修改 hive-site.xml: <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>your_password</value> </property> # 4. 启动Hive Metastore服务 schematool -initSchema -dbType mysql hive --service metastore &
集成Hadoop
修改 hive-site.xml,配置HDFS路径:
<property> <name>hive.exec.scratchdir</name> <value>/user/hive/warehouse</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://namenode:8020</value> </property>
HiveQL基础语法与操作
创建表

CREATE TABLE user_logs ( id BIGINT, name STRING, log_time TIMESTAMP, action STRING ) PARTITIONED BY (dt STRING) STORED AS ORC;
动态分区插入
INSERT INTO TABLE user_logs PARTITION(dt) SELECT id, name, log_time, action, DATE_FORMAT(log_time, 'yyyy-MM-dd') AS dt FROM staging_logs;
复杂查询示例
-统计每日用户行为次数 SELECT dt, action, COUNT() AS cnt FROM user_logs WHERE log_time BETWEEN '2023-01-01' AND '2023-01-07' GROUP BY dt, action ORDER BY dt DESC;
常用函数
| 函数 | 用途 | 示例 |
|——————-|——————————|———————————–|
| UNIX_TIMESTAMP() | 时间戳转换 | SELECT UNIX_TIMESTAMP('2023-01-01') |
| REGEXP_EXTRACT() | 正则提取字段 | REGEXP_EXTRACT(url, 'id=([^&])', 1) |
| COLLECT_LIST() | 分组聚合(UDAF) | SELECT COLLECT_LIST(action) FROM user_logs GROUP BY dt |
Hive网络数据实战
场景:分析Nginx访问日志
数据准备
假设日志格式为:168.1.1 [10/Oct/2023:13:55:36] "GET /index.html HTTP/1.1" 200 1024
创建表
CREATE TABLE nginx_logs ( ip STRING, time_local STRING, request STRING, status INT, size INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LINES TERMINATED BY ' ' STORED AS TEXTFILE;
加载数据
hdfs dfs -put /local/nginx/logs/access.log /user/hive/nginx_logs/
查询示例
-统计每小时请求量 SELECT date_format(from_unixtime(unix_timestamp(time_local, 'dd/MMM/yyyy:HH:mm:ss')), 'yyyy-MM-dd HH') AS hour, COUNT() AS requests FROM nginx_logs GROUP BY hour ORDER BY hour;
Hive优化策略
| 优化方向 | 具体措施 |
|---|---|
| 数据存储 | 使用ORC/Parquet格式压缩,开启BloomFilter减少IO |
| 查询执行 | 启用Tez/Spark引擎,设置hive.exec.parallel为true并行执行 |
| 资源配置 | 调整mapreduce.reduce.memory.mb和yarn.nodemanager.vmem-pmem-ratio |
| SQL优化 | 避免全表扫描,使用分区剪裁(Partition Pruning) |
常见问题与解决方案
Metastore连接失败
- 原因:MySQL服务未启动或权限不足。
- 解决:检查MySQL状态,确认
hive用户有SELECT/INSERT/UPDATE权限。
查询超时或OOM
- 原因:数据量过大或资源分配不足。
- 解决:
- 增加YARN内存配额:
yarn.nodemanager.resource.memory-mb。 - 启用
hive.auto.convert.join自动转MapJoin。
- 增加YARN内存配额:
FAQs
Q1:Hive与Impala/Presto有什么区别?
A1:Hive适合离线批处理,依赖MapReduce/Tez/Spark,支持复杂事务;Impala/Presto为实时交互引擎,直接查询数据无需中间落盘,但功能相对简单。
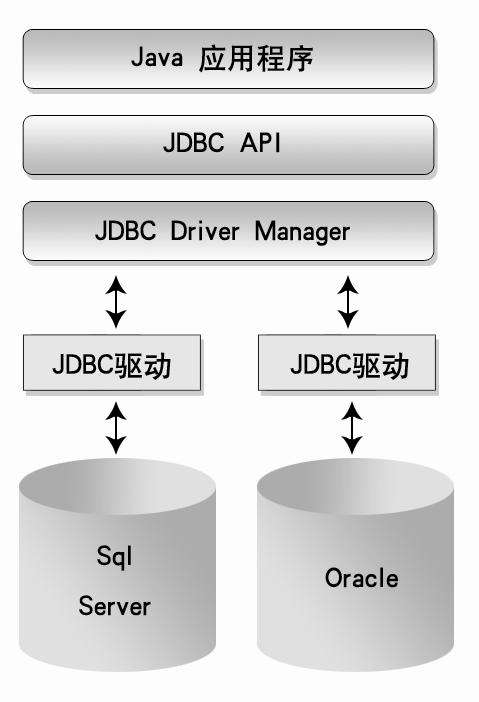
Q2:如何通过JDBC连接Hive?
A2:
- 添加Hive JDBC驱动(
hive-jdbc-.jar)。 - 使用URL连接:
jdbc:hive2://<metastore_host>:<port>/default;user=<username>;password=<password>。 - 示例代码(Java):
Connection conn = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "admin", ""); Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("SELECT FROM